python学习笔记:深浅拷贝的使用和原理
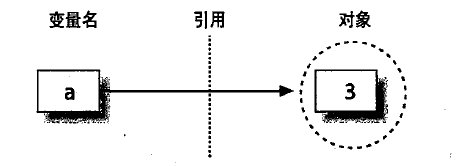

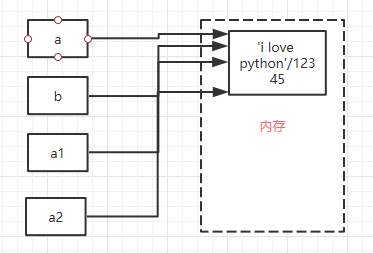
import copy
a = "i love python"
b = a
a1 = copy.copy(a)
a2 = copy.deepcopy(b)
print(id(a))
print(id(b))
print(id(a1))
print(id(a2))
#输出:
2114011486192
2114011486192
2114011486192
2114011486192
#赋值
D = {'k1':'v1','k2':123,'k3':["str1",469]}
D2 = D
print(id(D))
print(id(D2))
#输出:
2178677065032
2178677065032
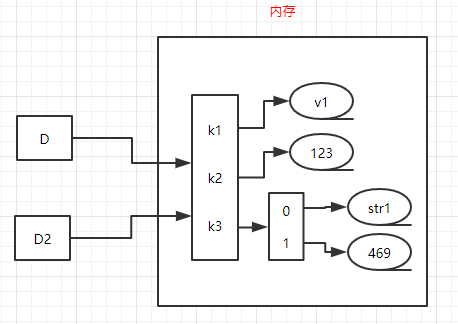
例2,浅拷贝,
#浅拷贝
D = {'k1':'v1','k2':123,'k3':["str1",469]}
D2 = copy.copy(D) #浅拷贝,额外创建第一层(变量名id改变,对象id不变,还是引用旧对象)
print(id(D))
print(id(D2))
print(id(D["k1"]))
print(id(D2["k1"]))
#输出;
1993456403784
1993456836488
1993456800856
1993456800856
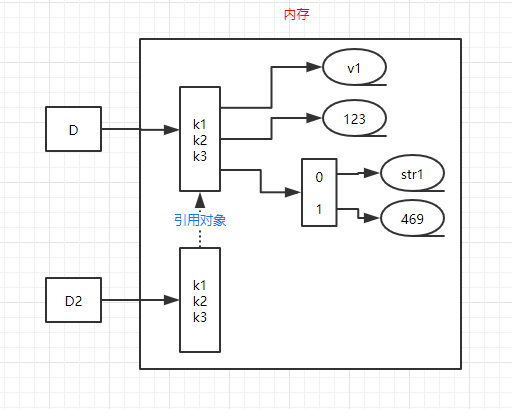
D = {'k1':'v1','k2':123,'k3':["str1",469]}
D2 = copy.deepcopy(D)
print(id(D))
print(id(D2))
print(id(D["k3"]))
print(id(D2["k3"]))
print(id(D["k3"][0]))
print(id(D2["k3"][0]))
#输出:
2129861461320
2129861875016
2129863354440
2129863327624
2129861860856
2129861860856
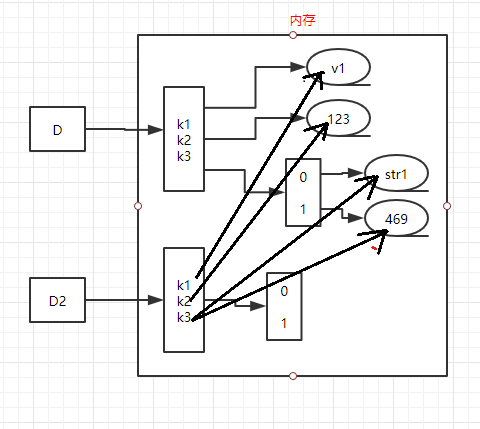
#浅拷贝,改变新字典,久字典也一起改变
dict = {"cpu":[100],"mem":[200],"disk":[300]}
new_dict = copy.copy(dict)
new_dict["cpu"][0] = 90
print(new_dict)
print(dict)
#输出:
{'cpu': [90], 'mem': [200], 'disk': [300]}
{'cpu': [90], 'mem': [200], 'disk': [300]}
#深拷贝,改变新字典,久字典没变
dict = {"cpu":[100],"mem":[200],"disk":[300]}
new_dict = copy.deepcopy(dict)
new_dict["cpu"][0] = 90
print(new_dict)
print(dict)
#输出:
{'cpu': [90], 'mem': [200], 'disk': [300]}
{'cpu': [100], 'mem': [200], 'disk': [300]}
参考:
http://www.cnblogs.com/repo/p/5425774.html
http://blog.csdn.net/jerry_1126/article/details/41852591
python学习笔记:深浅拷贝的使用和原理的更多相关文章
- Python学习(006)-深浅拷贝及集合
深浅拷贝 import copy husband=['xiaoxin',123,[200000,100000]] wife=husband.copy() #浅拷贝 wife[0]='xiaohong ...
- python学习之深浅拷贝
4.2 深浅拷贝 4.2.1 认识 首先应该知道python中变量在内存中是怎么存放的! 在python中,变量与变量的值占用不同的内存.变量占用的内存,并非直接存储数值,而存储的是值在内存中的地址. ...
- Python学习 :深浅拷贝
深浅拷贝 一.浅拷贝 只拷贝第一层数据(不可变的数据类型),并创建新的内存空间进行储蓄,例如:字符串.整型.布尔 除了字符串以及整型,复杂的数据类型都使用一个共享的内存空间,例如:列表 列表使用的是同 ...
- Python学习-列表深浅拷贝
一.先看一个简单的赋值语句 lst1 = ['France', 'Belgium', 'England'] lst2 = lst1 # lst1.append('Uruguay') lst2.appe ...
- python基础学习笔记——深浅拷贝
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 lst1 = ["⾦⽑狮王", "紫衫⻰王&qu ...
- day8 python学习 集合 深浅拷贝
1.内存地址: 字符串在20位以内,没有空格,没有特殊字符的情况下,同样的字符串内存地址是一样的 2.元组中:在只有一个值的时在后边加逗号和没有逗号的区别 t1=(1) 不加逗号这个值是什么类型就打印 ...
- python学习笔记3---浅拷贝和深拷贝,file操作
import copy a=[1,2,3,['a','b']] b=a c= copy.copy(a)---浅拷贝 d=copy.deepcopy(a)---深拷贝 file操作: python 文件 ...
- python学习day7 深浅拷贝&文件操作
4-4 day07 深浅拷贝&文件操作 .get()用法 返回指定键的值,如果值不在字典中返回默认值. info={'k1':'v1,'K2':'v2'}mes = info.get('k1' ...
- python学习笔记:*args和**kwargs使用原理?
一.*args和**kwargs原理 先看个例子: def test(*args,**kwargs): print("args =",args) print("kwarg ...
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
随机推荐
- IntelliJ IDEA 2018.3.2无法正常输入字符问题解决方案
昨天升级IDEA的版本到2018.3.2,今天打开项目发现只要在代码编辑器输入字符(英文.符号或中文等)都会立刻被强制删除,造成一个无法正常输入的现象(回车换行可以).仔细观察这种想象后发有可能是代码 ...
- python nose测试框架全面介绍十二 ----用例执行顺序打乱
在实际执行自动化测试时,发现我们的用例在使用同一个资源的操作时,用例的执行顺序对测试结果有影响,在手工测试时是完全没法覆盖的. 但每一次都是按用例名字来执行,怎么打乱来执行的. 在网上看到一个有意思的 ...
- 用vue制作饿了么首页(1)
无论是静态网页还是动态交互网页,实现原则是将他们分块,然后各个击破. 很明显的饿了么首页分为三个部分(组件), 上面的头部(商家信息), 中间路由 购物车 每部分先占住自己位置,然后挨个将这三部分分别 ...
- oracle安装教程
首先下载oracle 12c的安装包(一共有两个组成),下载完之后将两个压缩文件解压到同一个目录下 https://pan.baidu.com/s/1ydsClsHv04RAwaoGmHrFVQ ht ...
- 搭建Harbor企业级docker仓库
搭建Harbor企业级docker仓库 一.Harbor简介 1.Harbor介绍 Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如 ...
- 删除64位ODBC数据源DNS
1.按照打开管理工具-打开数据源(ODBC),进入如下界面,选择用户DSN删除,发现报错一直删除不了. 2.成功删除:进入如下图路径,打开ODBC数据源管理工具,选择要删除的DSN就可以成功删除啦.
- nginx cookie 丢失问题
- python 控制语句基础---->代码块:以为冒号作为开始,用缩进来划分作用域,代表一个整体,是一个代码块,一个文件(模块)也称为一个代码块 | 作用域:作用的范围
# ### 代码块:以为冒号作为开始,用缩进来划分作用域,代表一个整体,是一个代码块,一个文件(模块)也称为一个代码块 # ### 作用域:作用的范围 print(11) print(12) prin ...
- 【JVM】-NO.110.JVM.1 -【GC垃圾收集器】
Style:Mac Series:Java Since:2018-09-10 End:2018-09-10 Total Hours:1 Degree Of Diffculty:5 Degree Of ...
- [转]有return的情况下try catch finally的执行顺序
结论: 1.不管有没有出现异常,finally块中代码都会执行: 2.当try和catch中有return时,finally仍然会执行: 3.finally是在return后面的表达式运算后执行的(此 ...