python_2开发简单爬虫
2017年12月03日 16:43:01 独行侠的守望 阅读数:204 标签: python爬虫 更多
个人分类: Python
编辑
版权声明:本文为博主原创文章,转载请注明文章链接。 https://blog.csdn.net/xiaoanzi123/article/details/78700863
学习地址:http://www.imooc.com/learn/563 慕课网
课程须知
本课程是Python语言开发的高级课程1、Python编程语法;2、HTML语言基础知识;3、正则表达式基础知识;
老师告诉你能学到什么?
1、爬虫技术的含义和存在价值
2、爬虫技术架构
3、组成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器
4、实战抓取百度百科1000个词条页面数据的抓取策略设定、实战代码编写、爬虫实例运行
5、一套极简的可扩展爬虫代码,修改本代码,你就能抓取任何互联网网页!
★第一章
课程介绍:
课程进行简单的爬虫讲解----不需要登录的静态网页抓取
1、爬虫简介
2、简单爬虫架构
3、URL管理器
4、网页下载器urllib2
5、网页解析器beautifulsoup
6、完整实例 爬虫百度百科
★第二章,
爬虫是什么 : 从一个url出发,自动访问他所关联的所有url,提取数据。
爬虫价值 : 爬取互联网数据为我所用,开发新产品提供更好的服务
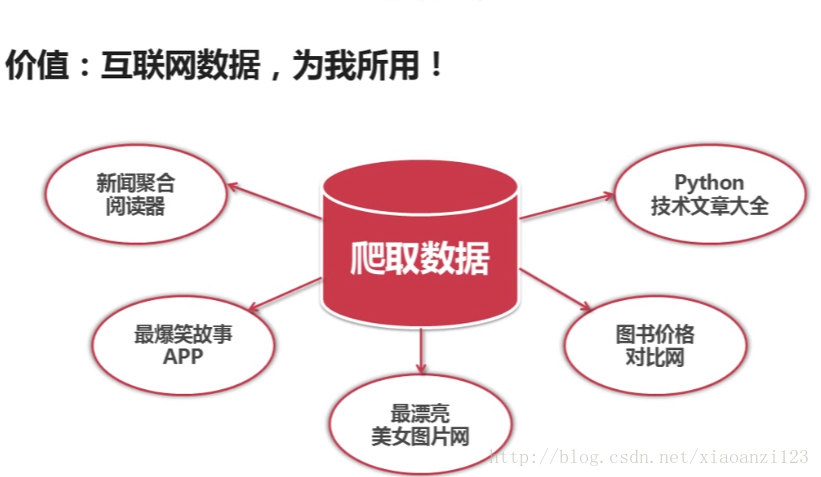
★第三章
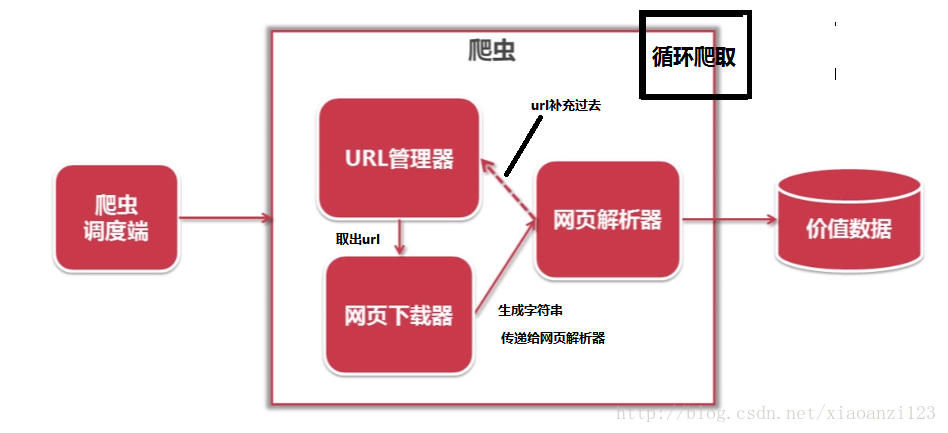
3-1 python简单爬虫架构
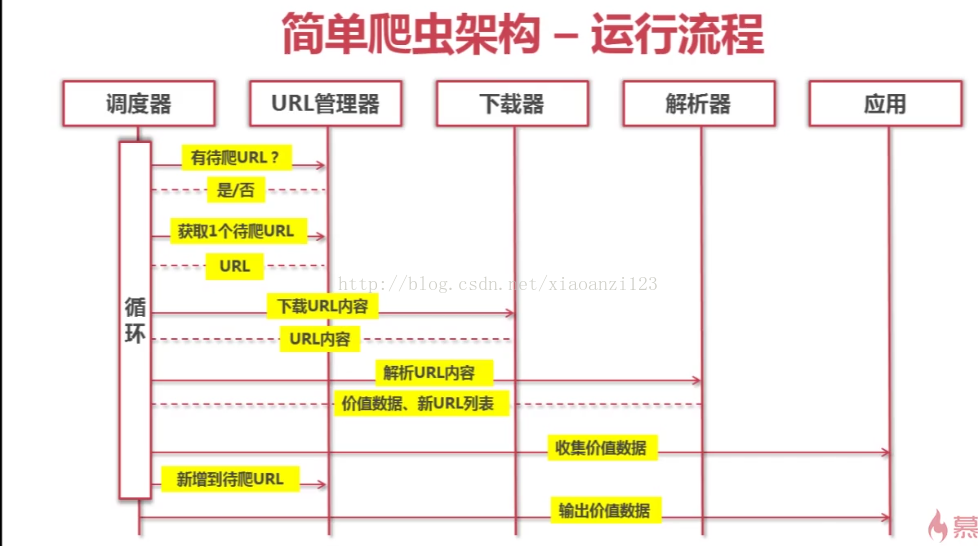
3-2 python简单爬虫架构 动态运行流程 【时序图】
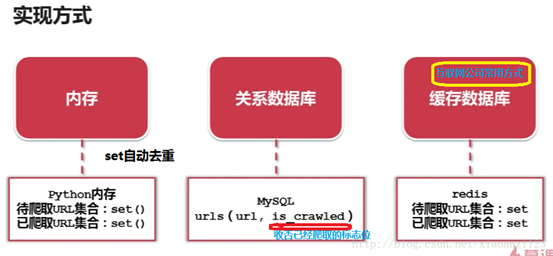
★第四章 url管理器和实现方法
4-1 url管理
管理待抓取url结合 和 已经抓取的url集合 ,防止重复抓取和循环抓取
url管理器支持的功能 至少5个

4-2 url管理器的实现方式
目前有三种。
★第五章 网页下载器和 urllib2 模块
5-1 网页下载器简介 将互联网上url对应的网页下载到本地的工具
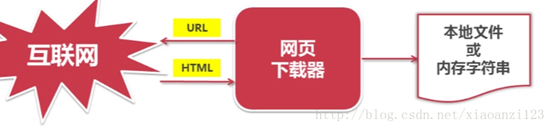
python有哪些网页下载器?
5-2 urllib2 下载器网页的三种方法
①最简洁方法:把url传递给urllib2模块的urlopen方法 urllib2.urlopen(url)

②
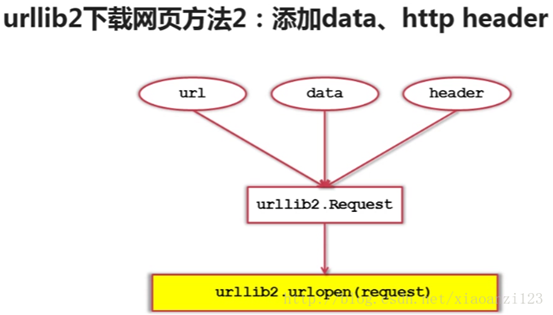

③
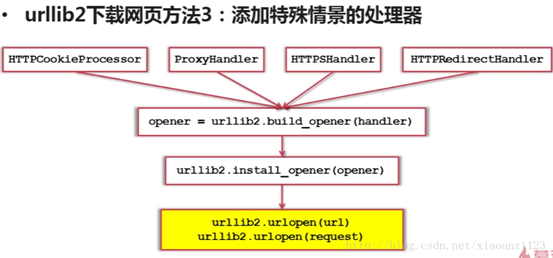

三种方法功能依次更大更强
5.3 urllib2实例代码演示
ps:我安装的是Python3.5.2 ,使用第一种urllib2.urlopen()报错,搜索发现官方3.0版本已经把urllib2,urlparse等五个模块都并入了urllib中,也就是整合了,参考 http://blog.csdn.net/pythonniu/article/details/51855035 ,正确用法
- import urllib.request
- url="http://www.baidu.com"
- get=urllib.request.urlopen(url).read()
- print(get)
★第六章 网页解析器和 beautifulsoup 第三方模块
6.1网页解析器简介
①正则表达式
②Python自带 html.parser
③第三方插件 beautifulsoup 强大,能使用② 和 ④
④第三方插件 lxml
①是模糊匹配,②③④是结构化解析。DOM树 ,熟悉吧๑乛◡乛๑
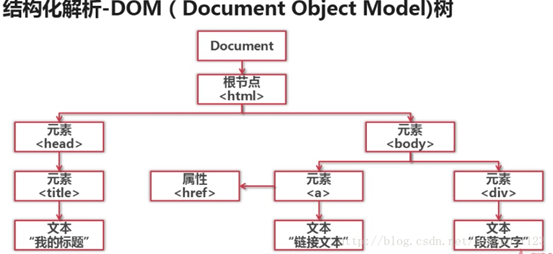
6.2beautifulsoup模块简介和安装
该模块属于Python第三方模块,用于从HTML或xml提取数据。
官网http://www.crummmy.com/software/BeautifulSoup
在线安装 beautifulsoup模块,截图如下【前提:已经有pip】

6.3beautifulsoup语法
流程:HTML网页 →创建beautifulsoup对象(生成dom树) →搜索节点(find_all 方法 和 find方法,可以按照 名称、属性、文字 来搜索) → 访问节点名称、属性、文字
例子:

代码如下:



6.4beautifulsoup实例测试
总结:课程教程是Python 2 版本,自己是3.x版本,总体还是从小白到 对python爬虫整体概况有所了解一点吧。
python_2开发简单爬虫的更多相关文章
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- .net mvc前台如何接收和解析后台的字典类型的数据 二分搜索算法 window.onunload中使用HTTP请求 网页关闭 OpenCvSharp尝试 简单爬虫
.net mvc前台如何接收和解析后台的字典类型的数据 很久没有写博客了,最近做了一个公司门户网站的小项目,其中接触到了一些我不会的知识点,今日事情少,便记录一下,当时想在网上搜索相关的内容,但是 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
- Python 开发轻量级爬虫01
Python 开发轻量级爬虫 (imooc总结01--课程目标) 课程目标:掌握开发轻量级爬虫 为什么说是轻量级的呢?因为一个复杂的爬虫需要考虑的问题场景非常多,比如有些网页需要用户登录了以后才能够访 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
随机推荐
- C# 判断路径和文件存在
1.判断路径是否存在,不存在则创建路径: if (!System.IO.Directory.Exists(@"D:\Export")) { System.IO.Directory. ...
- Java学习路线-知乎
鼬自来晓 378 人赞同 可以从几方面来看Java:JVM Java JVM:内存结构和相关参数含义 · Issue #24 · pzxwhc/MineKnowContainer · GitHub J ...
- IoC概述
---------------siwuxie095 IoC,即 Inversion of Control,控制反转,它是 Spring 容器的内核 AOP.声明式事务等功能都是在此基础上开花结果,即 ...
- 1.从GUI到MVC
GUI(graphic user interface 用户图形界面).GUI编程的目的是提供交互性,并根据用户的操作实时的更新界面.用户的操作是不可预知的鼠标和键盘事件,我们如何保持同步和更新?在上层 ...
- CodeForces 492C Vanya and Exams (贪心)
C. Vanya and Exams time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- PAM认证
PAM认证 摘自: http://www.cnblogs.com/shenxm/p/8451889.html PAM(Pluggable Authentication Modules) Sun公司于1 ...
- java基础题--自我准备
1.String,StringBuffer,StringBuilder区别---final类型的区别,何时用三者? 2.Vector与ArrayList区别--同步.线程安全.性能.容量扩增大小 3. ...
- MVC项目中的分页实现例子
在开发项目中,写了一个分页实现的例子,现在把源代码贴上,以供以后写代码时参考 在列表的头部,有如下显示, 这个代表一个页面显示10条记录,总共22条记录. 这个是页面底部的显示 那么如何来显示这个分页 ...
- LeetCode第14题:最长公共前缀
题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow ...
- 【redis对象,集合序列化Demo】
package org.seckill.dao.cache; import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStr ...