python 数据聚合与分组
前面讲完了字符处理,但对数据进行整体性的聚合运算以及分组操作也是数据分析的重要内容。
通过数据的聚合与分组,我们能更容易的发现隐藏在数据中的规律。
数据分组
数据的分组核心思想是:拆分-组织-合并
首先,我们了解下groupby这个函数
import numpy as np
import pandas as pd
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9]})
print(data)
结果为:
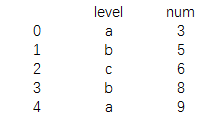
combine=data['num'].groupby(data['level'])
print(combine.mean())
结果为:

这里是以level为关键字对num进行分组,然后求平均值。当然groupby中也可以放入多个分组,用逗号隔开
print(combine.size())
结果为:

返回每个分组的频率
另外,我们也可以根据数据的所属类型对进行分组
combine=data.groupby(data.dtypes,axis=1)
print(dict(list(combine)))
结果为:

这里combine的是Serise数据结构,需要转换线转换为列表,再转成字典的形式才能打印。
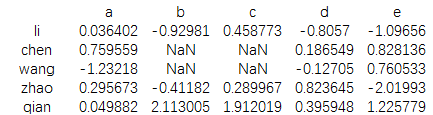
data=pd.DataFrame(np.random.randn(5,5),
index=['li','chen','wang','zhao','qian'],
columns=['a','b','c','d','e'])
print(data)
结果为:
data.ix[1:3,['b','c']]=np.nan
map={'a':'ss','b':'kk','c':'ss','d':'kk','e':'kk'}
print(data.groupby(map,axis=1).sum())
结果为:
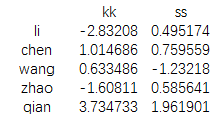
这里map是我们手工创造的字典,然后我们根据字典的对应表对data数据的行进行分组求和。
数据聚合
在各计算机语言中,聚合函数几乎都差不多,下面我们来看下python中的聚合函数
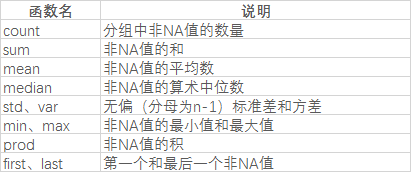
当然,我们也可以通过自定义函数来扩展方法。
跟上面直接在数据后面加聚合函数方法略有不同,聚合函数这里也可以传入agg或aggregate中
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9]})
newdata=data.groupby('level')
print(newdata.agg('mean'))
结果为:

print(newdata.agg(['mean','sum','std']))
也可以多个聚合函数一起使用:
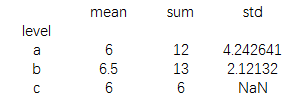
还能用字典的形式进行聚合运算
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
newdata=data.groupby('level')
print(newdata.agg({'num':'mean','num1':'sum'}))
结果为:

接下来我们了解下transform
data=pd.DataFrame(np.random.randn(5,5),
index=['li','chen','wang','zhao','qian'],
columns=['a','b','c','d','e'])
key=['ss','kk','kk','ss','ss']
print(data.groupby(key).mean())
结果为

正常求均值之后,会独立形成一个dataframe
print(data.groupby(key).transform(np.mean))
结果为:
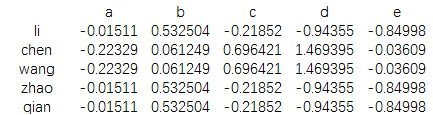
而在使用transform时,在直接在原来的数据格式下形成新的均值表
这个过程中,经历了数据的拆分,求均值,然后再合并
接下来我们看下更强大的apply
之所以说apply的强大在于,可以我们通过自定义函数,实现我们任何想要的形式对数据进行聚合运算,
但这也是apply相对而言较难的地方,关键点在于如何构造自定义函数。
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
def fun(data):
return data.groupby('level').agg(['mean','sum'])
print(data)
结果为:

print(data.groupby('level').apply(fun))
结果为:

最后,在数据分析中,我们经常要用到的一个excel功能是数据透视表,这对我们观察数据规律十分有帮助,
在python中也可以通过pivot_table实现数据透视功能
data=pd.DataFrame({'level':['a','b','c','b','a'],
'key':['one','two','one','two','one'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
print(data)
结果为:

print(data.pivot_table(index='key',columns='level'))
结果为:
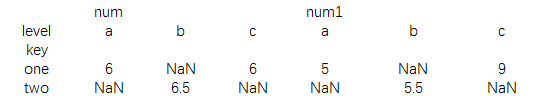
当然只有你调整参数内容就可以像excel中随心所欲的变化行列位置,这里的计数结果默认为均值,用其他聚合函数可以通过aggfunc参数进行设置。
另外还有一个用于计算分组频率的cosstab,使用方法比pivot_table要简单些,形式也类似于execl的数据透视表功能。
print(pd.crosstab(data.key,data.level,margins=True))
结果为
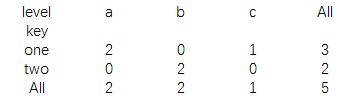
python 数据聚合与分组的更多相关文章
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- Python数据聚合和分组运算(2)-Data Aggregation
在上一篇博客里我们讲解了在python里运用pandas对数据进行分组,这篇博客将接着讲解对分组后的数据进行聚合. 1.python 中经过优化的groupy方法 先读入本文要使用的数据集tips. ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- Python之数据聚合与分组运算
Python之数据聚合与分组运算 1. 关系型数据库方便对数据进行连接.过滤.转换和聚合. 2. Hadley Wickham创建了用于表示分组运算术语"split-apply-combin ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
- 《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)
http://www.cnblogs.com/batteryhp/p/5046450.html 对数据进行分组并对各组应用一个函数,是数据分析的重要环节.数据准备好之后,通常的任务就是计算分组统计或生 ...
- 利用python进行数据分析之数据聚合和分组运算
对数据集进行分组并对各分组应用函数是数据分析中的重要环节. group by技术 pandas对象中的数据会根据你所提供的一个或多个键被拆分为多组,拆分操作是在对象的特定轴上执行的,然后将一个函数应用 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
随机推荐
- idea中output log4j中文乱码
1.设置tomcat中的VM optins:-Dfile.encofing=UTF-8 2.idea安装目录bin文件夹中idea.exe.vmoptions.idea64.exe.vmoptions ...
- Scala + Play + Sbt + Protractor
Scala + Play + Sbt + Protractor = One Build 欢迎关注我的新博客地址:http://cuipengfei.me/ 我所在的项目的技术栈选用的是Play fra ...
- C# 4.0 Parallel
C# 4.0 并行计算部分 沿用微软的写法,System.Threading.Tasks.::.Parallel类,提供对并行循环和区域的支持. 我们会用到的方法有For,ForEach,Invo ...
- CEGUI添加自定义控件
用CEGUI做界面将近3个月了,比较忙,而且自己懒了许多,没能像以前那样抽出大量时间研究CEGUI,查阅更多的资料书籍,只是在工作间隙,将官网上的一些资料和同事推荐的<CEGUI深入解析> ...
- Step one : 熟悉Unix/Linux Shell 常见命令行 (一)
1.文件系统结构和基本操作 ls - - list directory contents -a/A 列出全部文件(包含隐藏文件) - i 列出inode号码 -n 查看UID and GID -d ...
- c#中关于String、string,Object、object,Int32、int
在java中,string和String有着明显的区别,后者就是前者的一个封装.在c#中,好像是通用的,大部分情况下,两者互换并不会产生问题.今天特意查了一下资料,了解了一下两者的关系. 简单的讲,S ...
- iOS基础 - Modal制作控制器
1.modal 1.modal推出控制器的代码 2.modal关闭当前控制器的代码 3.modal推出的动画效果 4.modal在ipad中应用 2.如何给控制器加上导航栏 3.modal和导航控制器 ...
- node-webkit入门
node-webkit入门 一.简介 node-webkit 是一个基于chromium与node.js的应用程序运行器,它允许开发者使用web技术编写桌面程序.通过Node.js和WebKit技 ...
- Redis安装介绍
Redis安装介绍 一.Linux版本及配置 1. Linux版本:Red Hat Enterprise Linux 6虚拟机 2. 配置: 内存:1G:CPU:1核:硬盘:20G 二.Redis ...
- Define Constraints That Are Minimal and Sufficient 设定不多不少的约束
Define Constraints That Are Minimal and Sufficient 设定不多不少的约束 今天第二章第二节. 主管不在,然后暂时没什么任务,把第二节看了,然后整理一 ...