第25章 Pytorch 如何高效使用GPU
第25章 Pytorch 如何高效使用GPU
深度学习涉及很多向量或多矩阵运算,如矩阵相乘、矩阵相加、矩阵-向量乘法等。深层模型的算法,如BP,Auto-Encoder,CNN等,都可以写成矩阵运算的形式,无须写成循环运算。然而,在单核CPU上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行。GPU(Graphic Process Units,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间。随着NVIDIA、AMD等公司不断推进其GPU的大规模并行架构,面向通用计算的GPU已成为加速可并行应用程序的重要手段。得益于GPU众核(many-core)体系结构,程序在GPU系统上的运行速度相较于单核CPU往往提升几十倍乃至上千倍。
目前,GPU已经发展到了较为成熟的阶段。利用GPU来训练深度神经网络,可以充分发挥其数以千计计算核心的能力,在使用海量训练数据的场景下,所耗费的时间大幅缩短,占用的服务器也更少。如果对适当的深度神经网络进行合理优化,一块GPU卡相当于数十甚至上百台CPU服务器的计算能力,因此GPU已经成为业界在深度学习模型训练方面的首选解决方案。
如何使用GPU?现在很多深度学习工具都支持GPU运算,使用时只要简单配置即可。Pytorch支持GPU,可以通过to(device)函数来将数据从内存中转移到GPU显存,如果有多个GPU还可以定位到哪个或哪些GPU。Pytorch一般把GPU作用于张量(Tensor)或模型(包括torch.nn下面的一些网络模型以及自己创建的模型)等数据结构上。
25.1 单GPU加速
使用GPU之前,需要确保GPU是可以使用,可通过torch.cuda.is_available()的返回值来进行判断。返回True则具有能够使用的GPU。
通过torch.cuda.device_count()可以获得能够使用的GPU数量。
如何查看平台GPU的配置信息?在命令行输入命令nvidia-smi即可 (适合于Linux或Windows环境)。图5-13是GPU配置信息样例,从中可以看出共有2个GPU。
图5-13 GPU配置信息
把数据从内存转移到GPU,一般针对张量(我们需要的数据)和模型。
对张量(类型为FloatTensor或者是LongTensor等),一律直接使用方法.to(device)或.cuda()即可。
|
1
2
3
4
5
6
|
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#或device = torch.device("cuda:0")
device1 = torch.device("cuda:1")
for batch_idx, (img, label) in enumerate(train_loader):
img=img.to(device)
label=label.to(device)
|
对于模型来说,也是同样的方式,使用.to(device)或.cuda来将网络放到GPU显存。
|
1
2
3
4
|
#实例化网络
model = Net()
model.to(device) #使用序号为0的GPU
#或model.to(device1) #使用序号为1的GPU
|
25.2 多GPU加速
这里我们介绍单主机多GPUs的情况,单机多GPUs主要采用的DataParallel函数,而不是DistributedParallel,后者一般用于多主机多GPUs,当然也可用于单机多GPU。
使用多卡训练的方式有很多,当然前提是我们的设备中存在两个及以上的GPU。
使用时直接用model传入torch.nn.DataParallel函数即可,如下代码:
|
1
2
|
#对模型
net = torch.nn.DataParallel(model)
|
这时,默认所有存在的显卡都会被使用。
如果你的电脑有很多显卡,但只想利用其中一部分,如只使用编号为0、1、3、4的四个GPU,那么可以采用以下方式:
|
1
2
3
4
5
6
7
|
#假设有4个GPU,其id设置如下
device_ids =[0,1,2,3]
#对数据
input_data=input_data.to(device=device_ids[0])
#对于模型
net = torch.nn.DataParallel(model)
net.to(device)
|
或者
|
1
2
|
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0,1,2,3]))
net = torch.nn.DataParallel(model)
|
其中CUDA_VISIBLE_DEVICES 表示当前可以被Pytorch程序检测到的GPU。
下面为单机多GPU的实现代码。
(1)背景说明
这里使用波士顿房价数据为例,共506个样本,13个特征。数据划分成训练集和测试集,然后用data.DataLoader转换为可批加载的方式。采用nn.DataParallel并发机制,环境有2个GPU。当然,数据量很小,按理不宜用nn.DataParallel,这里只是为了说明使用方法。
(2)加载数据
|
1
2
3
4
5
6
|
boston = load_boston()
X,y = (boston.data, boston.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#组合训练数据及标签
myset = list(zip(X_train,y_train))
|
(2)把数据转换为批处理加载方式
批次大小为128,打乱数据。
|
1
2
3
4
|
from torch.utils import data
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dtype = torch.FloatTensor
train_loader = data.DataLoader(myset,batch_size=128,shuffle=True)
|
(3)定义网络
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class Net1(nn.Module):
"""
使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net1, self).__init__()
self.layer1 = torch.nn.Sequential(nn.Linear(in_dim, n_hidden_1))
self.layer2 = torch.nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2))
self.layer3 = torch.nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x1 = F.relu(self.layer1(x))
x1 = F.relu(self.layer2(x1))
x2 = self.layer3(x1)
#显示每个GPU分配的数据大小
print("\tIn Model: input size", x.size(),"output size", x2.size())
return x2
|
(4)把模型转换为多GPU并发处理格式
|
1
2
3
4
5
6
7
8
|
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#实例化网络
model = Net1(13, 16, 32, 1)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs")
# dim = 0 [64, xxx] -> [32, ...], [32, ...] on 2GPUs
model = nn.DataParallel(model)
model.to(device)
|
运行结果
Let's use 2 GPUs
DataParallel(
(module): Net1(
(layer1): Sequential(
(0): Linear(in_features=13, out_features=16, bias=True)
)
(layer2): Sequential(
(0): Linear(in_features=16, out_features=32, bias=True)
)
(layer3): Sequential(
(0): Linear(in_features=32, out_features=1, bias=True)
)
)
)
(5)选择优化器及损失函数
|
1
2
|
optimizer_orig = torch.optim.Adam(model.parameters(), lr=0.01)
loss_func = torch.nn.MSELoss()
|
(6)模型训练,并可视化损失值。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='logs')
for epoch in range(100):
model.train()
for data,label in train_loader:
input = data.type(dtype).to(device)
label = label.type(dtype).to(device)
output = model(input)
loss = loss_func(output, label)
# 反向传播
optimizer_orig.zero_grad()
loss.backward()
optimizer_orig.step()
print("Outside: input size", input.size() ,"output_size", output.size())
writer.add_scalar('train_loss_paral',loss, epoch)
|
运行的部分结果
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
Outside: input size torch.Size([128, 13]) output_size torch.Size([128, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
Outside: input size torch.Size([128, 13]) output_size torch.Size([128, 1])
从运行结果可以看出,一个批次数据(batch-size=128)拆分成两份,每份大小为64,分别放在不同的GPU上。此时用GPU监控也可发现,两个GPU都同时在使用。

(7)通过web查看损失值的变化情况
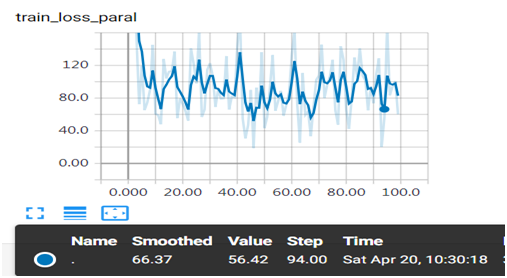
图5-16 并发运行训练损失值变化情况
图形中出现较大振幅,是由于采用批次处理,而且数据没有做任何预处理,对数据进行规范化应该更平滑一些,大家可以尝试一下。
单机多GPU也可使用DistributedParallel,它多用于分布式训练,但也可以用在单机多GPU的训练,配置比使用nn.DataParallel稍微麻烦一点,但是训练速度和效果更好一点。具体配置为:
|
1
2
3
4
|
#初始化使用nccl后端
torch.distributed.init_process_group(backend="nccl")
#模型并行化
model=torch.nn.parallel.DistributedDataParallel(model)
|
单机运行时使用下面方法启动
|
1
|
python -m torch.distributed.launch main.py
|
25.3使用GPU注意事项
使用GPU可以提升我们训练的速度,如果使用不当,可能影响使用效率,具体使用时要注意以下几点:
(1)GPU的数量尽量为偶数,奇数的GPU有可能会出现异常中断的情况;
(2)GPU很快,但数据量较小时,效果可能没有单GPU好,甚至还不如CPU;
(3)如果内存不够大,使用多GPU训练的时候可通过设置pin_memory为False,当然使用精度稍微低一点的数据类型有时也效果。
第25章 Pytorch 如何高效使用GPU的更多相关文章
- JavaScript高级程序设计(第三版)学习笔记22、24、25章
第22章,高级技巧 高级函数 安全的类型检测 typeof会出现无法预知的行为 instanceof在多个全局作用域中并不能正确工作 调用Object原生的toString方法,会返回[Object ...
- 第25章 串行FLASH文件系统FatFs—零死角玩转STM32-F429系列
第25章 串行FLASH文件系统FatFs 全套200集视频教程和1000页PDF教程请到秉火论坛下载:www.firebbs.cn 野火视频教程优酷观看网址:http://i.youku.c ...
- 【C#4.0图解教程】笔记(第19章~第25章)
第19章 泛型 1.泛型概念 泛型提供了一种更准确地使用有一种以上的类型的代码的方式. 泛型允许我们声明类型参数化的代码,我们可以用不同的类型进行实例化. 泛型不是类型,而是类型的模板. 2.声明 ...
- 【RL-TCPnet网络教程】第25章 DHCP动态主机配置协议基础知识
第25章 DHCP动态主机配置协议基础知识 本章节为大家讲解DHCP(Dynamic Host Configuration Protocol,动态主机配置协议),通过前面章节对TCP和UDP ...
- 【RL-TCPnet网络教程】第21章 RL-TCPnet之高效的事件触发框架
第21章 RL-TCPnet之高效的事件触发框架 本章节为大家讲解高效的事件触发框架实现方法,BSD Socket编程和后面章节要讲解到的FTP.TFTP和HTTP等都非常适合使用这种方式 ...
- CHAPTER 25 The Greatest Show on Earth 第25章 地球上最壮观的演出
CHAPTER 25 The Greatest Show on Earth 第25章 地球上最壮观的演出 Go for a walk in the countryside and you will f ...
- pytorch在CPU和GPU上加载模型
pytorch允许把在GPU上训练的模型加载到CPU上,也允许把在CPU上训练的模型加载到GPU上.CPU->CPU,GPU->GPU torch.load('gen_500000.pkl ...
- 【STM32H7教程】第25章 STM32H7的TCM,SRAM等五块内存基础知识
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第25章 STM32H7的TCM,SRAM等五块内 ...
- [GEiv]第七章:着色器 高效GPU渲染方案
第七章:着色器 高效GPU渲染方案 本章介绍着色器的基本知识以及Geiv下对其提供的支持接口.并以"渐变高斯模糊"为线索进行实例的演示解说. [背景信息] [计算机中央处理器的局限 ...
随机推荐
- Windows Phpstrom svn 配置
网上百度找到的解决方案行不通,就是下图两项都不选中.临时是可以的,但是到了第二天,又不行了. 以下是自己瞎弄的,居然可以了. 第一步:安装TortoiseSVN 1.8.* ,注意安装选项要选上com ...
- void 运算符
void 是 javascript 的操作符,意思是:只执行表达式,但没有返回值.该表达式会被计算但是不会在当前文档处装入任何内容,void其实是javascript中的一个函数,接受一个参数,返回值 ...
- 模拟退火解TSP问题MATLAB代码
分别把前四个函数存成m文件,再运行最后一个. swap.m function [ newpath , position ] = swap( oldpath , number ) % 对 oldpath ...
- SpringMVC代码复制版
Lib目录 Java目录 HelloController文件代码 import org.springframework.web.servlet.ModelAndView; import org.spr ...
- BootstrapValidation一些tips
BootstrapValidation一些tips:1. callback的用法 如果你有一些特别的检查需要,比如两个元素必需有一个有值,你可以在两个元素上加上callback,例:sel和cb必需有 ...
- JS设计模式之单例模式(一)
单例就是保证一个类只有一个实例,实现的方法一般是先判断实例存在与否,如果存在直接返回,如果不存在就创建了再返回,这 就确保了一个类只有一个实例对象. 在JavaScript里,实现单例的方式有很多种, ...
- fedora 安装ftp
fedora默认不安装ftp服务(包括client程序/service程序),需要进行手动安装: yum install ftp(安装client) yum install vsftpd(安装serv ...
- oracle如何检查用户是否用了默认密码
如果使用默认密码,很可能就对你的数据库造成一定的安全隐患,那么可以使用如下的查询获得那些用户使用默认密码 select username "User(s) with Default Pass ...
- 外贸电子商务网站之Prestashop 安装后台中文语言包
1.先进入到后台,我们进入Localization-> Localization2, 在下面的国家列表中,我们选择china ,导入即可. 3.进入Localization-> Trans ...
- 微服务开源生态报告 No.4
「微服务开源生态报告」,汇集各个开源项目近期的社区动态,帮助开发者们更高效的了解到各开源项目的最新进展. 社区动态包括,但不限于:版本发布.人员动态.项目动态和规划.培训和活动. 非常欢迎国内其他微服 ...