论文笔记——DenseNet
《Densely Connected Convolutional Networks》阅读笔记
代码地址:https://github.com/liuzhuang13/DenseNet
首先看一张图:
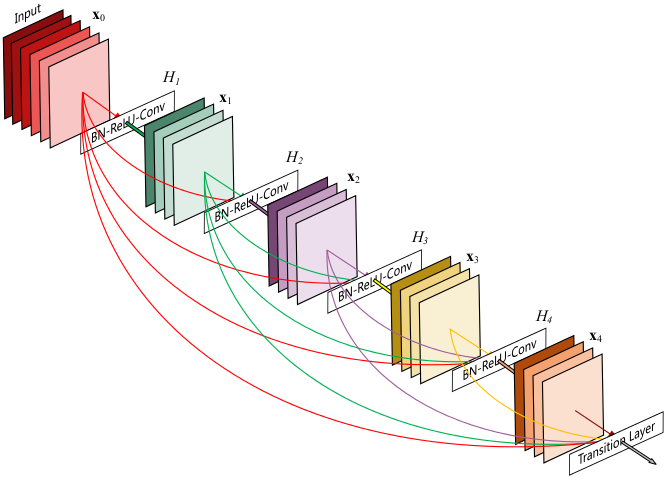
稠密连接:每层以之前层的输出为输入,对于有L层的传统网络,一共有L个连接,对于DenseNet,则有L(L+1)2。
这篇论文主要参考了Highway Networks,Residual Networks (ResNets)以及GoogLeNet,通过加深网络结构,提升分类结果。加深网络结构首先需要解决的是梯度消失问题,解决方案是:尽量缩短前层和后层之间的连接。比如上图中,H4层可以直接用到原始输入信息X0,同时还用到了之前层对X0处理后的信息,这样能够最大化信息的流动。反向传播过程中,X0的梯度信息包含了损失函数直接对X0的导数,有利于梯度传播。
DenseNet有如下优点:
1.有效解决梯度消失问题
2.强化特征传播
3.支持特征重用
4.大幅度减少参数数量
接着说下论文中一直提到的Identity function:
很简单 就是输出等于输入f(x)=x
传统的前馈网络结构可以看成处理网络状态(特征图?)的算法,状态从层之间传递,每个层从之前层读入状态,然后写入之后层,可能会改变状态,也会保持传递不变的信息。ResNet是通过Identity transformations来明确传递这种不变信息。
网络结构:

每层实现了一组非线性变换Hl(.),可以是Batch Normalization (BN) ,rectified linear units (ReLU) , Pooling , or Convolution (Conv). 第l层的输出为xl。
对于ResNet:
xl=Hl(xl−1)+xl−1
这样做的好处是the gradient flows directly through the identity function from later layers to the earlier layers.
同时呢,由于identity function 和 H的输出通过相加的方式结合,会妨碍信息在整个网络的传播。
受GooLeNet的启发,DenseNet通过串联的方式结合:
xl=Hl([x0,x1,...,xl−1])
这里Hl(.)是一个Composite function,是三个操作的组合:BN−>ReLU−>Conv(3×3)
由于串联操作要求特征图x0,x1,...,xl−1大小一致,而Pooling操作会改变特征图的大小,又不可或缺,于是就有了上图中的分块想法,其实这个想法类似于VGG模型中的“卷积栈”的做法。论文中称每个块为DenseBlock。每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成。
Growth rate:由于每个层的输入是所有之前层输出的连接,因此每个层的输出不需要像传统网络一样多。这里Hl(.)的输出的特征图的数量都为k,k即为Growth Rate,用来控制网络的“宽度”(特征图的通道数).比如说第l层有k(l−1)+k0的输入特征图,k0是输入图片的通道数。
虽然说每个层只产生k个输出,但是后面层的输入依然会很多,因此引入了Bottleneck layers 。本质上是引入1x1的卷积层来减少输入的数量,Hl的具体表示如下
BN−>ReLU−>Conv(1×1)−>BN−>ReLU−>Conv(3×3)
文中将带有Bottleneck layers的网络结构称为DenseNet-B。
除了在DenseBlock内部减少特征图的数量,还可以在transition layers中来进一步Compression。如果一个DenseNet有m个特征图的输出,则transition layer产生 ⌊θm⌋个输出,其中0<θ≤1。对于含有该操作的网络结构称为DenseNet-C。
同时包含Bottleneck layer和Compression的网络结构为DenseNet-BC。
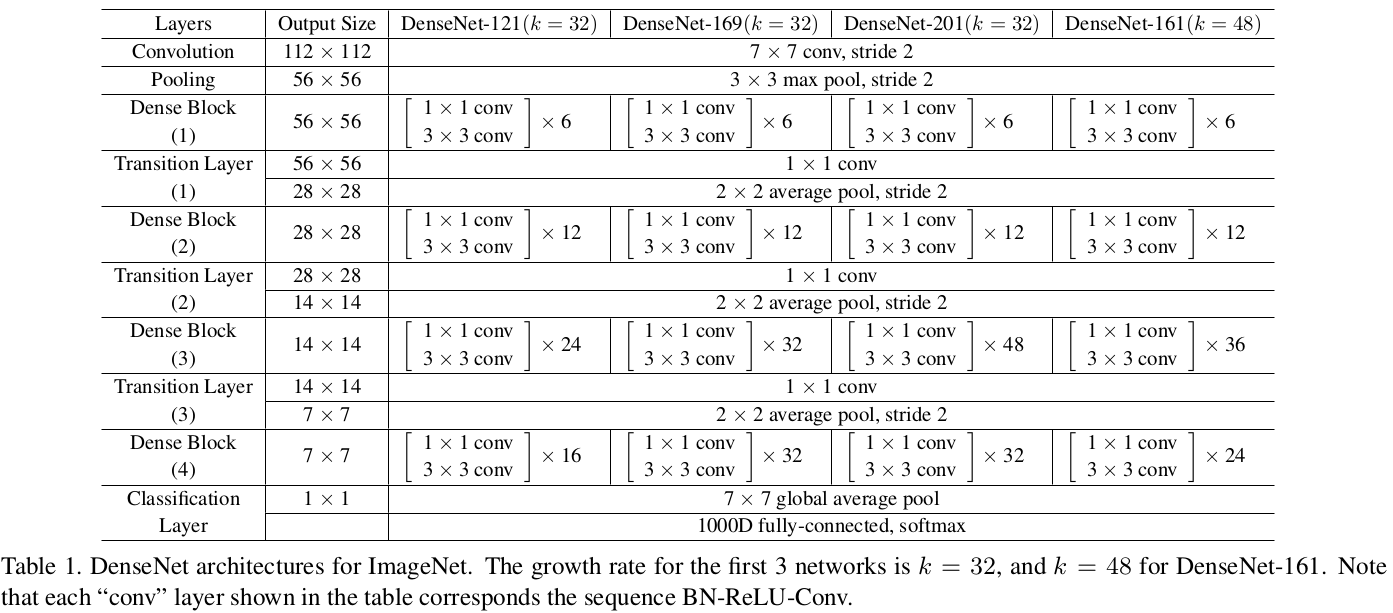
具体的网络结构:
实验以及一些结论
在CIFAR和SVHN上的分类结果(错误率):
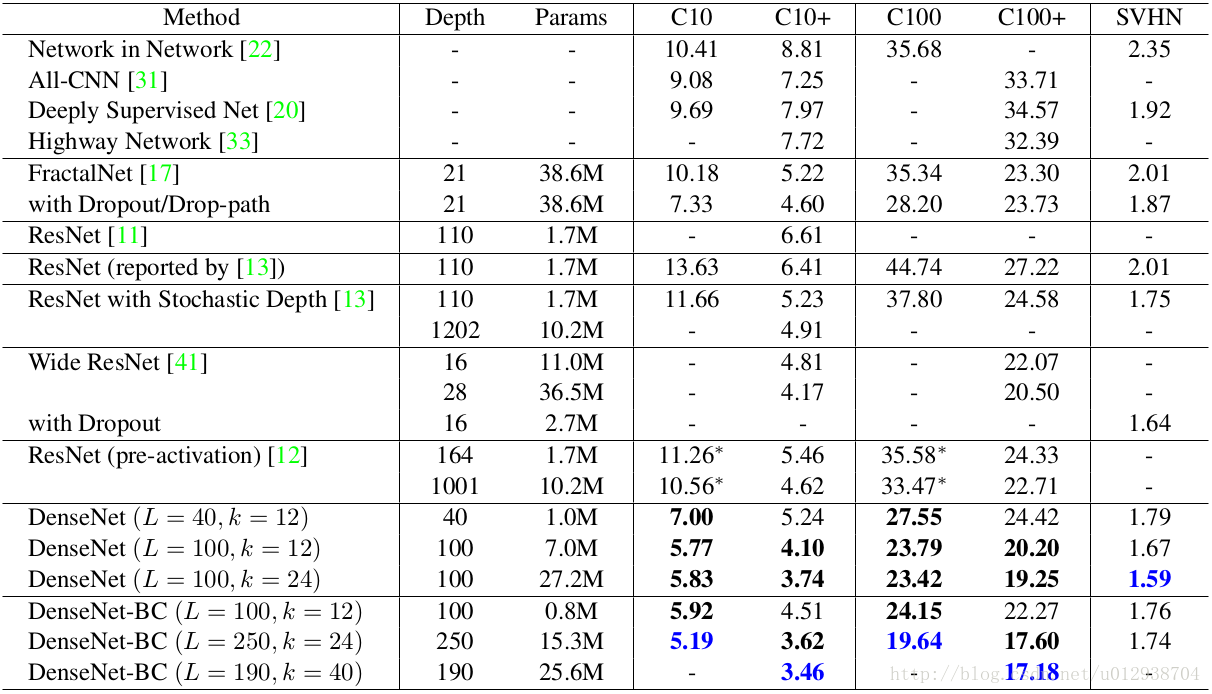
L表示网络深度,k为增长率。蓝色字体表示最优结果,+表示对原数据库进行data augmentation。可以发现DenseNet相比ResNet可以取得更低的错误率,并且使用了更少的参数。
接着看一组对比图:
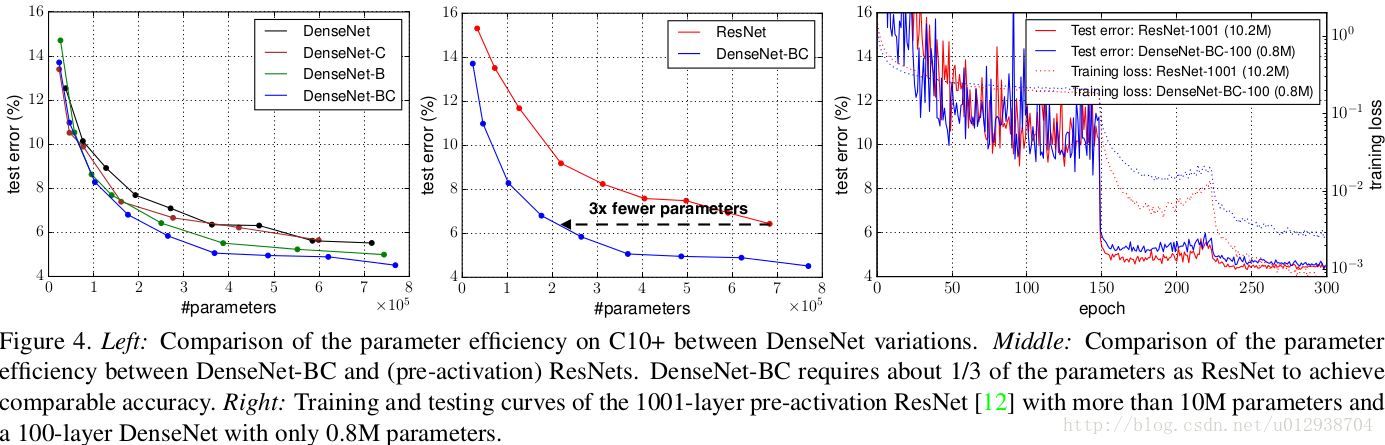
前两组描述分类错误率与参数量的对比,从第二幅可以看出,在取得相同分类精度的情况下,DenseNet-BC比ResNet少了23的参数。第三幅图描述含有10M参数的1001层的ResNet与只有0.8M的100层的DenseNet的训练曲线图。可以发现ResNet可以收敛到更小的loss值,但是最终的test error与DenseNet相差无几。再次说明了DenseNet参数效率(Parameter Efficiency)很高!
同样的在ImageNet上的分类结果:
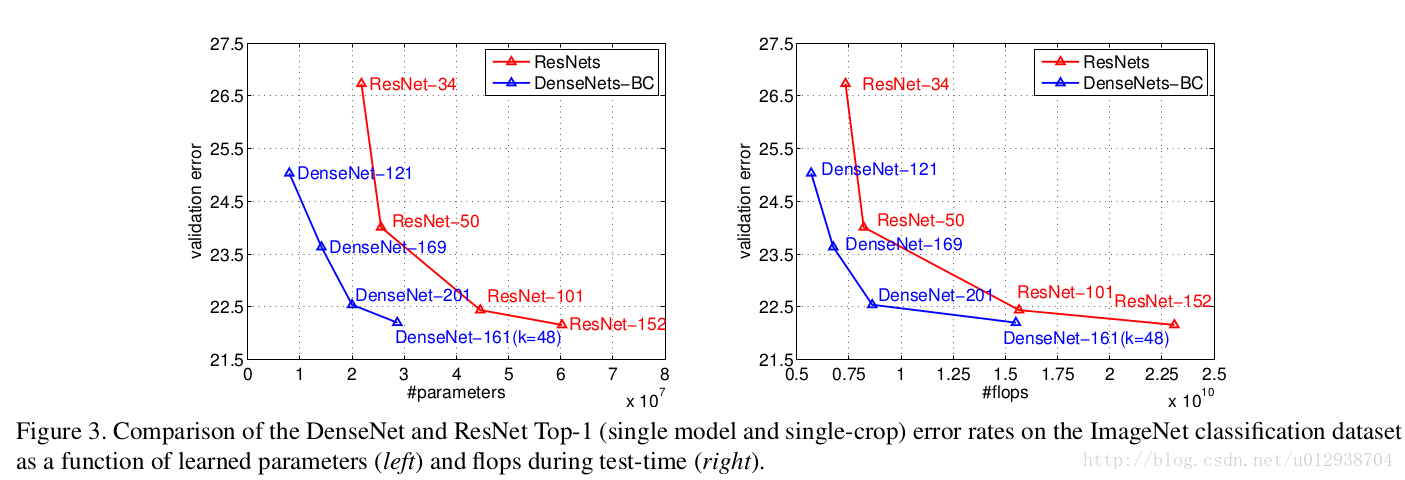
右图使用FLOPS来说明计算量。通过比较ResNet-50,DenseNet-201,ResNet-101,说明计算量方面,DenseNet结果更好。
转至:http://blog.csdn.net/u012938704/article/details/53468483
论文笔记——DenseNet的更多相关文章
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
随机推荐
- 解决PHPStorm经常卡顿现象 调整内存限制
https://www.jisec.com/other/451.html 为什么调整内存? 最近发现PHPstorm在打开一些大点的js, html文件时,会非常的卡顿,这个主要的原因是因为设置的内存 ...
- PAT 1026 Table Tennis[比较难]
1026 Table Tennis (30)(30 分) A table tennis club has N tables available to the public. The tables ar ...
- svn 常见问题记录
One or more files are in a conflicted state 情景:A组员新增文件并提交,B组员更新出现如下图情况. 解决方案:直接拷贝到B组员工作区.
- [LeetCode] 529. Minesweeper_ Medium_ tag: BFS
Let's play the minesweeper game (Wikipedia, online game)! You are given a 2D char matrix representin ...
- Tesseract-OCR 训练过程 V3.02
软件: jTessBoxEditor Version 0.9 (30 April 2013) Tesseract-OCR win32 v3.02 with Leptonica 训练步骤: 1. ...
- 基于comet服务器推送技术(web实时聊天)
http://www.cnblogs.com/zengqinglei/archive/2013/03/31/2991189.html Comet 也称反向 Ajax 或服务器端推技术.其思想很简单:将 ...
- linux导出、导入sql
linux下导入.导出mysql数据库命令 一.导出数据库用mysqldump命令(注意mysql的安装路径,即此命令的路径): 1.导出数据和表结构: mysqldump -u用户名 -p密码 数据 ...
- 何为仿射变换(Affine Transformation)
http://www.cnblogs.com/ghj1976/p/5199086.html 变换模型是指根据待匹配图像与背景图像之间几何畸变的情况,所选择的能最佳拟合两幅图像之间变化的几何变换模型.可 ...
- Python: 反方向迭代一个序列
使用内置的reversed()函数 >>> a = [1, 2, 3, 4] >>> for x in reversed(a): ... print(x) out ...
- 制作系统U盘,不用做任何动作直接从U盘启动装系统(非PE的)
用U盘装系统可以用PE方式,进入PE系统,选择镜像文件,然后装,这种比较麻烦. 下面介绍一下从U盘启动,直接装系统的方法,这种方法从U盘启动后,不用做任何动作,就像用光盘装系统一样简单 首先要制作一下 ...