搜索评价指标——NDCG
◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:https://www.cnblogs.com/by-dream/p/9403984.html
概念
NDCG,Normalized Discounted cumulative gain 直接翻译为归一化折损累计增益,可能有些晦涩,没关系下面重点来解释一下这个评价指标。这个指标通常是用来衡量和评价搜索结果算法(注意这里维基百科中提到了还有推荐算法,但是我个人觉得不太适合推荐算法,后面我会给我出我的解释)。DCG的两个思想:
1、高关联度的结果比一般关联度的结果更影响最终的指标得分;
2、有高关联度的结果出现在更靠前的位置的时候,指标会越高;
累计增益(CG)
CG,cumulative gain,是DCG的前身,只考虑到了相关性的关联程度,没有考虑到位置的因素。它是一个搜素结果相关性分数的总和。指定位置p上的CG为:

reli 代表i这个位置上的相关度。
举例:假设搜索“篮球”结果,最理想的结果是:B1、B2、 B3。而出现的结果是 B3、B1、B2的话,CG的值是没有变化的,因此需要下面的DCG。
折损累计增益(DCG)
DCG, Discounted 的CG,就是在每一个CG的结果上处以一个折损值,为什么要这么做呢?目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低。到第i个位置的时候,它的价值是 1/log2(i+1),那么第i个结果产生的效益就是 reli * 1/log2(i+1),所以:

当然还有一种比较常用的公式,用来增加相关度影响比重的DCG计算方式是:

百科中写到后一种更多用于工业。当然相关性值为二进制时,即 reli在{0,1},二者结果是一样的。当然CG相关性不止是两个,可以是实数的形式。
归一化折损累计增益(NDCG)
NDCG, Normalized 的DCG,由于搜索结果随着检索词的不同,返回的数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是处以IDCG。
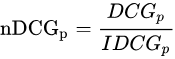
IDCG为理想情况下最大的DCG值。
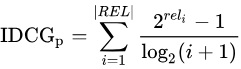
其中 |REL| 表示,结果按照相关性从大到小的顺序排序,取前p个结果组成的集合。也就是按照最优的方式对结果进行排序。
实际的例子
假设搜索回来的5个结果,其相关性分数分别是 3、2、3、0、1、2
那么 CG = 3+2+3+0+1+2
可以看到只是对相关的分数进行了一个关联的打分,并没有召回的所在位置对排序结果评分对影响。而我们看DCG:
| i | reli | log2(i+1) | reli /log2(i+1) |
| 1 | 3 | 1 | 3 |
| 2 | 2 | 1.58 | 1.26 |
| 3 | 3 | 2 | 1.5 |
| 4 | 0 | 2.32 | 0 |
| 5 | 1 | 2.58 | 0.38 |
| 6 | 2 | 2.8 | 0.71 |
所以 DCG = 3+1.26+1.5+0+0.38+0.71 = 6.86
接下来我们归一化,归一化需要先结算 IDCG,假如我们实际召回了8个物品,除了上面的6个,还有两个结果,假设第7个相关性为3,第8个相关性为0。那么在理想情况下的相关性分数排序应该是:3、3、3、2、2、1、0、0。计算IDCG@6:
| i | reli | log2(i+1) | reli /log2(i+1) |
| 1 | 3 | 1 | 3 |
| 2 | 3 | 1.58 | 1.89 |
| 3 | 3 | 2 | 1.5 |
| 4 | 2 | 2.32 | 0.86 |
| 5 | 2 | 2.58 | 0.77 |
| 6 | 1 | 2.8 | 0.35 |
所以IDCG = 3+1.89+1.5+0.86+0.77+0.35 = 8.37
so 最终 NDCG@6 = 6.86/8.37 = 81.96%
搜索评价指标——NDCG的更多相关文章
- 搜索排序的评价指标NDCG
refer: https://www.cnblogs.com/by-dream/p/9403984.html Out1 = SELECT QueryId, DocId, Rating, ROW_NUM ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- IR的评价指标-MAP,NDCG和MRR
IR的评价指标-MAP,NDCG和MRR MAP(Mean Average Precision): 单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值.主集合的平均准确率(MAP)是每个主 ...
- (转)Learning to Rank for IR的评价指标—MAP,NDCG,MRR
转自:http://www.cnblogs.com/eyeszjwang/articles/2368087.html MAP(Mean Average Precision):单个主题的平均准确率是每篇 ...
- IR的评价指标—MAP,NDCG,MRR
http://www.cnblogs.com/eyeszjwang/articles/2368087.html MAP(Mean Average Precision):单个主题的平均准确率是每篇相关文 ...
- [LTR] 信息检索评价指标(RP/MAP/DCG/NDCG/RR/ERR)
一.RP R(recall)表示召回率.查全率,指查询返回结果中相关文档占所有相关文档的比例:P(precision)表示准确率.精度,指查询返回结果中相关文档占所有查询结果文档的比例: 则 PR 曲 ...
- Learning to Rank for IR的评价指标—MAP,NDCG,MRR
转自: https://www.cnblogs.com/eyeszjwang/articles/2368087.html MAP(Mean Average Precision):单个主题的平均准确率是 ...
- 推荐系统排序(Ranking)评价指标
一.准确率(Precision)和召回率(Recall) (令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表.) 对用户u推荐N个物品(记为R(u) ...
- 搜索系统核心技术概述【1.5w字长文】
前排提示:本文为综述性文章,梳理搜索相关技术,如寻求前沿应用可简读或略过 搜索引擎介绍 搜索引擎(Search Engine),狭义来讲是基于软件技术开发的互联网数据查询系统,用户通过搜索引擎查询所需 ...
随机推荐
- C# string[]转List<string>
List<string> ltProduct = new List<string>(Product.Split('|'));
- sliva数据库简介--转载
sliva rRNA数据库(http://www.arb-silva.de/)用来检查和比对RNA序列,既可以针对16S/18S,SSU,也可以针对23S/28S, LSU,包括了Bacteria, ...
- 基于MySQl的分页显示
<%@page import="java.sql.DriverManager"%> <%@page import="java.sql.ResultSet ...
- spoj TBATTLE 质因数分解+二分
题目链接:点击传送 TBATTLE - Thor vs Frost Giants #number-theory #sliding-window-1 Thor is caught up in a fie ...
- python 无序表查找
def sequential_search(lis, key): for i in range(len(lis)): if(lis[i] == key): return i else: return ...
- Springboot 学习遇到的一些错和埋坑之旅
1. java.lang.IllegalStateException: Unable to find a @SpringBootConfiguration, you need to use @Cont ...
- windows下的mongodb安装(真垃圾)
一.下载 3.6下载安装会卡死.只能下3.4的.http://downloads.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-v3.4-la ...
- 检验二叉树序列化的合理性 Verify Preorder Serialization of a Binary Tree
2018-07-31 17:47:13 问题描述: 问题求解: 本题要求在不构建二叉树的情况下对先序遍历生成的序列化字符串进行合法性验证,这里有个技巧性较强的验证方法,就是采用当前可用的指针数目进行验 ...
- Symbol的控件模板
<esriSymbols:TextSymbol x:Name="text1" Text="adadfdf"></esriSymbols:Tex ...
- Android设计模式之工厂模式
定义 工厂模式是我们最常用的实例化对象模式了,是用工厂方法代替new操作的一种模式.著名的Jive论坛 ,就大量使用了工厂模式,工厂模式在Java程序系统可以说是随处可见.因为工厂模式就相当于创建实例 ...