【Spark-core学习之六】 Spark资源调度和任务调度
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Spark资源调度和任务调度
1、Spark资源调度和任务调度的流程
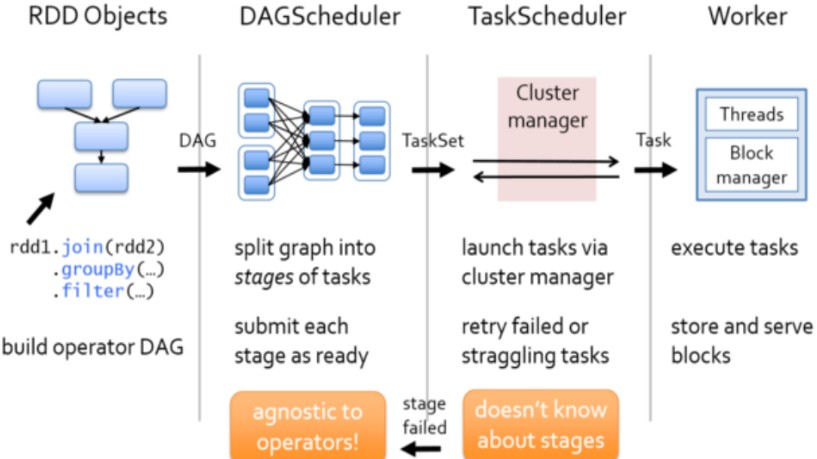
启动集群后,Worker节点会向Master节点汇报资源情况,Master掌握了集群资源情况。当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图。任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,DAGScheduler是任务调度的高层调度器,是一个对象。DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler(TaskScheduler是任务调度的低层调度器,这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务),TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)。task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了。
TaskScheduler不仅能重试失败的task,还会重试straggling(落后,缓慢)task(也就是执行速度比其他task慢太多的task)。如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过spark.speculation属性来配置。
注意:
(1) 对于ETL类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
(2)如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态。
2、图解Spark资源调度和任务调度的流程
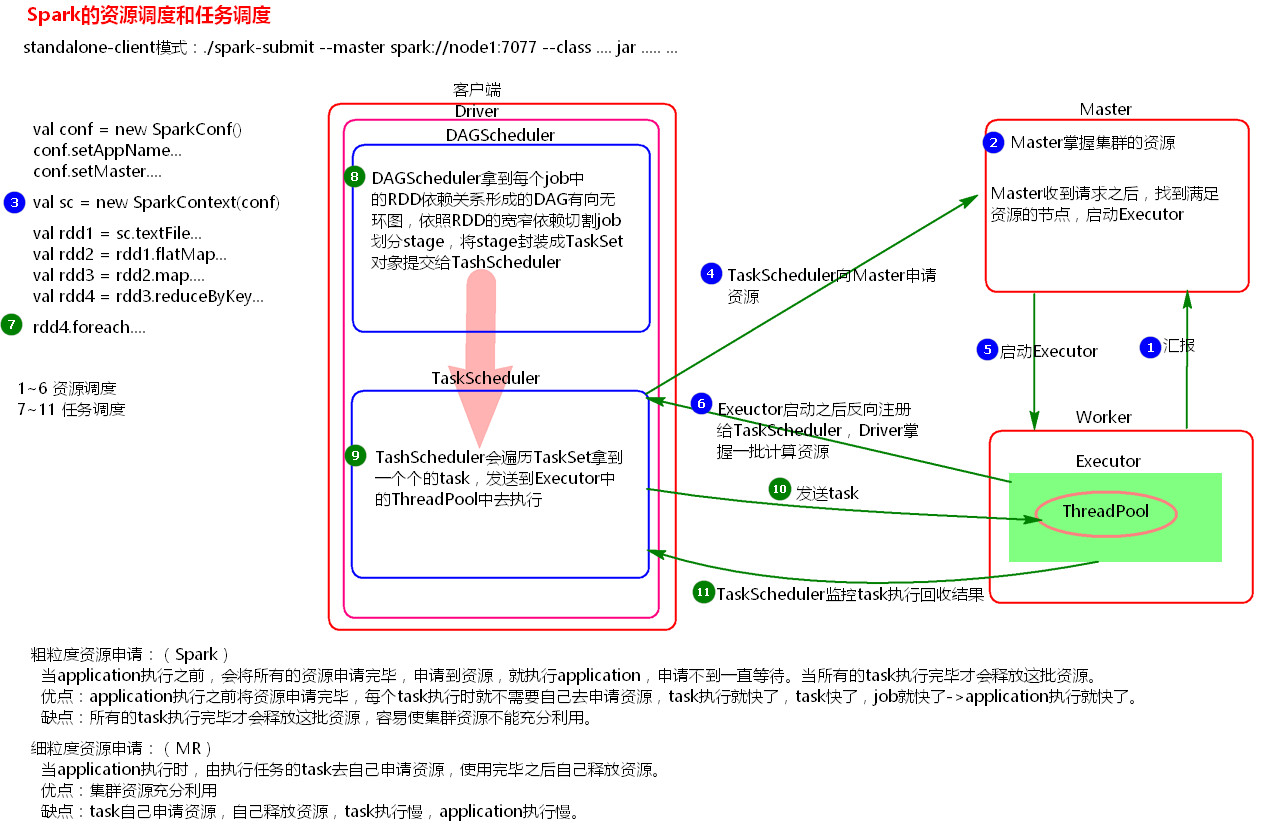
3、粗粒度资源申请和细粒度资源申请
(3.1)粗粒度资源申请(Spark)
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源。
优点:在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了。
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用。
(3.2)细粒度资源申请(MapReduce)
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
优点:集群的资源可以充分利用。
缺点:task自己去申请资源,task启动变慢,Application的运行就相应的变慢了。
二、资源调度和任务调度源码
1、资源调度
(1)资源请求简单图
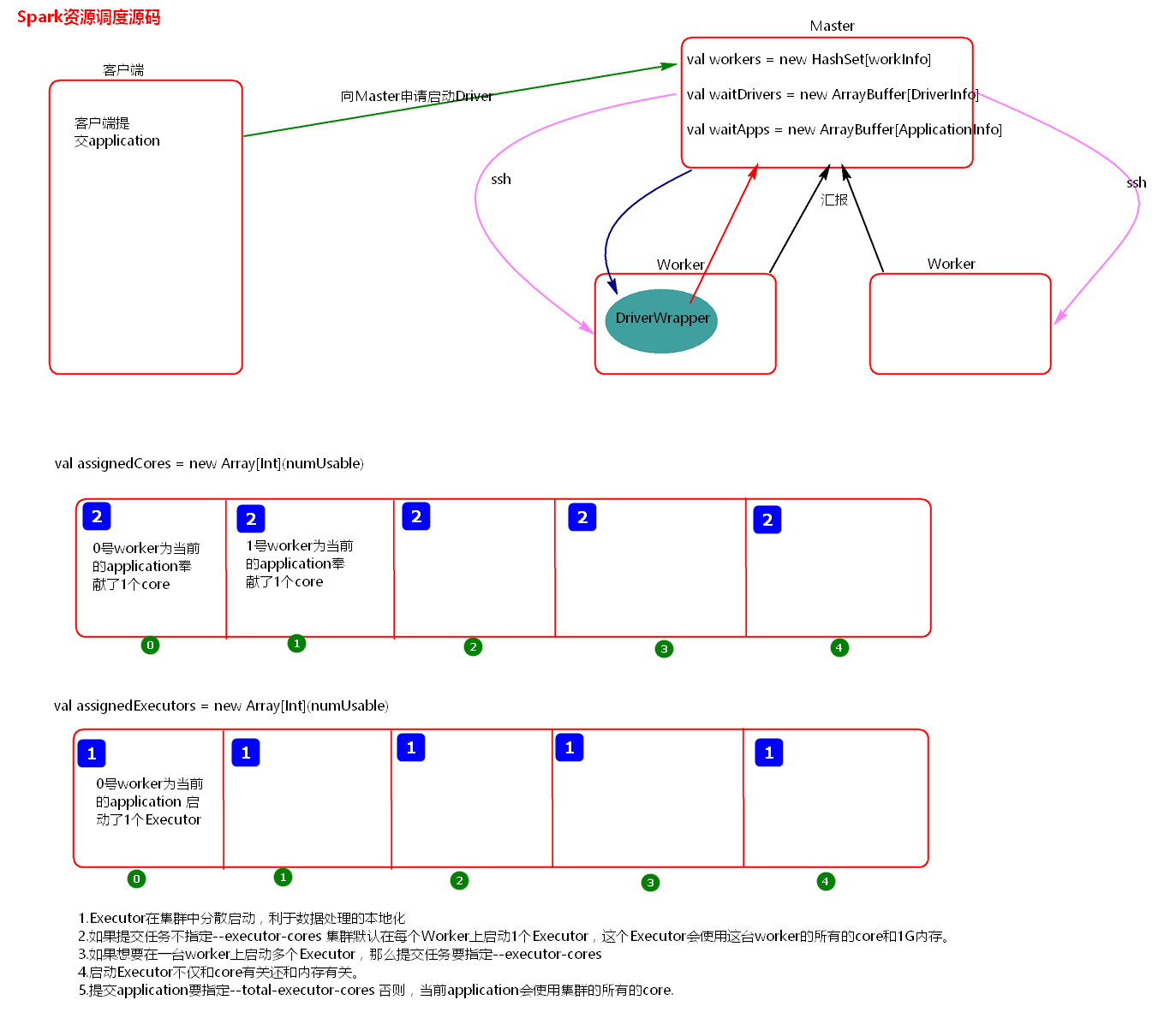
(2)资源调度Master路径:
org.apache.spark.deploy.SparkSubmit
路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/Master/Master.scala
(3)提交应用程序,submit的路径:
org.apache.spark.deploy.master.Master
路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/SparkSubmit.scala
(4)总结:
(4.1)Executor在集群中分散启动,有利于task计算的数据本地化。
(4.2)默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
(4.3)如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
(4.4)默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。
(5)结论演示
使用Spark-submit提交任务演示。也可以使用spark-shell
(5.1)默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit
--master spark://node1:7077
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.2)在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.3)内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 3g
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
(5.4)--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 2g
--total-executor-cores 3
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
2、任务调度源码分析
(1)Action算子开始分析
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。
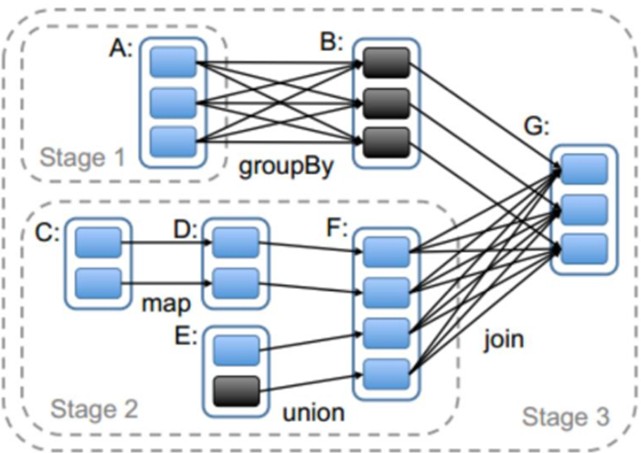
(2)划分stage,以taskSet形式提交任务
DAGScheduler 类中getMessingParentStages()方法是切割job划分stage。可以结合以下这张图来分析:
参考:
Spark
【Spark-core学习之六】 Spark资源调度和任务调度的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 大数据笔记(二十七)——Spark Core简介及安装配置
1.Spark Core: 类似MapReduce 核心:RDD 2.Spark SQL: 类似Hive,支持SQL 3.Spark Streaming:类似Storm =============== ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
随机推荐
- Nginx 反向代理获取设备真实的IP地址
package com.das.common.util; import org.apache.commons.lang3.StringUtils; import org.springframework ...
- Windows10 + IntelliJ IDEA 2017.3.2 + wamp2e + xdebug 调试 配置
一.环境 系统: windows10 WampServer: wampserver2.2e-php5.3.13-httpd2.2.22-mysql5.5.24-32b.exe IDE: Intel ...
- google的Python风格规范
Python风格规范 分号 Tip 不要在行尾加分号, 也不要用分号将两条命令放在同一行. 行长度 Tip 每行不超过80个字符 例外: 长的导入模块语句 注释里的URL 不要使用反斜杠连接行. ...
- 使用 Sublime Text 将含下划线的字符串批量替换为驼峰命名法格式的字符串
本文版权归cxun所有,如有转载请注明出处与本文链接,谢谢!原文地址:http://www.cnblogs.com/cxun/p/7762984.html For indexing: Convert ...
- HTTPS原理和CA证书申请(转)
原文地址:http://blog.51cto.com/11883699/2160032 众所周知,WEB服务存在http和https两种通信方式,http默认采用80作为通讯端口,对于传输采用不加密的 ...
- phpstorm webstorm 常用快捷键总结
1.全项目搜索 ctrl + shift + F 这个是window下的快捷键
- dbeaver导出MySQL的架构提示"IO Error: Utility 'mysqldump.exe' not found in client home 'MySQL Connector/Net"解决方案
今天想到用dbeaver的Dump dabase功能导出MySQL的架构脚本,到最后一步生成的时候提示以下错误信息: IO Error: Utility 'mysqldump.exe' not fou ...
- Timeline Storyteller 现已加入自定义图表库
前言 下载地址: https://store.office.com/en-us/app.aspx?assetid=WA104381136&sourcecorrid=328f5e2b-e973- ...
- bootstrap滚动监视原理实现
最近在公司实习,刚好写了一个静态的网页,用到了滚动监视,就自己写了个监视,话不多说直接进入正题 $(function () { var $root = $("html,body") ...
- ruby 基础知识2 - 区块 block
原文 1. block中的 yield 与遍历 5.times do |i| puts i end 或者 def my_times(n) i = 0 while n > i i += 1 yie ...