每日一问2:堆(heap)和栈(stack)的区别
因为这里没有明确指出堆是指数据结构还是存储方式,所以两个尝试都回答一下。
一.堆和栈作为数据结构
1.堆(heap),也叫做优先队列(priority queue),队列中允许的操作是先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素,但是堆中元素的排列不是按照到来的先后顺序,而是按照一定的优先顺序排列的。这个优先顺序可以是元素的大小或者其他规则。
2.栈(stack),是一种运算受限的线性表,栈中允许的操作时先进后出(FILO),在栈顶插入元素,在栈顶取出元素。另,堆栈连在一起就只指栈,也就是说堆栈指的是栈。
二.堆和栈作为存储方式
1.栈区,指由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
2.堆区,指由 new 分配而不是编译器自动分配的内存块,由应用程序控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
详细区别:
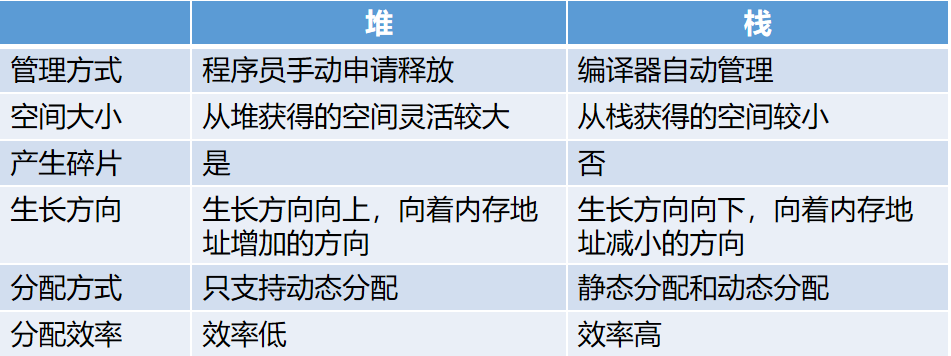
产生这些区别的原因:
生长方向:栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
————————————————
参考博文:https://blog.csdn.net/qq_35637562/article/details/78550953 https://www.cnblogs.com/youxin/p/3313288.html
每日一问2:堆(heap)和栈(stack)的区别的更多相关文章
- Java中堆(heap)和栈(stack)的区别
简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存. 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分 ...
- 堆(heap)和栈(stack)的区别
转: 一.预备知识―程序的内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1.栈区(stack)― 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.其操作方式类似于数据结构中 ...
- 转载C#中堆(heap)和栈(stack)的区别
转载原地址 http://www.cnblogs.com/wangshenhe/archive/2013/02/18/2916275.html [转]C#堆和栈的区别 理解堆与栈对于理解.NET中的 ...
- 数据结构与算法--堆(heap)与栈(stack)的区别
堆和栈的区别 在C.C++编程中,经常需要操作的内存可分为以下几个类别: 栈区(stack):由编译器自动分配和释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈. 堆区(heap ...
- JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )(转载)
想想面试的时候很多会问jvm这方面的问题虽然还是菜鸟不太能用到现在但是还是了解一下, 找资料的时候看见个大佬写的很好转载到这方便以后自己复习和给大佬做宣传 以下为大佬的博客原文: 这两天看了一下深入浅 ...
- [转]JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题: 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(h ...
- 堆heap和栈Stack(百科)
堆heap和栈Stack 在计算机领域,堆栈是一个不容忽视的概念,堆栈是两种数据结构.堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除.在单片机应用中,堆栈 ...
- JVM 内存初学 堆(heap)、栈(stack)和方法区(method)
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题:先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(he ...
- 转:JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
原文地址:JVM 内存初学 (堆(heap).栈(stack)和方法区(method) ) 博主推荐 深入浅出JVM 这本书 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(heap).栈( ...
随机推荐
- Java语法格式
任何一种语言都有自己的语法规则,Java也一样,既然是规则,那么知道其如何使用就可以了. 代码都定义在类中,类由class来定义,区分 public class 和 class; 代码严格区分大小 ...
- pytorch中如何处理RNN输入变长序列padding
一.为什么RNN需要处理变长输入 假设我们有情感分析的例子,对每句话进行一个感情级别的分类,主体流程大概是下图所示: 思路比较简单,但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练 ...
- C# 判断两条直线距离
本文告诉大家获得两条一般式直线距离 一般式的意思就是 Ax+By+C=0" role="presentation">Ax+By+C=0Ax+By+C=0 如果有两个 ...
- P1044 最大值最小化
题目描述 在印刷术发明之前,复制一本书是一个很困难的工作,工作量很大,而且需要大家的积极配合来抄写一本书,团队合作能力很重要.当时都是通过招募抄写员来进行书本的录入和复制工作的, 假设现在要抄写 \( ...
- jquery核心基础
jquery对对象的操作: 检查对象类型: 老式的javascript使用typeOf()操作符,但他是不符合逻辑的,在某些情况下,typeOf()返回的不是一个正确的值,或者返回一个出乎意料的值 ...
- 服务端CURL请求
服务端与服务端之间,也存在接口编程. 比如我们网站服务端,需要发送短信.发送邮件.查询快递等,都需要调用第三方平台的接口. 1.php中发送请求 ①file_get_contents函数 :传递完整的 ...
- HDU - 4289 Control (Dinic)
You, the head of Department of Security, recently received a top-secret information that a group of ...
- Dubbo-本地Bean测试
Dubbo本地测试API的Bean 一.建立一个测试类文件 二.测试API // 自己要测试的API public static final XxApi xxApi; 三.注入Bean static ...
- 聊聊多线程哪一些事儿(task)之 三 异步取消和异步方法
hello,咋们又见面啦,通过前面两篇文章的介绍,对task的创建.运行.阻塞.同步.延续操作等都有了很好的认识和使用,结合实际的场景介绍,这样一来在实际的工作中也能够解决很大一部分的关于多线程的业务 ...
- 王雅超的学习笔记-大数据hadoop集群部署(七)
MySQL的安装部署