将爬取的数据保存到mysql中
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了
安装数据库
1、pip install pymysql(根据版本来装)
2、创建数据
打开终端 键入mysql -u root -p 回车输入密码
create database scrapy (我新建的数据库名称为scrapy)
3、创建表
use scrapy;
create table xiaohua (name varchar(200) ,url varchar(100));
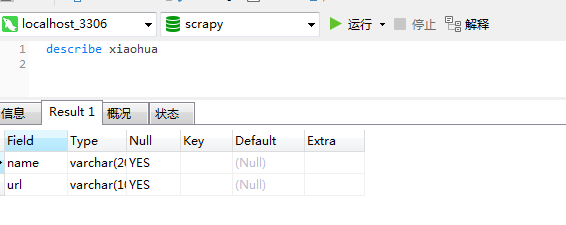
数据库部分就酱紫啦
4、编写pipeline
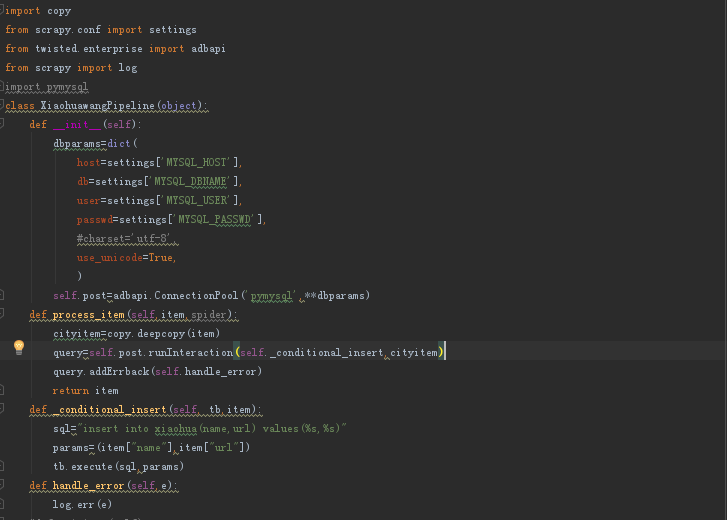
5、编写setting

6、编写spider文件
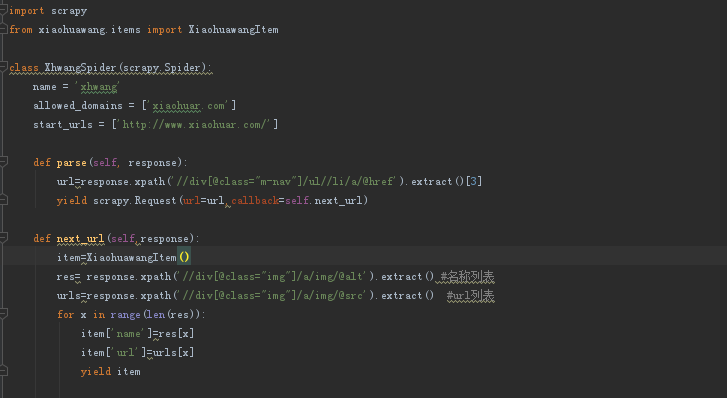
7、爬取数据保存到mysql
scrapy crawl xhwang
之前报错为2018-10-18 09:05:50 [scrapy.log] ERROR: (1241, 'Operand should contain 1 column(s)')
因为我的spider代码中是这样
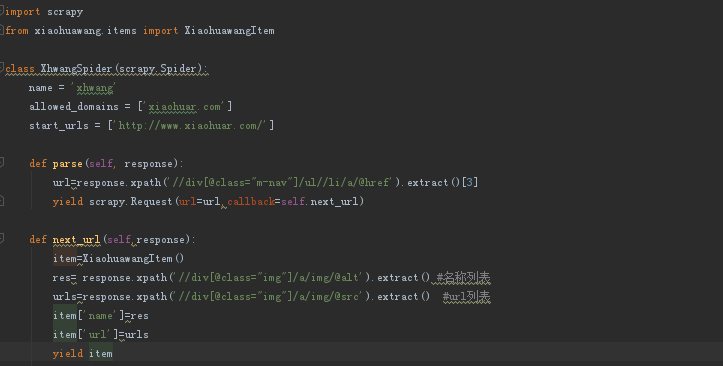
附一张网上找到的答案

错误原因:item中的结果为{'name':[xxx,xxxx,xxxx,xxx,xxxxxxx,xxxxx],'url':[yyy,yyy,yy,y,yy,y,y,y,y,]},这种类型的数据
更正为6下面代码后出现如下会有重复

然后又查了下原因终于解决问题之所在
在图上可以看出,爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据。那为什么会造成这种结果呢?
其原因是由于spider的速率比较快,scrapy操作数据库相对较慢,导致pipeline中的方法调用较慢,当一个变量正在处理的时候
一个新的变量过来,之前的变量值就会被覆盖了,解决方法是对变量进行保存,在保存的变量进行操作,通过互斥确保变量不被修改。
在pipeline中修改如下代码

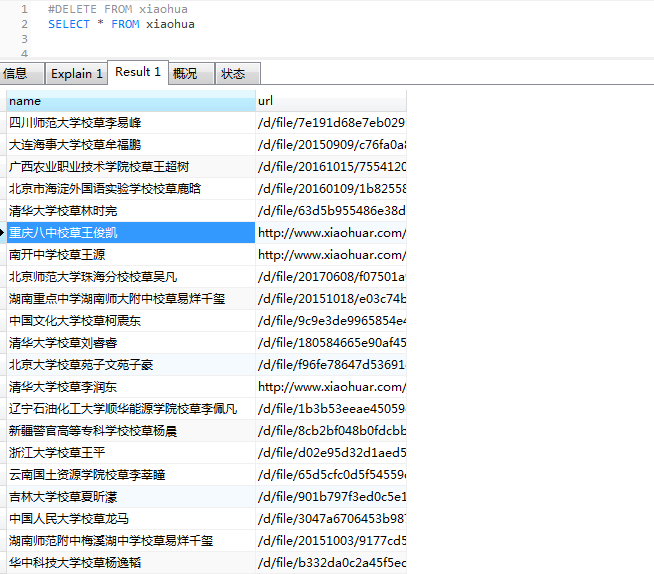
完成以上设定再来爬取,OK 大功告成(截取部分)
将爬取的数据保存到mysql中的更多相关文章
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- 顺企网 爬取16W数据保存到Mongodb
import requests from bs4 import BeautifulSoup import pymongo from multiprocessing.dummy import Pool ...
- Asp.net Session 保存到MySql中
一 网站项目引入"mysql.web.dll" 二 web.config配置中添加mysql数据库连接字符串 <connectionStrings> <remov ...
- Python scrapy爬虫数据保存到MySQL数据库
除将爬取到的信息写入文件中之外,程序也可通过修改 Pipeline 文件将数据保存到数据库中.为了使用数据库来保存爬取到的信息,在 MySQL 的 python 数据库中执行如下 SQL 语句来创建 ...
- c# 抓取和解析网页,并将table数据保存到datatable中(其他格式也可以,自己去修改)
使用HtmlAgilityPack 基础请参考这篇博客:https://www.cnblogs.com/fishyues/p/10232822.html 下面是根据抓取的页面string 来解析并保存 ...
- Excel文件数据保存到SQL中
1.获取DataTable /// <summary> /// 查询Excel文件中的数据 /// </summary> /// <param name="st ...
- Redis使用场景一,查询出的数据保存到Redis中,下次查询的时候直接从Redis中拿到数据。不用和数据库进行交互。
maven使用: <!--redis jar包--> <dependency> <groupId>redis.clients</groupId> < ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
随机推荐
- python中selenium操作下拉滚动条方法汇总
UI自动化中经常会遇到元素识别不到,找不到的问题,原因有很多,比如不在iframe里,xpath或id写错了等等:但有一种是在当前显示的页面元素不可见,拖动下拉条后元素就出来了. 比如下面这样一个网页 ...
- Java工程师学习指南 完结篇
Java工程师学习指南 完结篇 先声明一点,文章里面不会详细到每一步怎么操作,只会提供大致的思路和方向,给大家以启发,如果真的要一步一步指导操作的话,那至少需要一本书的厚度啦. 因为笔者还只是一名在校 ...
- JS实现图片懒加载插件
一.前言 我在前几篇博客的记录中,有说自己在做一个图片懒加载的功能,然后巴拉巴拉的遇到哪些问题,结果做完了也没对懒加载这个功能做一些记录,所以这篇文章主要针对我所实现的思路,以及代码做个记录,实现不佳 ...
- System V 与 POSIX 简介与对比
当我们在 Linux 系统中进行进程间通信时,例如信号量,消息队列,共享内存等方式,会发现有System V以及POSIX两种类型.今天我们就来简单介绍下它们. POSIX: POSIX(Portab ...
- vue-cli+webpack项目,修改项目名称
使用vue-cli+webpack创建的项目,修改文件名称或者更改文件的位置,运营时会报错,是因为npm项目,在安装依赖(node_nodules)时,会记录当前的文件路径,当修改之后就无法正常启动. ...
- asp.net mvc 模型验证组件——FluentValidation
asp.net mvc 模型验证组件——FluentValidation 示例 using FluentValidation; public class CustomerValidator: Abst ...
- MQTT再学习 -- MQTT 客户端源码分析
MQTT 源码分析,搜索了一下发现网络上讲的很少,多是逍遥子的那几篇. 参看:逍遥子_mosquitto源码分析系列 参看:MQTT libmosquitto源码分析 参看:Mosquitto学习笔记 ...
- Ado.net怎么执行存储过程?
与ADO.Net执行SQL语句的地方只有两点不同1.使用存储过程名代替sql语句2. 使用查询对象SqlCommand,需配置一个CommandType属性 存储过程的执行语法-> exec 存 ...
- 如何判断页面是pc端还是移动端,进入不同的页面
vue判断是pc端还是移动端分别进入不同的页面 判断移动端代码如下: function IsPC(){ var userAgentInfo = navigator.userAgent; var Age ...
- win10系统彻底卸载Mysql
本文介绍,在Windows10系统下,如何彻底删除卸载MySQL... 1>停止MySQL服务 开始->所有应用->Windows管理工具->服务,将MySQL服务停止. 2& ...