Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖:

===================================
6. Spark 底层逻辑
从部署图了解
Spark部署了什么, 有什么组件运行在集群中通过对
WordCount案例的解剖, 来理解执行逻辑计划的生成通过对逻辑执行计划的细化, 理解如何生成物理计划
|
如无特殊说明, 以下部分均针对于 |
- 部署情况
-
在
Spark部分的底层执行逻辑开始之前, 还是要先认识一下Spark的部署情况, 根据部署情况, 从而理解如何调度.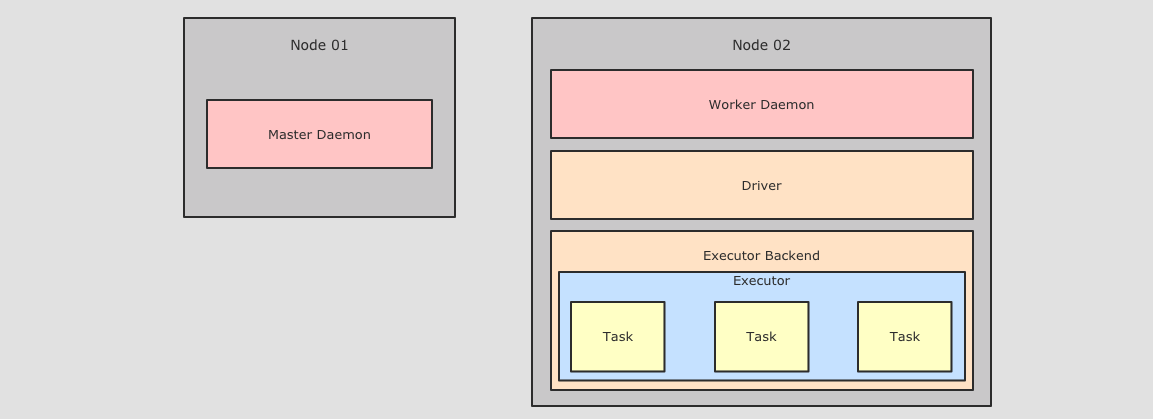
针对于上图, 首先可以看到整体上在集群中运行的角色有如下几个:
Master Daemon负责管理
Master节点, 协调资源的获取, 以及连接Worker节点来运行Executor, 是 Spark 集群中的协调节点Worker DaemonWorkers也称之为叫Slaves, 是 Spark 集群中的计算节点, 用于和 Master 交互并管理Executor.当一个
Spark Job提交后, 会创建SparkContext, 后Worker会启动对应的Executor.Executor Backend上面有提到
Worker用于控制Executor的启停, 其实Worker是通过Executor Backend来进行控制的,Executor Backend是一个进程(是一个JVM实例), 持有一个Executor对象
另外在启动程序的时候, 有三种程序需要运行在集群上:
DriverDriver是一个JVM实例, 是一个进程, 是Spark Application运行时候的领导者, 其中运行了SparkContext.Driver控制Job和Task, 并且提供WebUI.ExecutorExecutor对象中通过线程池来运行Task, 一个Executor中只会运行一个Spark Application的Task, 不同的Spark Application的Task会由不同的Executor来运行
- 案例
-
因为要理解执行计划, 重点不在案例, 所以本节以一个非常简单的案例作为入门, 就是我们第一个案例 WordCount
val sc = ... val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
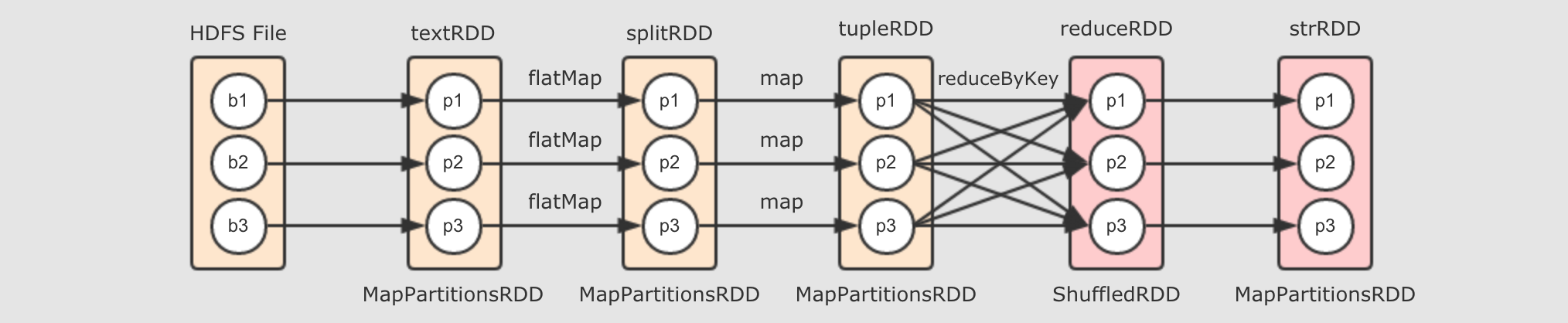
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}") println(strRDD.toDebugString)
strRDD.collect.foreach(item => println(item))整个案例的运行过程大致如下:
通过代码的运行, 生成对应的
RDD逻辑执行图通过
Action操作, 根据逻辑执行图生成对应的物理执行图, 也就是Stage和Task将物理执行图运行在集群中
- 逻辑执行图
-
对于上面代码中的
reduceRDD如果使用toDebugString打印调试信息的话, 会显式如下内容(6) MapPartitionsRDD[4] at map at WordCount.scala:20 []
| ShuffledRDD[3] at reduceByKey at WordCount.scala:19 []
+-(6) MapPartitionsRDD[2] at map at WordCount.scala:18 []
| MapPartitionsRDD[1] at flatMap at WordCount.scala:17 []
| ParallelCollectionRDD[0] at parallelize at WordCount.scala:16 []根据这段内容, 大致能得到这样的一张逻辑执行图
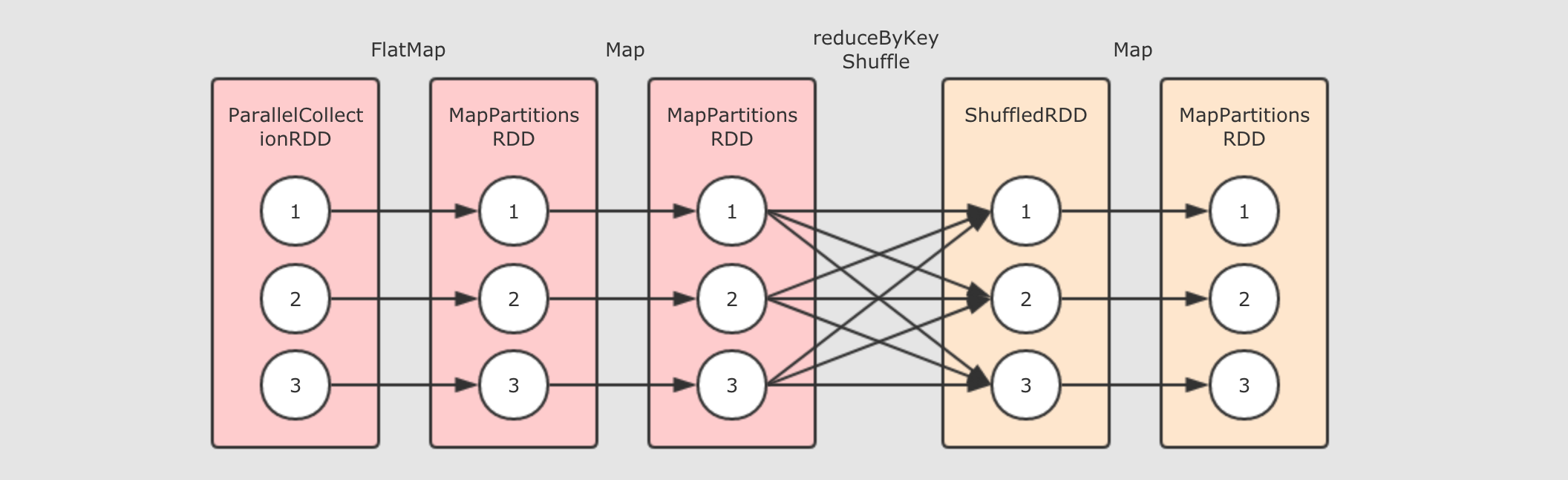
其实 RDD 并没有什么严格的逻辑执行图和物理执行图的概念, 这里也只是借用这个概念, 从而让整个 RDD 的原理可以解释, 好理解.
对于 RDD 的逻辑执行图, 起始于第一个入口 RDD 的创建, 结束于 Action 算子执行之前, 主要的过程就是生成一组互相有依赖关系的 RDD, 其并不会真的执行, 只是表示 RDD 之间的关系, 数据的流转过程.
- 物理执行图
-
当触发 Action 执行的时候, 这一组互相依赖的 RDD 要被处理, 所以要转化为可运行的物理执行图, 调度到集群中执行.
因为大部分 RDD 是不真正存放数据的, 只是数据从中流转, 所以, 不能直接在集群中运行 RDD, 要有一种 Pipeline 的思想, 需要将这组 RDD 转为 Stage 和 Task, 从而运行 Task, 优化整体执行速度.
以上的逻辑执行图会生成如下的物理执行图, 这一切发生在 Action 操作被执行时.
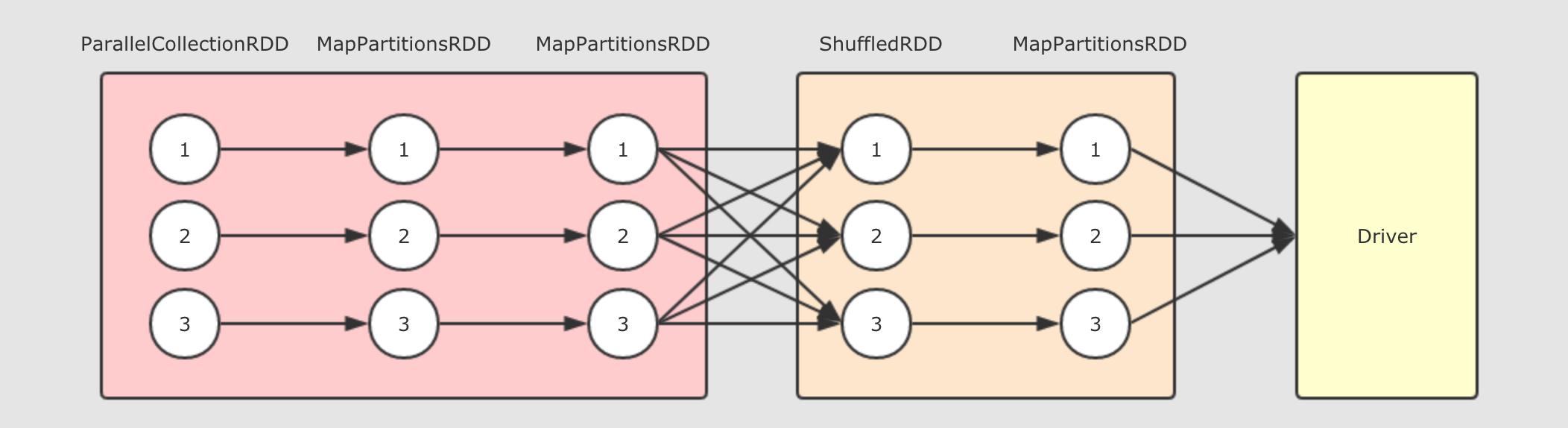
从上图可以总结如下几个点
 在第一个
在第一个 Stage中, 每一个这样的执行流程是一个Task, 也就是在同一个 Stage 中的所有 RDD 的对应分区, 在同一个 Task 中执行Stage 的划分是由 Shuffle 操作来确定的, 有 Shuffle 的地方, Stage 断开
6.1. 逻辑执行图生成
如何生成 RDD
如何控制 RDD 之间的关系
6.1.1. RDD 的生成
本章要回答如下三个问题
如何生成 RDD
生成什么 RDD
如何计算 RDD 中的数据
val sc = ...
val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}")
println(strRDD.toDebugString)
strRDD.collect.foreach(item => println(item))- 明确逻辑计划的边界
-
在
Action调用之前, 会生成一系列的RDD, 这些RDD之间的关系, 其实就是整个逻辑计划例如上述代码, 如果生成逻辑计划的, 会生成如下一些
RDD, 这些RDD是相互关联的, 这些RDD之间, 其实本质上生成的就是一个 计算链
接下来, 采用迭代渐进式的方式, 一步一步的查看一下整体上的生成过程
textFile算子的背后-
研究
RDD的功能或者表现的时候, 其实本质上研究的就是RDD中的五大属性, 因为RDD透过五大属性来提供功能和表现, 所以如果要研究textFile这个算子, 应该从五大属性着手, 那么第一步就要看看生成的RDD是什么类型的RDDtextFile生成的是HadoopRDD
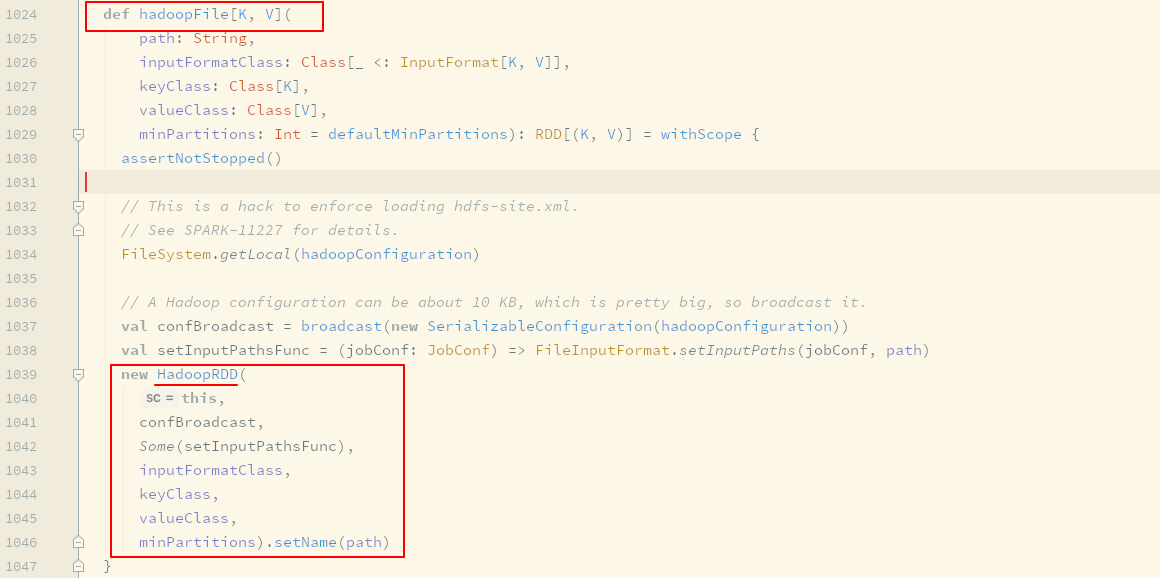
除了上面这一个步骤以外, 后续步骤将不再直接基于代码进行讲解, 因为从代码的角度着手容易迷失逻辑, 这个章节的初心有两个, 一个是希望大家了解 Spark 的内部逻辑和原理, 另外一个是希望大家能够通过本章学习具有代码分析的能力
HadoopRDD的Partitions对应了HDFS的Blocks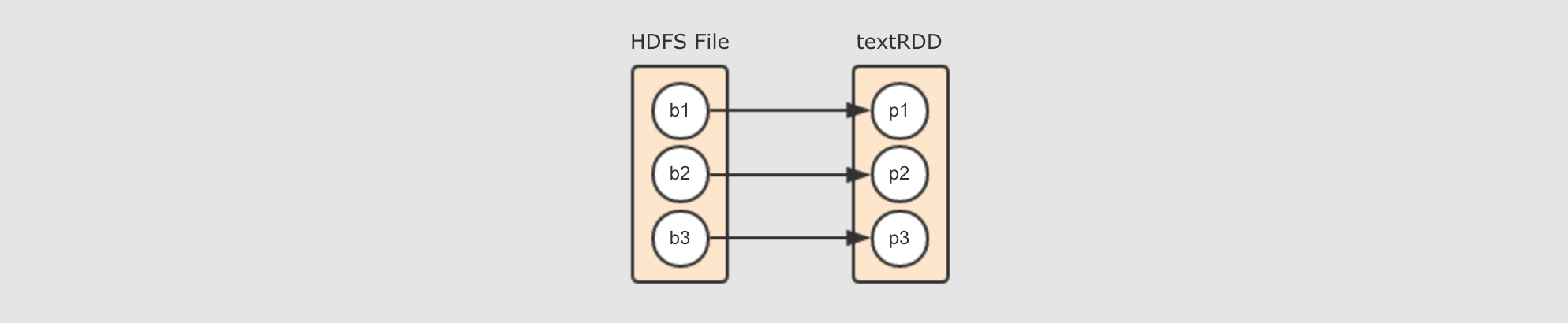
其实本质上每个
HadoopRDD的Partition都是对应了一个Hadoop的Block, 通过InputFormat来确定Hadoop中的Block的位置和边界, 从而可以供一些算子使用HadoopRDD的compute函数就是在读取HDFS中的Block本质上,
compute还是依然使用InputFormat来读取HDFS中对应分区的BlocktextFile这个算子生成的其实是一个MapPartitionsRDDtextFile这个算子的作用是读取HDFS上的文件, 但是HadoopRDD中存放是一个元组, 其Key是行号, 其Value是Hadoop中定义的Text对象, 这一点和MapReduce程序中的行为是一致的但是并不适合
Spark的场景, 所以最终会通过一个map算子, 将(LineNum, Text)转为String形式的一行一行的数据, 所以最终textFile这个算子生成的RDD并不是HadoopRDD, 而是一个MapPartitionsRDD
map算子的背后-

map算子生成了MapPartitionsRDD由源码可知, 当
val rdd2 = rdd1.map()的时候, 其实生成的新RDD是rdd2,rdd2的类型是MapPartitionsRDD, 每个RDD中的五大属性都会有一些不同, 由map算子生成的RDD中的计算函数, 本质上就是遍历对应分区的数据, 将每一个数据转成另外的形式MapPartitionsRDD的计算函数是collection.map( function )真正运行的集群中的处理单元是
Task, 每个Task对应一个RDD的分区, 所以collection对应一个RDD分区的所有数据, 而这个计算的含义就是将一个RDD的分区上所有数据当作一个集合, 通过这个Scala集合的map算子, 来执行一个转换操作, 其转换操作的函数就是传入map算子的function传入
map算子的函数会被清理
这个清理主要是处理闭包中的依赖, 使得这个闭包可以被序列化发往不同的集群节点运行
flatMap算子的背后-

flatMap和map算子其实本质上是一样的, 其步骤和生成的RDD都是一样, 只是对于传入函数的处理不同,map是collect.map( function )而flatMap是collect.flatMap( function )从侧面印证了, 其实
Spark中的flatMap和Scala基础中的flatMap其实是一样的 textRDD→splitRDD→tupleRDD-
由
textRDD到splitRDD再到tupleRDD的过程, 其实就是调用map和flatMap算子生成新的RDD的过程, 所以如下图所示, 就是这个阶段所生成的逻辑计划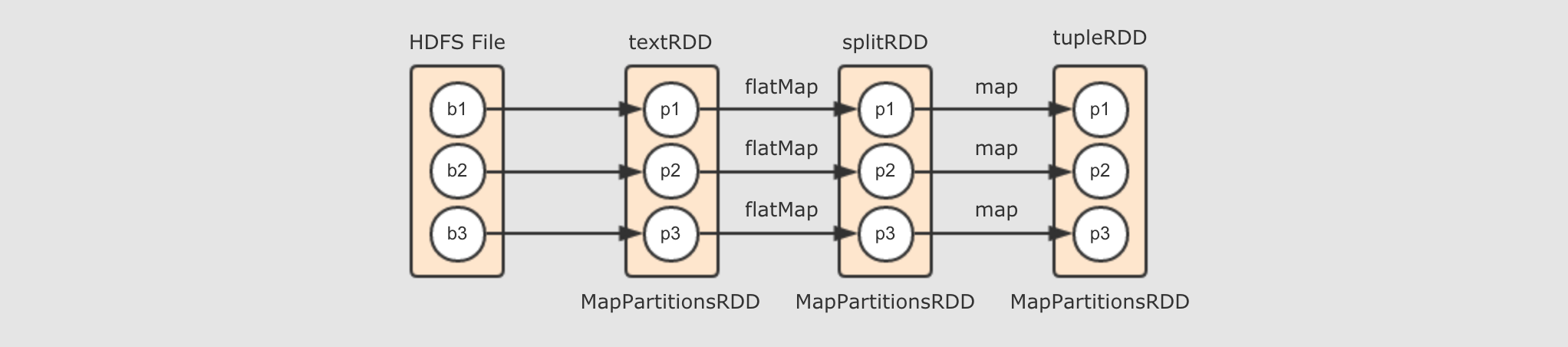
- 如何生成
RDD? -
生成
RDD的常见方式有三种从本地集合创建
从外部数据集创建
从其它
RDD衍生
通过外部数据集创建
RDD, 是通过Hadoop或者其它外部数据源的SDK来进行数据读取, 同时如果外部数据源是有分片的话,RDD会将分区与其分片进行对照通过其它
RDD衍生的话, 其实本质上就是通过不同的算子生成不同的RDD的子类对象, 从而控制compute函数的行为来实现算子功能 - 生成哪些
RDD? -
不同的算子生成不同的
RDD, 生成RDD的类型取决于算子, 例如map和flatMap都会生成RDD的子类MapPartitions的对象 - 如何计算
RDD中的数据 ? -
虽然前面我们提到过
RDD是偏向计算的, 但是其实RDD还只是表示数据, 纵观RDD的五大属性中有三个是必须的, 分别如下Partitions List分区列表Compute function计算函数Dependencies依赖
虽然计算函数是和计算有关的, 但是只有调用了这个函数才会进行计算,
RDD显然不会自己调用自己的Compute函数, 一定是由外部调用的, 所以RDD更多的意义是用于表示数据集以及其来源, 和针对于数据的计算所以如何计算
RDD中的数据呢? 一定是通过其它的组件来计算的, 而计算的规则, 由RDD中的Compute函数来指定, 不同类型的RDD子类有不同的Compute函数
6.1.2. RDD 之间的依赖关系
讨论什么是 RDD 之间的依赖关系
继而讨论 RDD 分区之间的关系
最后确定 RDD 之间的依赖关系分类
完善案例的逻辑关系图
- 什么是
RDD之间的依赖关系? -
什么是关系(依赖关系) ?
从算子视角上来看,
splitRDD通过map算子得到了tupleRDD, 所以splitRDD和tupleRDD之间的关系是map但是仅仅这样说, 会不够全面, 从细节上来看,
RDD只是数据和关于数据的计算, 而具体执行这种计算得出结果的是一个神秘的其它组件, 所以, 这两个RDD的关系可以表示为splitRDD的数据通过map操作, 被传入tupleRDD, 这是它们之间更细化的关系但是
RDD这个概念本身并不是数据容器, 数据真正应该存放的地方是RDD的分区, 所以如果把视角放在数据这一层面上的话, 直接讲这两个 RDD 之间有关系是不科学的, 应该从这两个 RDD 的分区之间的关系来讨论它们之间的关系那这些分区之间是什么关系?
如果仅仅说
splitRDD和tupleRDD之间的话, 那它们的分区之间就是一对一的关系但是
tupleRDD到reduceRDD呢?tupleRDD通过算子reduceByKey生成reduceRDD, 而这个算子是一个Shuffle操作,Shuffle操作的两个RDD的分区之间并不是一对一,reduceByKey的一个分区对应tupleRDD的多个分区
reduceByKey算子会生成ShuffledRDD-
reduceByKey是由算子combineByKey来实现的,combineByKey内部会创建ShuffledRDD返回, 具体的代码请大家通过IDEA来进行查看, 此处不再截图, 而整个reduceByKey操作大致如下过程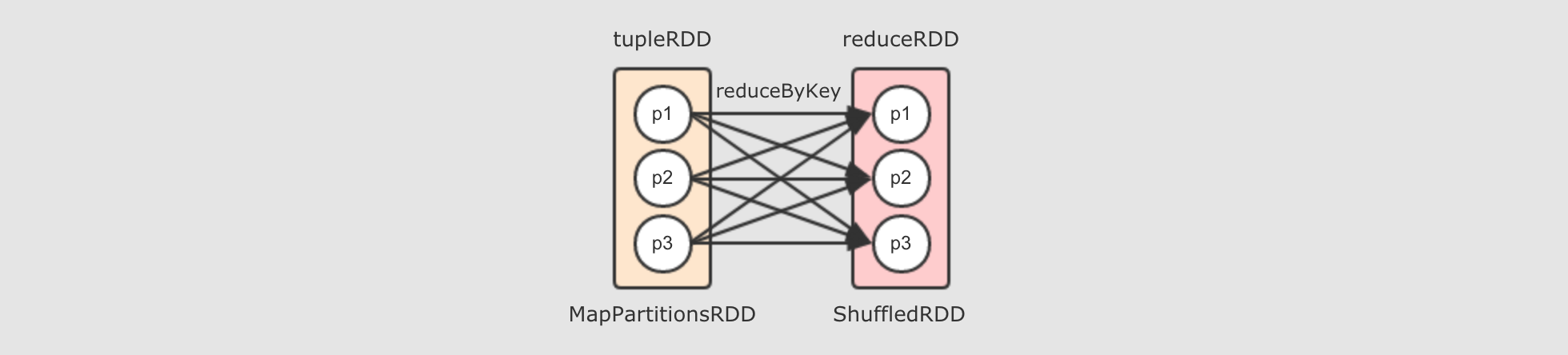
去掉两个
reducer端的分区, 只留下一个的话, 如下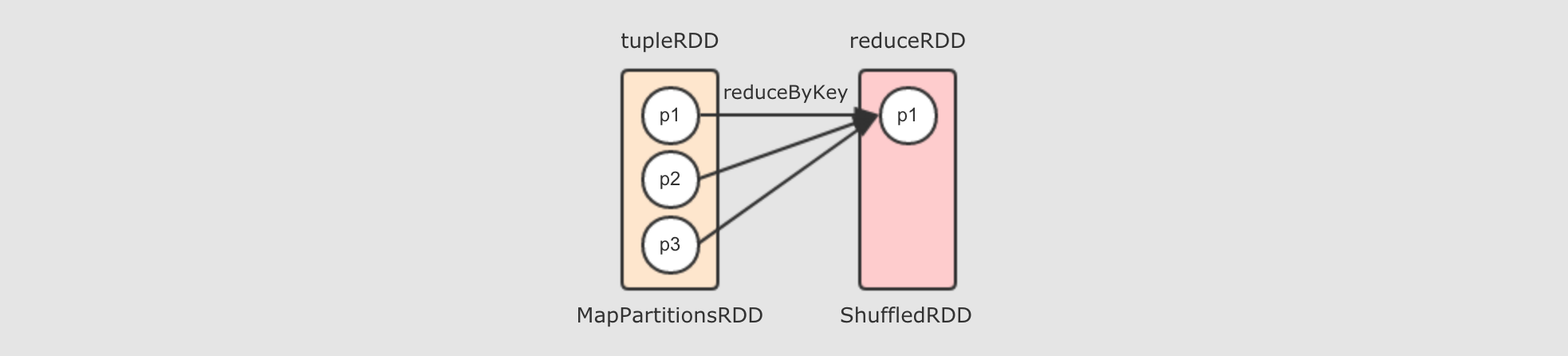
所以, 对于
reduceByKey这个Shuffle操作来说,reducer端的一个分区, 会从多个mapper端的分区拿取数据, 是一个多对一的关系至此为止, 出现了两种分区见的关系了, 一种是一对一, 一种是多对一
- 整体上的流程图
-
6.1.3. RDD 之间的依赖关系详解
上个小节通过例子演示了 RDD 的分区间的关系有两种形式
一对一, 一般是直接转换
多对一, 一般是 Shuffle
本小节会说明如下问题:
如果分区间得关系是一对一或者多对一, 那么这种情况下的 RDD 之间的关系的正式命名是什么呢?
RDD 之间的依赖关系, 具体有几种情况呢?
- 窄依赖
-
假如
rddB = rddA.transform(…), 如果rddB中一个分区依赖rddA也就是其父RDD的少量分区, 这种RDD之间的依赖关系称之为窄依赖换句话说, 子 RDD 的每个分区依赖父 RDD 的少量个数的分区, 这种依赖关系称之为窄依赖
举个栗子
val sc = ... val rddA = sc.parallelize(Seq(1, 2, 3))
val rddB = sc.parallelize(Seq("a", "b")) /**
* 运行结果: (1,a), (1,b), (2,a), (2,b), (3,a), (3,b)
*/
rddA.cartesian(rddB).collect().foreach(println(_))上述代码的
cartesian是求得两个集合的笛卡尔积上述代码的运行结果是
rddA中每个元素和rddB中的所有元素结合, 最终的结果数量是两个RDD数量之和rddC有两个父RDD, 分别为rddA和rddB
对于
cartesian来说, 依赖关系如下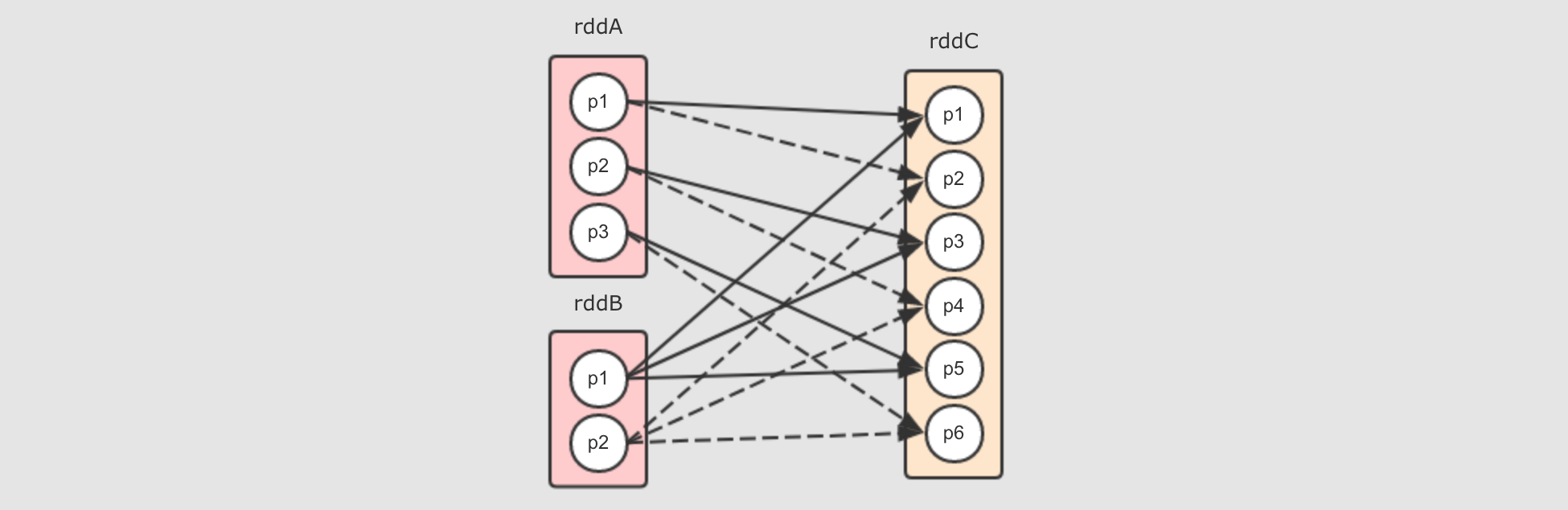
上述图形中清晰展示如下现象
rddC中的分区数量是两个父RDD的分区数量之乘积rddA中每个分区对应rddC中的两个分区 (因为rddB中有两个分区),rddB中的每个分区对应rddC中的三个分区 (因为rddA有三个分区)
它们之间是窄依赖, 事实上在
cartesian中也是NarrowDependency这个所有窄依赖的父类的唯一一次直接使用, 为什么呢?因为所有的分区之间是拷贝关系, 并不是 Shuffle 关系
rddC中的每个分区并不是依赖多个父RDD中的多个分区rddC中每个分区的数量来自一个父RDD分区中的所有数据, 是一个FullDependence, 所以数据可以直接从父RDD流动到子RDD不存在一个父
RDD中一部分数据分发过去, 另一部分分发给其它的RDD
- 宽依赖
-
并没有所谓的宽依赖, 宽依赖应该称作为
ShuffleDependency在
ShuffleDependency的类声明上如下写到Represents a dependency on the output of a shuffle stage.上面非常清楚的说道, 宽依赖就是
Shuffle中的依赖关系, 换句话说, 只有Shuffle产生的地方才是宽依赖那么宽窄依赖的判断依据就非常简单明确了, 是否有 Shuffle ?
举个
reduceByKey的例子,rddB = rddA.reduceByKey( (curr, agg) ⇒ curr + agg )会产生如下的依赖关系
rddB的每个分区都几乎依赖rddA的所有分区对于
rddA中的一个分区来说, 其将一部分分发给rddB的p1, 另外一部分分发给rddB的p2, 这不是数据流动, 而是分发
- 如何分辨宽窄依赖 ?
-
其实分辨宽窄依赖的本身就是在分辨父子
RDD之间是否有Shuffle, 大致有以下的方法如果是
Shuffle, 两个RDD的分区之间不是单纯的数据流动, 而是分发和复制一般
Shuffle的子RDD的每个分区会依赖父RDD的多个分区
但是这样判断其实不准确, 如果想分辨某个算子是否是窄依赖, 或者是否是宽依赖, 则还是要取决于具体的算子, 例如想看
cartesian生成的是宽依赖还是窄依赖, 可以通过如下步骤查看
map算子生成的RDD
进去
RDD查看getDependence方法
RDD 的逻辑图本质上是对于计算过程的表达, 例如数据从哪来, 经历了哪些步骤的计算
每一个步骤都对应一个 RDD, 因为数据处理的情况不同, RDD 之间的依赖关系又分为窄依赖和宽依赖 *
6.1.4. 常见的窄依赖类型
常见的窄依赖其实也是有分类的, 而且宽窄以来不太容易分辨, 所以通过本章, 帮助同学明确窄依赖的类型
- 一对一窄依赖
-
其实
RDD中默认的是OneToOneDependency, 后被不同的RDD子类指定为其它的依赖类型, 常见的一对一依赖是map算子所产生的依赖, 例如rddB = rddA.map(…)
每个分区之间一一对应, 所以叫做一对一窄依赖
- Range 窄依赖
-
Range窄依赖其实也是一对一窄依赖, 但是保留了中间的分隔信息, 可以通过某个分区获取其父分区, 目前只有一个算子生成这种窄依赖, 就是union算子, 例如rddC = rddA.union(rddB)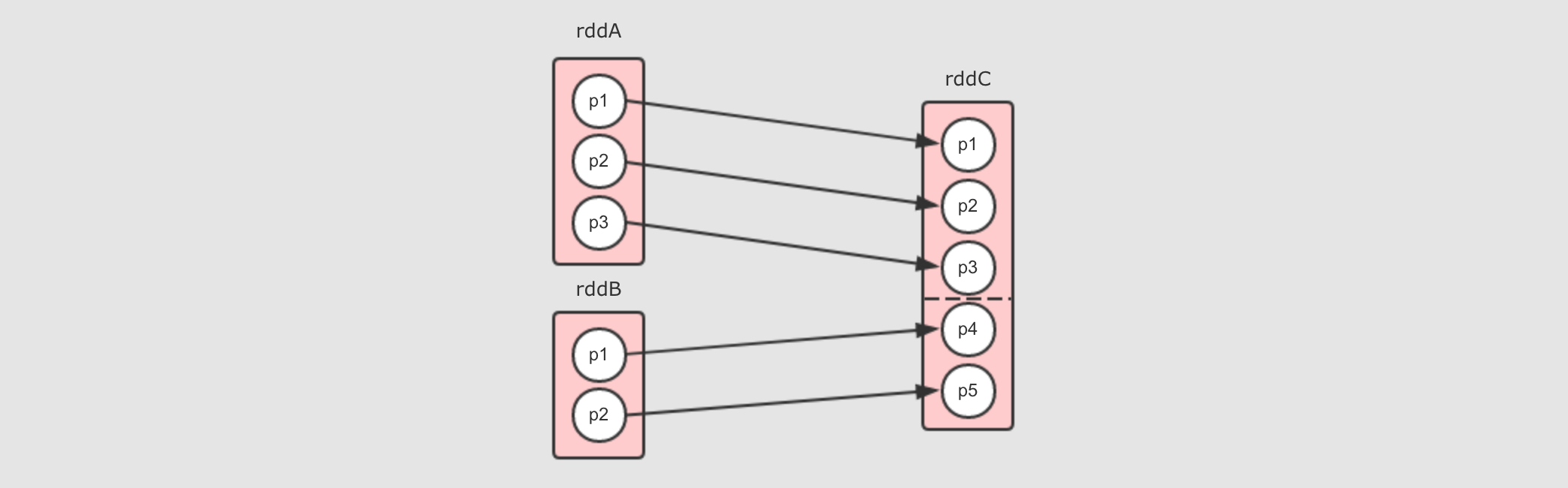
rddC其实就是rddA拼接rddB生成的, 所以rddC的p5和p6就是rddB的p1和p2所以需要有方式获取到
rddC的p5其父分区是谁, 于是就需要记录一下边界, 其它部分和一对一窄依赖一样
- 多对一窄依赖
-
多对一窄依赖其图形和
Shuffle依赖非常相似, 所以在遇到的时候, 要注意其RDD之间是否有Shuffle过程, 比较容易让人困惑, 常见的多对一依赖就是重分区算子coalesce, 例如rddB = rddA.coalesce(2, shuffle = false), 但同时也要注意, 如果shuffle = true那就是完全不同的情况了
因为没有
Shuffle, 所以这是一个窄依赖
- 再谈宽窄依赖的区别
-
宽窄依赖的区别非常重要, 因为涉及了一件非常重要的事情: 如何计算
RDD?宽窄以来的核心区别是: 窄依赖的
RDD可以放在一个Task中运行
6.2. 物理执行图生成
物理图的意义
如何划分 Task
如何划分 Stage
- 物理图的作用是什么?
-
- 问题一: 物理图的意义是什么?
-
物理图解决的其实就是
RDD流程生成以后, 如何计算和运行的问题, 也就是如何把 RDD 放在集群中执行的问题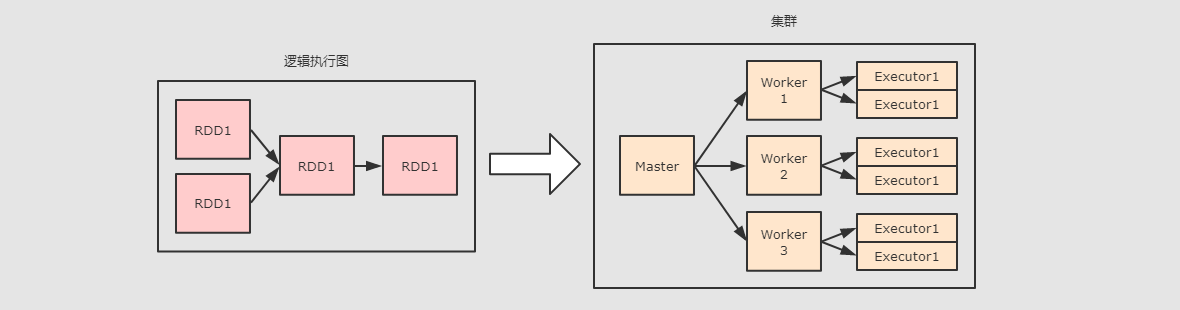
- 问题二: 如果要确定如何运行的问题, 则需要先确定集群中有什么组件
-
首先集群中物理元件就是一台一台的机器
其次这些机器上跑的守护进程有两种:
Master,Worker每个守护进程其实就代表了一台机器, 代表这台机器的角色, 代表这台机器和外界通信
例如我们常说一台机器是
Master, 其含义是这台机器中运行了一个Master守护进程, 如果一台机器运行了Master的同时又运行了Worker, 则说这台机器是Master也可以, 说它是Worker也行
真正能运行
RDD的组件是:Executor, 也就是说其实RDD最终是运行在Executor中的, 也就是说, 无论是Master还是Worker其实都是用于管理Executor和调度程序的
结论是
RDD一定在Executor中计算, 而Master和Worker负责调度和管理Executor - 问题三: 物理图的生成需要考虑什么问题?
-
要计算
RDD, 不仅要计算, 还要很快的计算 → 优化性能要考虑容错, 容错的常见手段是缓存 →
RDD要可以缓存
结论是在生成物理图的时候, 不仅要考虑效率问题, 还要考虑一种更合适的方式, 让
RDD运行的更好
- 谁来计算 RDD ?
-
- 问题一: RDD 是什么, 用来做什么 ?
-
回顾一下
RDD的五个属性A list of partitionsA function for computing each splitA list of dependencies on other RDDsOptionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
简单的说就是: 分区列表, 计算函数, 依赖关系, 分区函数, 最佳位置
分区列表, 分区函数, 最佳位置, 这三个属性其实说的就是数据集在哪, 在哪更合适, 如何分区
计算函数和依赖关系, 这两个属性其实说的是数据集从哪来
所以结论是
RDD是一个数据集的表示, 不仅表示了数据集, 还表示了这个数据集从哪来, 如何计算但是问题是, 谁来计算 ? 如果为一台汽车设计了一个设计图, 那么设计图自己生产汽车吗 ?
- 问题二: 谁来计算 ?
-
前面我们明确了两件事,
RDD在哪被计算? 在Executor中.RDD是什么? 是一个数据集以及其如何计算的图纸.直接使用
Executor也是不合适的, 因为一个计算的执行总是需要一个容器, 例如JVM是一个进程, 只有进程中才能有线程, 所以这个计算RDD的线程应该运行在一个进程中, 这个进程就是Exeutor,Executor有如下两个职责和
Driver保持交互从而认领属于自己的任务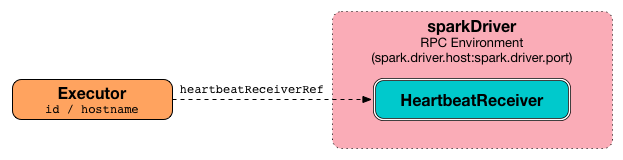
接受任务后, 运行任务

所以, 应该由一个线程来执行
RDD的计算任务, 而Executor作为执行这个任务的容器, 也就是一个进程, 用于创建和执行线程, 这个执行具体计算任务的线程叫做Task - 问题三: Task 该如何设计 ?
-
第一个想法是每个
RDD都由一个Task来计算 第二个想法是一整个逻辑执行图中所有的RDD都由一组Task来执行 第三个想法是分阶段执行- 第一个想法: 为每个 RDD 的分区设置一组 Task
-

大概就是每个
RDD都有三个Task, 每个Task对应一个RDD的分区, 执行一个分区的数据的计算但是这么做有一个非常难以解决的问题, 就是数据存储的问题, 例如
Task 1, 4, 7, 10, 13, 16在同一个流程上, 但是这些Task之间需要交换数据, 因为这些Task可能被调度到不同的机器上上, 所以Task1执行完了数据以后需要暂存, 后交给Task4来获取这只是一个简单的逻辑图, 如果是一个复杂的逻辑图, 会有什么表现? 要存储多少数据? 无论是放在磁盘还是放在内存中, 是不是都是一种极大的负担?
- 第二个想法: 让数据流动
-
很自然的, 第一个想法的问题是数据需要存储和交换, 那不存储不就好了吗? 对, 可以让数据流动起来
第一个要解决的问题就是, 要为数据创建管道(
Pipeline), 有了管道, 就可以流动
简单来说, 就是为所有的
RDD有关联的分区使用同一个Task, 但是就没问题了吗? 请关注红框部分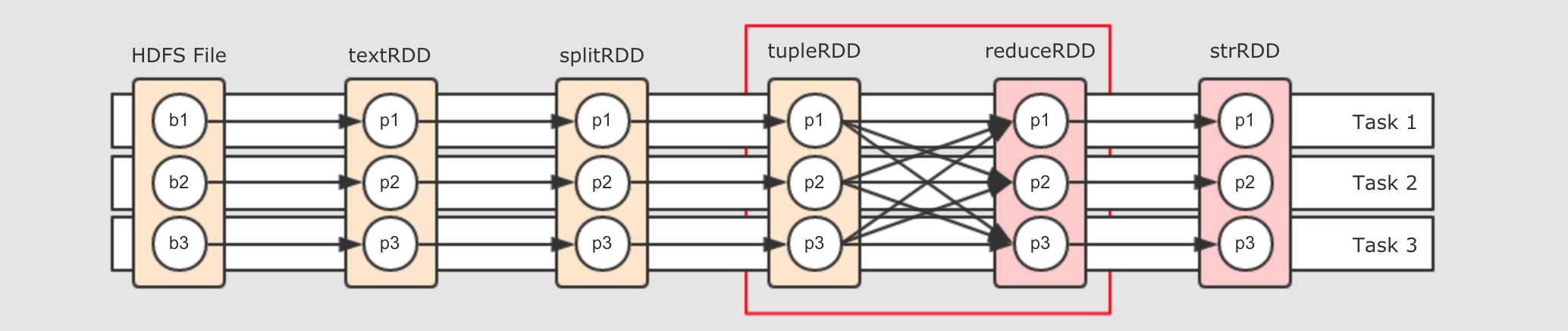
这两个
RDD之间是Shuffle关系, 也就是说, 右边的RDD的一个分区可能依赖左边RDD的所有分区, 这样的话, 数据在这个地方流不动了, 怎么办? - 第三个想法: 划分阶段
-
既然在
Shuffle处数据流不动了, 那就可以在这个地方中断一下, 后面Stage部分详解
- 如何划分阶段 ?
-
为了减少执行任务, 减少数据暂存和交换的机会, 所以需要创建管道, 让数据沿着管道流动, 其实也就是原先每个
RDD都有一组Task, 现在改为所有的RDD共用一组Task, 但是也有问题, 问题如下就是说, 在
Shuffle处, 必须断开管道, 进行数据交换, 交换过后, 继续流动, 所以整个流程可以变为如下样子
把
Task断开成两个部分,Task4可以从Task 1, 2, 3中获取数据, 后Task4又作为管道, 继续让数据在其中流动但是还有一个问题, 说断开就直接断开吗? 不用打个招呼的呀? 这个断开即没有道理, 也没有规则, 所以可以为这个断开增加一个概念叫做阶段, 按照阶段断开, 阶段的英文叫做
Stage, 如下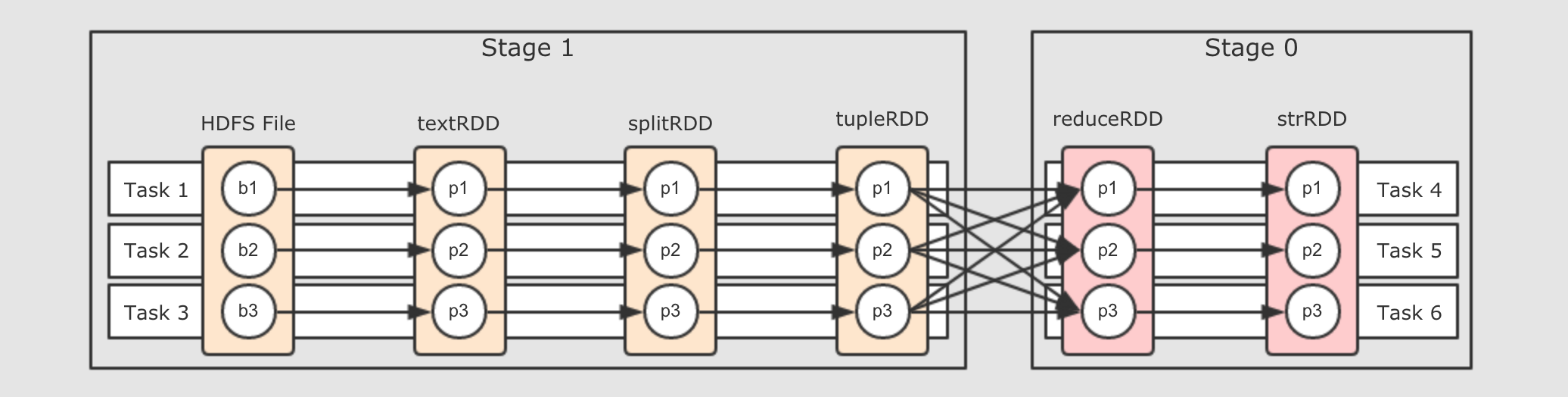
所以划分阶段的本身就是设置断开点的规则, 那么该如何划分阶段呢?
第一步, 从最后一个
RDD, 也就是逻辑图中最右边的RDD开始, 向前滑动Stage的范围, 为Stage0第二步, 遇到
ShuffleDependency断开Stage, 从下一个RDD开始创建新的Stage, 为Stage1第三步, 新的
Stage按照同样的规则继续滑动, 直到包裹所有的RDD
总结来看, 就是针对于宽窄依赖来判断, 一个
Stage中只有窄依赖, 因为只有窄依赖才能形成数据的Pipeline.如果要进行
Shuffle的话, 数据是流不过去的, 必须要拷贝和拉取. 所以遇到RDD宽依赖的两个RDD时, 要切断这两个RDD的Stage.这样一个 RDD 依赖的链条, 我们称之为 RDD 的血统, 其中有宽依赖也有窄依赖
- 数据怎么流动 ?
-
val sc = ... val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}") strRDD.collect.foreach(item => println(item))上述代码是这个章节我们一直使用的代码流程, 如下是其完整的逻辑执行图
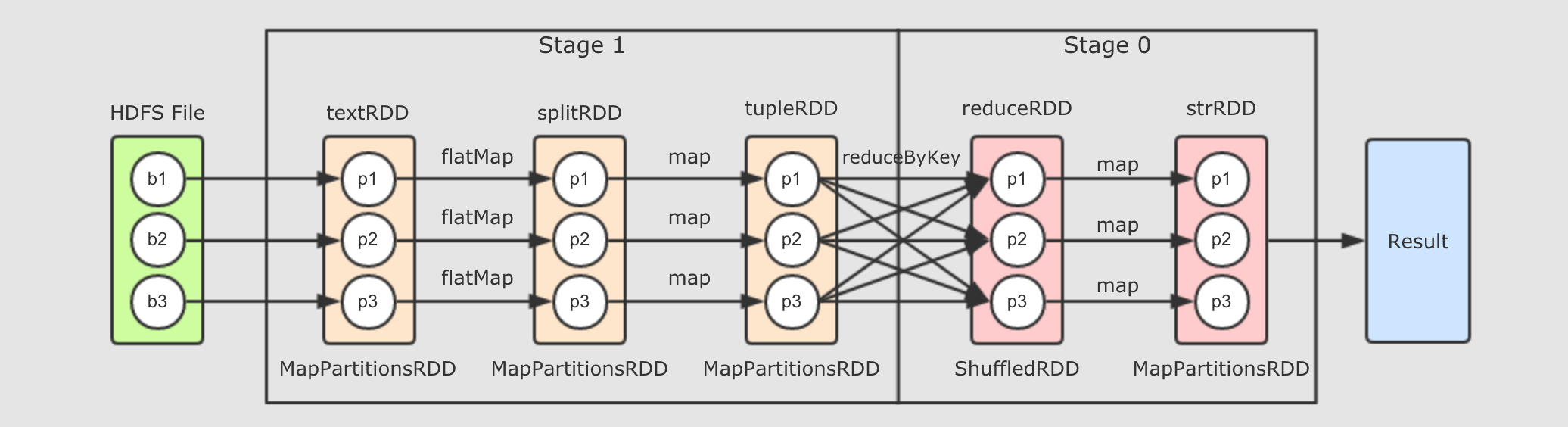
如果放在集群中运行, 通过
WebUI可以查看到如下DAG结构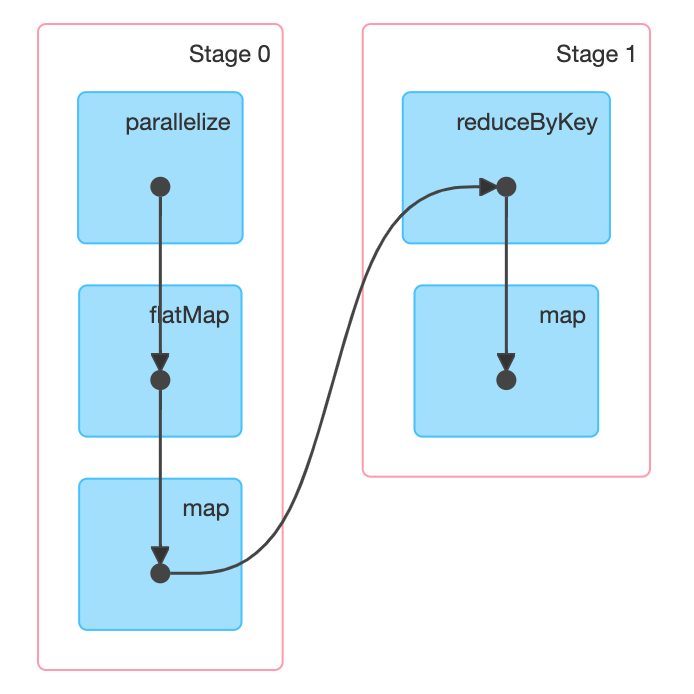
- Step 1: 从
ResultStage开始执行 -
最接近
Result部分的Stage id为 0, 这个Stage被称之为ResultStage由代码可以知道, 最终调用
Action促使整个流程执行的是最后一个RDD,strRDD.collect, 所以当执行RDD的计算时候, 先计算的也是这个RDD - Step 2:
RDD之间是有关联的 -
前面已经知道, 最后一个
RDD先得到执行机会, 先从这个RDD开始执行, 但是这个RDD中有数据吗 ? 如果没有数据, 它的计算是什么? 它的计算是从父RDD中获取数据, 并执行传入的算子的函数简单来说, 从产生
Result的地方开始计算, 但是其RDD中是没数据的, 所以会找到父RDD来要数据, 父RDD也没有数据, 继续向上要, 所以, 计算从Result处调用, 但是从整个逻辑图中的最左边RDD开始, 类似一个递归的过程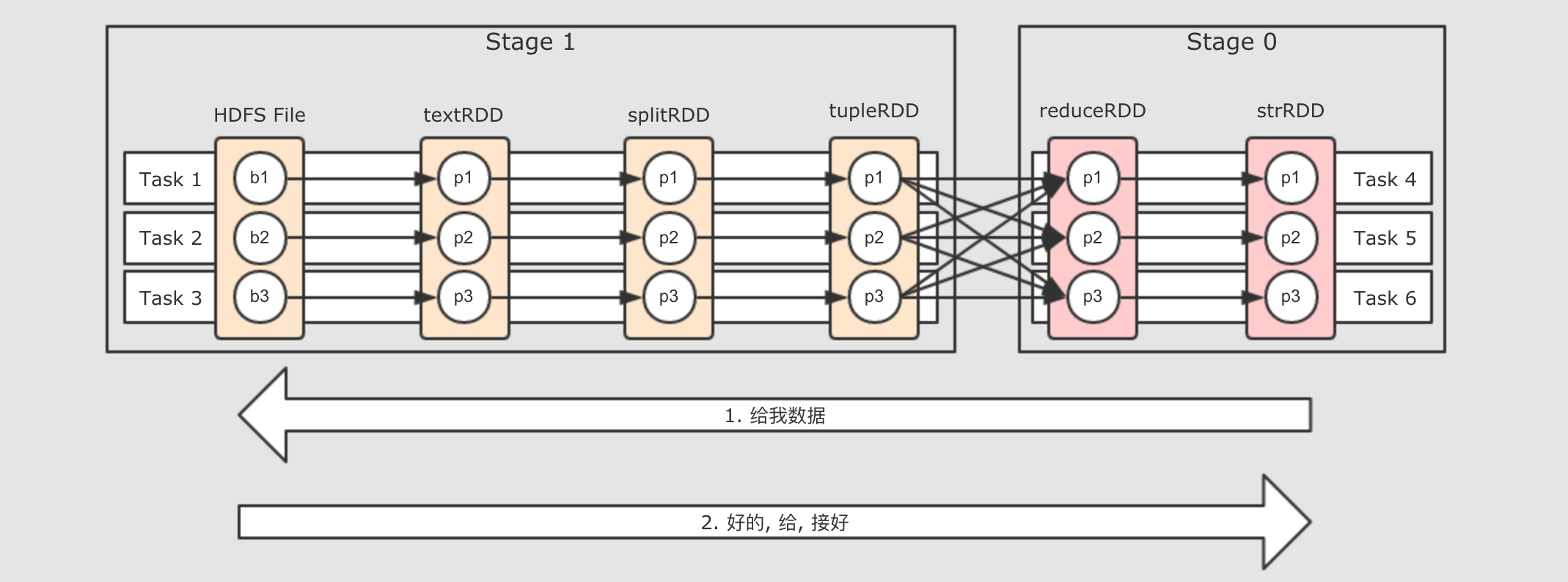
- Step 1: 从
6.3. 调度过程
生成逻辑图和物理图的系统组件
Job和Stage,Task之间的关系如何调度
Job
- 逻辑图
-
是什么 怎么生成 具体怎么生成
val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}")- 逻辑图如何生成
-
上述代码在
Spark Application的main方法中执行, 而Spark Application在Driver中执行, 所以上述代码在Driver中被执行, 那么这段代码执行的结果是什么呢?一段
Scala代码的执行结果就是最后一行的执行结果, 所以上述的代码, 从逻辑上执行结果就是最后一个RDD, 最后一个RDD也可以认为就是逻辑执行图, 为什么呢?例如
rdd2 = rdd1.map(…)中, 其实本质上rdd2是一个类型为MapPartitionsRDD的对象, 而创建这个对象的时候, 会通过构造函数传入当前RDD对象, 也就是父RDD, 也就是调用map算子的rdd1,rdd1是rdd2的父RDD
一个
RDD依赖另外一个RDD, 这个RDD又依赖另外的RDD, 一个RDD可以通过getDependency获得其父RDD, 这种环环相扣的关系, 最终从最后一个RDD就可以推演出前面所有的RDD - 逻辑图是什么, 干啥用
-
逻辑图其实本质上描述的就是数据的计算过程, 数据从哪来, 经过什么样的计算, 得到什么样的结果, 再执行什么计算, 得到什么结果
可是数据的计算是描述好了, 这种计算该如何执行呢?
- 物理图
-
数据的计算表示好了, 该正式执行了, 但是如何执行? 如何执行更快更好更酷? 就需要为其执行做一个规划, 所以需要生成物理执行图
strRDD.collect.foreach(item => println(item))上述代码其实就是最后的一个
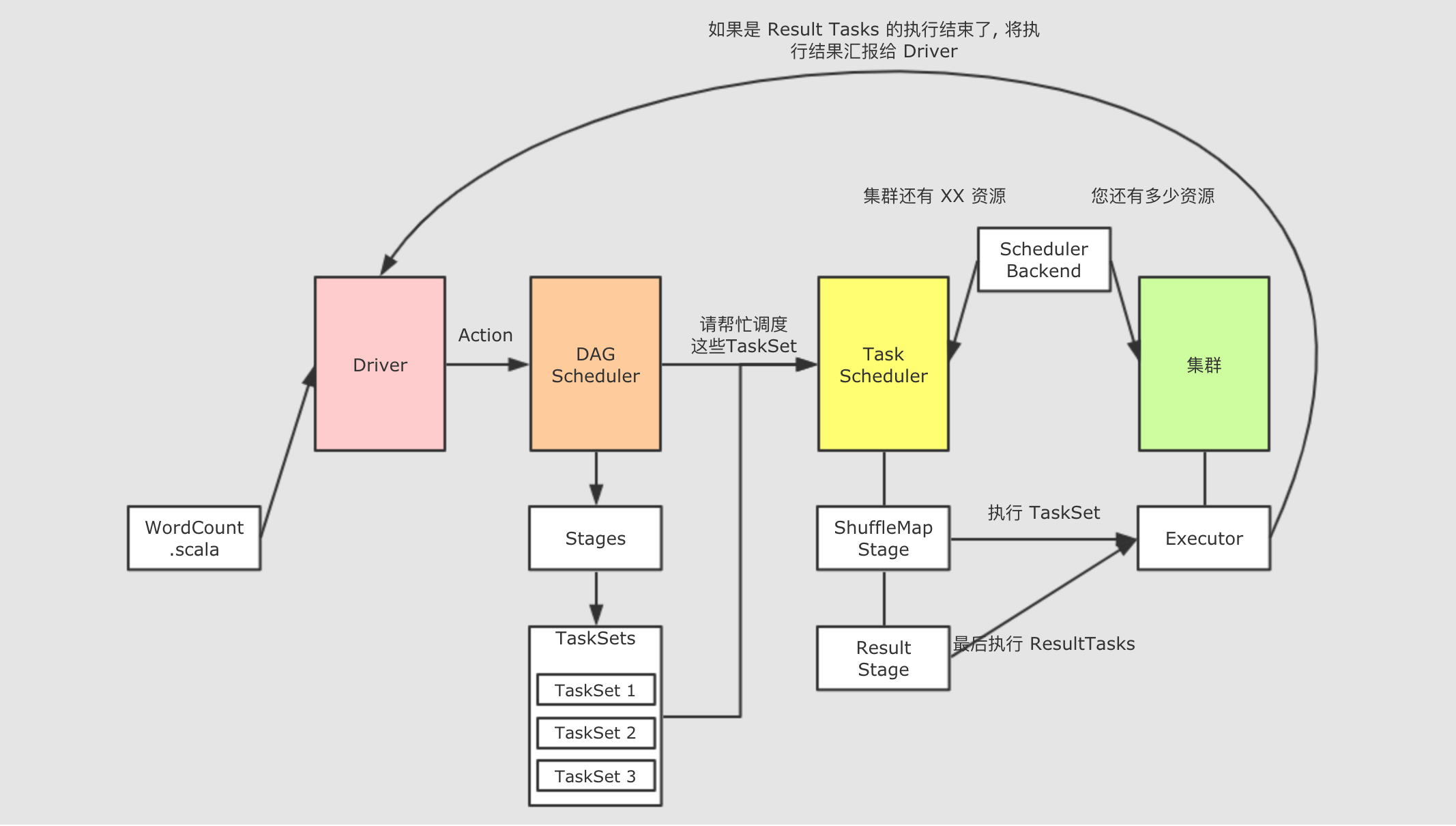
RDD调用了Action方法, 调用Action方法的时候, 会请求一个叫做DAGScheduler的组件,DAGScheduler会创建用于执行RDD的Stage和TaskDAGScheduler是一个由SparkContext创建, 运行在Driver上的组件, 其作用就是将由RDD构建出来的逻辑计划, 构建成为由真正在集群中运行的Task组成的物理执行计划,DAGScheduler主要做如下三件事帮助每个
Job计算DAG并发给TaskSheduler调度确定每个
Task的最佳位置跟踪
RDD的缓存状态, 避免重新计算
从字面意思上来看,
DAGScheduler是调度DAG去运行的,DAG被称作为有向无环图, 其实可以将DAG理解为就是RDD的逻辑图, 其呈现两个特点:RDD的计算是有方向的,RDD的计算是无环的, 所以DAGScheduler也可以称之为RDD Scheduler, 但是真正运行在集群中的并不是RDD, 而是Task和Stage,DAGScheduler负责这种转换 Job是什么 ?-
Job什么时候生成 ?-
当一个
RDD调用了Action算子的时候, 在Action算子内部, 会使用sc.runJob()调用SparkContext中的runJob方法, 这个方法又会调用DAGScheduler中的runJob, 后在DAGScheduler中使用消息驱动的形式创建Job简而言之,
Job在RDD调用Action算子的时候生成, 而且调用一次Action算子, 就会生成一个Job, 如果一个SparkApplication中调用了多次Action算子, 会生成多个Job串行执行, 每个Job独立运作, 被独立调度, 所以RDD的计算也会被执行多次 Job是什么 ?-
如果要将
Spark的程序调度到集群中运行,Job是粒度最大的单位, 调度以Job为最大单位, 将Job拆分为Stage和Task去调度分发和运行, 一个Job就是一个Spark程序从读取 → 计算 → 运行的过程一个
Spark Application可以包含多个Job, 这些Job之间是串行的, 也就是第二个Job需要等待第一个Job的执行结束后才会开始执行
Job和Stage的关系-
Job是一个最大的调度单位, 也就是说DAGScheduler会首先创建一个Job的相关信息, 后去调度Job, 但是没办法直接调度Job, 比如说现在要做一盘手撕包菜, 不可能直接去炒一整颗包菜, 要切好撕碎, 再去炒- 为什么
Job需要切分 ? -
因为
Job的含义是对整个RDD血统求值, 但是RDD之间可能会有一些宽依赖如果遇到宽依赖的话, 两个
RDD之间需要进行数据拉取和复制如果要进行拉取和复制的话, 那么一个
RDD就必须等待它所依赖的RDD所有分区先计算完成, 然后再进行拉取由上得知, 一个
Job是无法计算完整个RDD血统的
- 如何切分 ?
-
创建一个
Stage, 从后向前回溯RDD, 遇到Shuffle依赖就结束Stage, 后创建新的Stage继续回溯. 这个过程上面已经详细的讲解过, 但是问题是切分以后如何执行呢, 从后向前还是从前向后, 是串行执行多个Stage, 还是并行执行多个Stage - 问题一: 执行顺序
-
在图中,
Stage 0的计算需要依赖Stage 1的数据, 因为reduceRDD中一个分区可能需要多个tupleRDD分区的数据, 所以tupleRDD必须先计算完, 所以, 应该在逻辑图中自左向右执行Stage - 问题二: 串行还是并行
-
还是同样的原因,
Stage 0如果想计算,Stage 1必须先计算完, 因为Stage 0中每个分区都依赖Stage 1中的所有分区, 所以Stage 1不仅需要先执行, 而且Stage 1执行完之前Stage 0无法执行, 它们只能串行执行 - 总结
-
一个
Stage就是物理执行计划中的一个步骤, 一个Spark Job就是划分到不同Stage的计算过程Stage之间的边界由Shuffle操作来确定Stage内的RDD之间都是窄依赖, 可以放在一个管道中执行而
Shuffle后的Stage需要等待前面Stage的执行
Stage有两种ShuffMapStage, 其中存放窄依赖的RDDResultStage, 每个Job只有一个, 负责计算结果, 一个ResultStage执行完成标志着整个Job执行完毕
- 为什么
Stage和Task的关系-
前面我们说到
Job无法直接执行, 需要先划分为多个Stage, 去执行Stage, 那么Stage可以直接执行吗?第一点:
Stage中的RDD之间是窄依赖因为
Stage中的所有RDD之间都是窄依赖, 窄依赖RDD理论上是可以放在同一个Pipeline(管道, 流水线)中执行的, 似乎可以直接调度Stage了? 其实不行, 看第二点第二点: 别忘了
RDD还有分区一个
RDD只是一个概念, 而真正存放和处理数据时, 都是以分区作为单位的Stage对应的是多个整体上的RDD, 而真正的运行是需要针对RDD的分区来进行的第三点: 一个
Task对应一个RDD的分区一个比
Stage粒度更细的单元叫做Task,Stage是由Task组成的, 之所以有Task这个概念, 是因为Stage针对整个RDD, 而计算的时候, 要针对RDD的分区假设一个
Stage中有 10 个RDD, 这些RDD中的分区各不相同, 但是分区最多的RDD有 30 个分区, 而且很显然, 它们之间是窄依赖关系那么, 这个
Stage中应该有多少Task呢? 应该有 30 个Task, 因为一个Task计算一个RDD的分区. 这个Stage至多有 30 个分区需要计算总结
一个
Stage就是一组并行的Task集合Task 是 Spark 中最小的独立执行单元, 其作用是处理一个 RDD 分区
一个 Task 只可能存在于一个 Stage 中, 并且只能计算一个 RDD 的分区
- TaskSet
-
梳理一下这几个概念,
Job > Stage > Task,Job 中包含 Stage 中包含 Task而
Stage中经常会有一组Task需要同时执行, 所以针对于每一个Task来进行调度太过繁琐, 而且没有意义, 所以每个Stage中的Task们会被收集起来, 放入一个TaskSet集合中一个
Stage有一个TaskSetTaskSet中Task的个数由Stage中的最大分区数决定
6.3. Shuffle 过程
本章节重点是介绍 Shuffle 的流程, 因为根据 ShuffleWriter 的实现不同, 其过程也不同, 所以前半部分根据默认的存储引擎 SortShuffleWriter 来讲解
后半部分简要介绍一下其它的 ShuffleWriter
Shuffle过程的组件结构-
从整体视角上来看,
Shuffle发生在两个Stage之间, 一个Stage把数据计算好, 整理好, 等待另外一个Stage来拉取
放大视角, 会发现, 其实
Shuffle发生在Task之间, 一个Task把数据整理好, 等待Reducer端的Task来拉取
如果更细化一下,
Task之间如何进行数据拷贝的呢? 其实就是一方Task把文件生成好, 然后另一方Task来拉取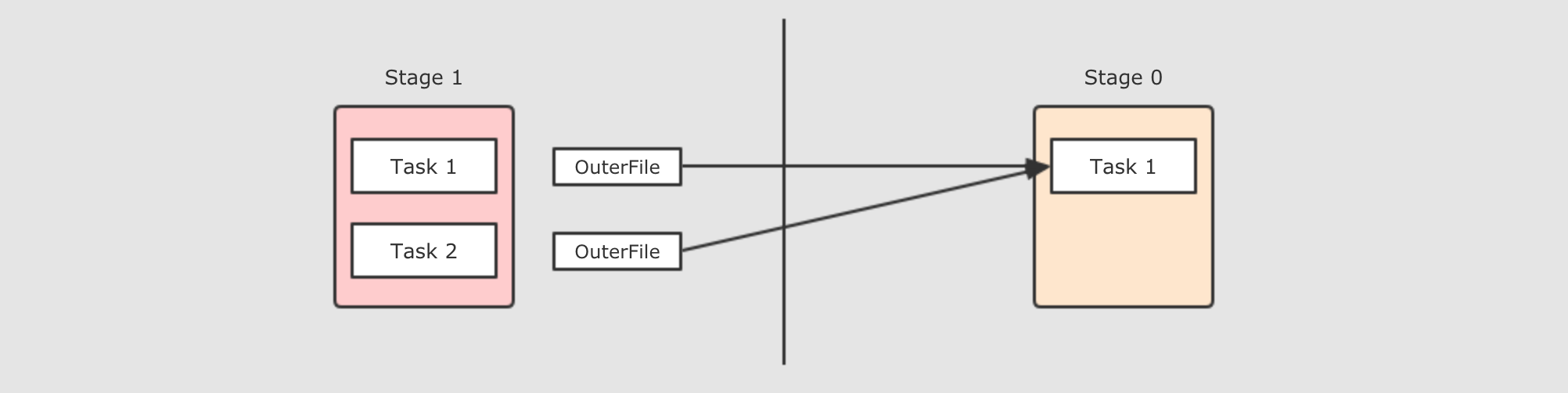
现在是一个
Reducer的情况, 如果有多个Reducer呢? 如果有多个Reducer的话, 就可以在每个Mapper为所有的Reducer生成各一个文件, 这种叫做Hash base shuffle, 这种Shuffle的方式问题大家也知道, 就是生成中间文件过多, 而且生成文件的话需要缓冲区, 占用内存过大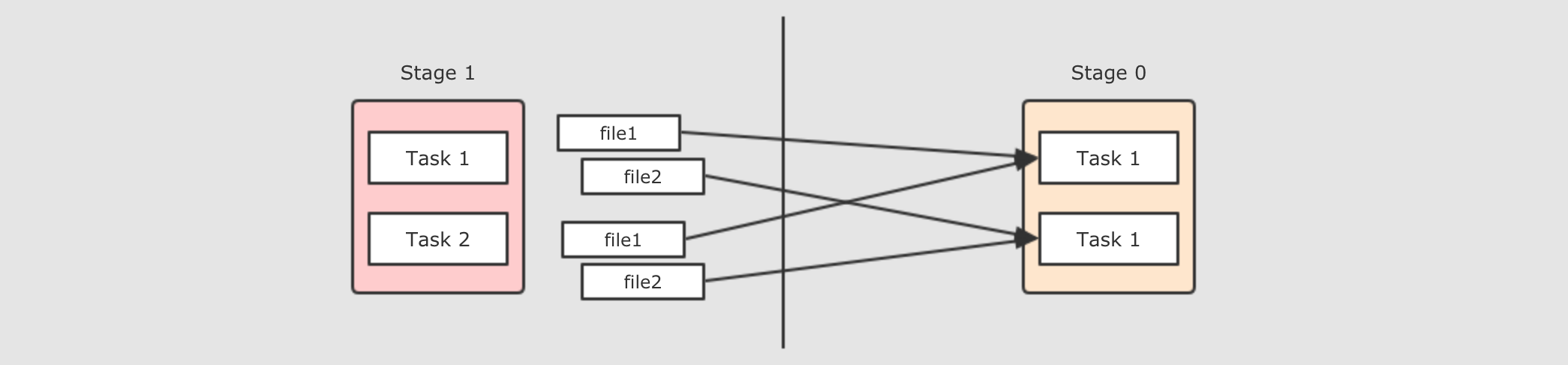
那么可以把这些文件合并起来, 生成一个文件返回, 这种
Shuffle方式叫做Sort base shuffle, 每个Reducer去文件的不同位置拿取数据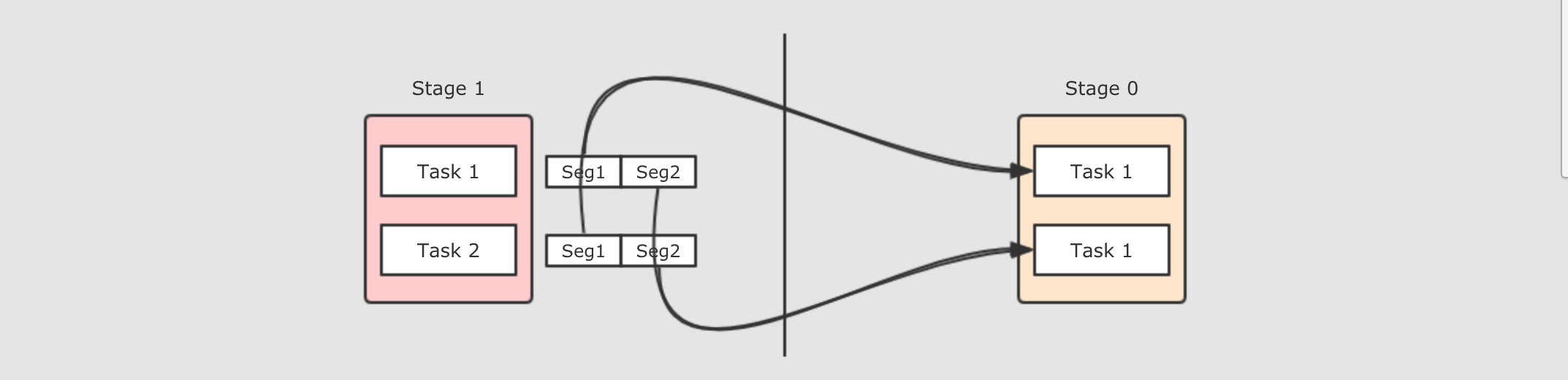
如果再细化一下, 把参与这件事的组件也放置进去, 就会是如下这样
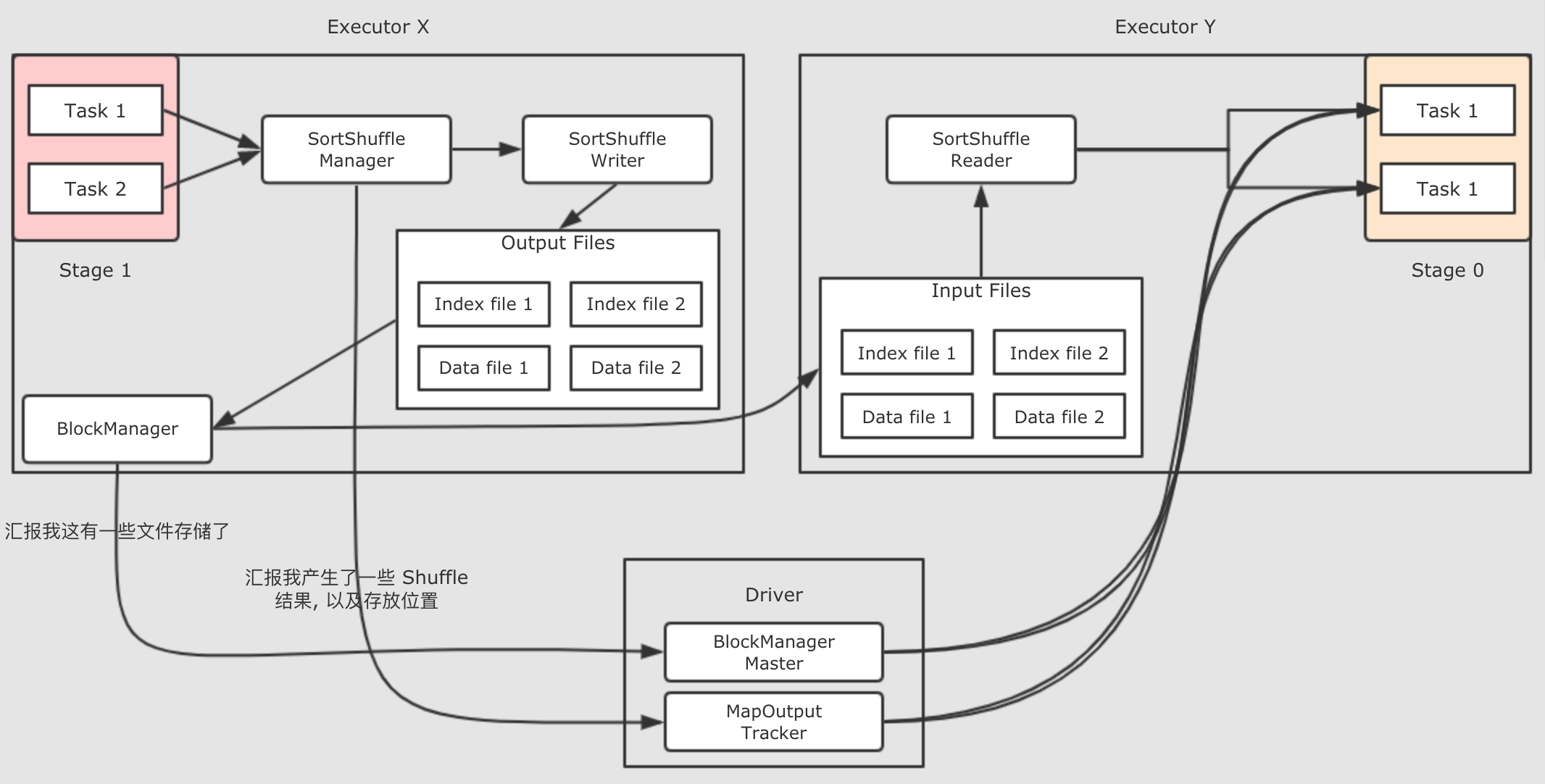
- 有哪些
ShuffleWriter? -
大致上有三个
ShufflWriter,Spark会按照一定的规则去使用这三种不同的WriterBypassMergeSortShuffleWriter这种
Shuffle Writer也依然有Hash base shuffle的问题, 它会在每一个Mapper端对所有的Reducer生成一个文件, 然后再合并这个文件生成一个统一的输出文件, 这个过程中依然是有很多文件产生的, 所以只适合在小量数据的场景下使用Spark有考虑去掉这种Writer, 但是因为结构中有一些依赖, 所以一直没去掉当
Reducer个数小于spark.shuffle.sort.bypassMergeThreshold, 并且没有Mapper端聚合的时候启用这种方式SortShuffleWriter这种
ShuffleWriter写文件的方式非常像MapReduce了, 后面详说当其它两种
Shuffle不符合开启条件时, 这种Shuffle方式是默认的UnsafeShuffleWriter这种
ShuffWriter会将数据序列化, 然后放入缓冲区进行排序, 排序结束后Spill到磁盘, 最终合并Spill文件为一个大文件, 同时在进行内存存储的时候使用了Java得Unsafe API, 也就是使用堆外内存, 是钨丝计划的一部分也不是很常用, 只有在满足如下三个条件时候才会启用
序列化器序列化后的数据, 必须支持排序
没有
Mapper端的聚合Reducer的个数不能超过支持的上限 (2 ^ 24)
SortShuffleWriter的执行过程-
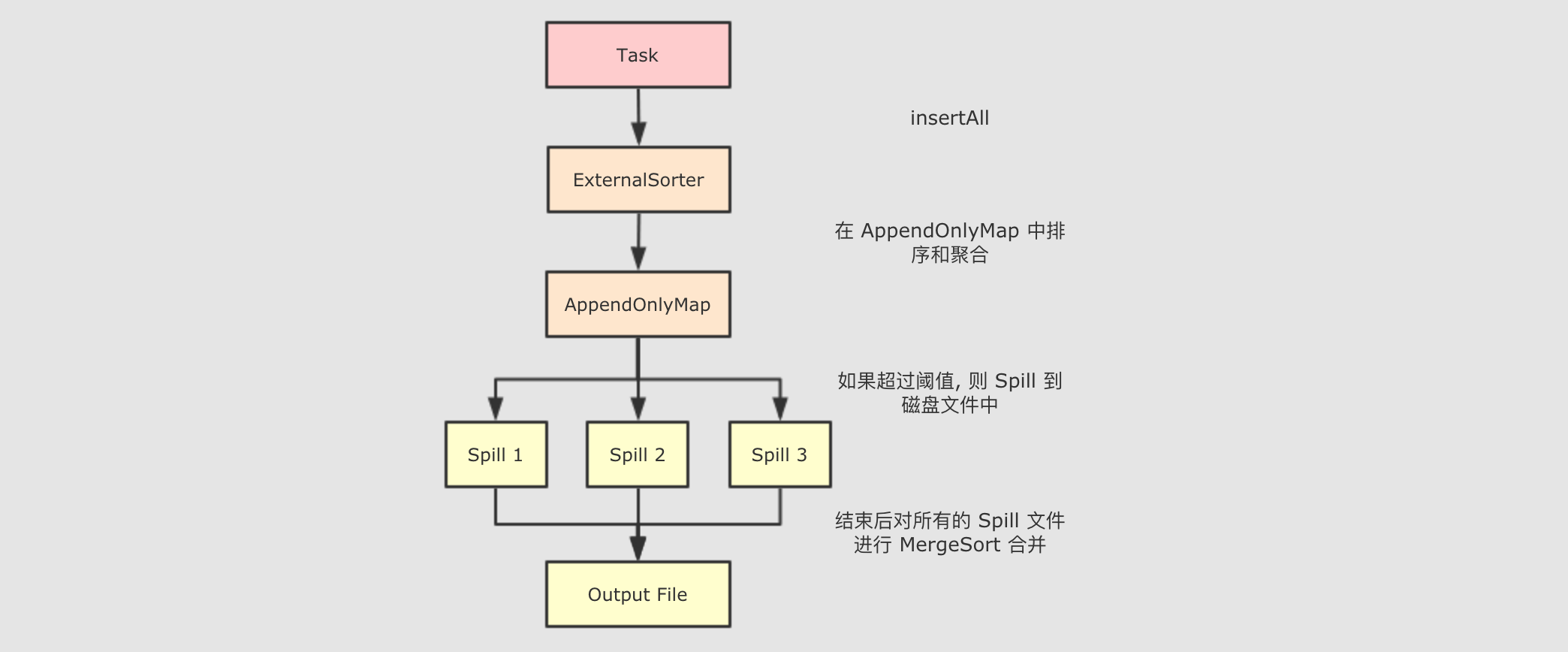
整个
SortShuffleWriter如上述所说, 大致有如下几步首先
SortShuffleWriter在write方法中回去写文件, 这个方法中创建了ExternalSorterwrite中将数据insertAll到ExternalSorter中在
ExternalSorter中排序如果要聚合, 放入
AppendOnlyMap中, 如果不聚合, 放入PartitionedPairBuffer中在数据结构中进行排序, 排序过程中如果内存数据大于阈值则溢写到磁盘
使用
ExternalSorter的writePartitionedFile写入输入文件将所有的溢写文件通过类似
MergeSort的算法合并将数据写入最终的目标文件中
7. RDD 的分布式共享变量
理解闭包以及 Spark 分布式运行代码的根本原理
理解累加变量的使用场景
理解广播的使用场景
闭包是一个必须要理解, 但是又不太好理解的知识点, 先看一个小例子
@Test
def test(): Unit = {
val areaFunction = closure()
val area = areaFunction(2)
println(area)
}
def closure(): Int => Double = {
val factor = 3.14
val areaFunction = (r: Int) => math.pow(r, 2) * factor
areaFunction
}上述例子中, `closure`方法返回的一个函数的引用, 其实就是一个闭包, 闭包本质上就是一个封闭的作用域, 要理解闭包, 是一定要和作用域联系起来的.
- 能否在
test方法中访问closure定义的变量? -
@Test
def test(): Unit = {
println(factor)
} def closure(): Int => Double = {
val factor = 3.14
} - 有没有什么间接的方式?
-
@Test
def test(): Unit = {
val areaFunction = closure()
areaFunction()
} def closure(): () => Unit = {
val factor = 3.14
val areaFunction = () => println(factor)
areaFunction
} - 什么是闭包?
-
val areaFunction = closure()
areaFunction()通过
closure返回的函数areaFunction就是一个闭包, 其函数内部的作用域并不是test函数的作用域, 这种连带作用域一起打包的方式, 我们称之为闭包, 在 Scala 中Scala 中的闭包本质上就是一个对象, 是 FunctionX 的实例*
sc.textFile("dataset/access_log_sample.txt")
.flatMap(item => item.split(""))
.collect()上述这段代码中, flatMap 中传入的是另外一个函数, 传入的这个函数就是一个闭包, 这个闭包会被序列化运行在不同的 Executor 中
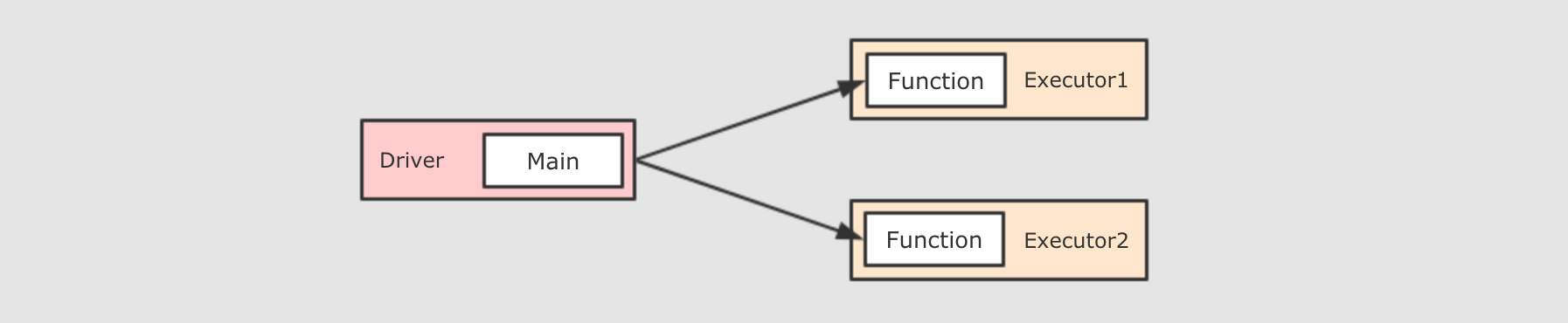
class MyClass {
val field = "Hello"
def doStuff(rdd: RDD[String]): RDD[String] = {
rdd.map(x => field + x)
}
}这段代码中的闭包就有了一个依赖, 依赖于外部的一个类, 因为传递给算子的函数最终要在 Executor 中运行, 所以需要 序列化MyClass 发给每一个 Executor, 从而在 Executor 访问 MyClass 对象的属性

闭包就是一个封闭的作用域, 也是一个对象
Spark 算子所接受的函数, 本质上是一个闭包, 因为其需要封闭作用域, 并且序列化自身和依赖, 分发到不同的节点中运行
7.1. 累加器
- 一个小问题
-
var count = 0 val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config) sc.parallelize(Seq(1, 2, 3, 4, 5))
.foreach(count += _) println(count)上面这段代码是一个非常错误的使用, 请不要仿照, 这段代码只是为了证明一些事情
先明确两件事,
var count = 0是在 Driver 中定义的,foreach(count += _)这个算子以及传递进去的闭包运行在 Executor 中这段代码整体想做的事情是累加一个变量, 但是这段代码的写法却做不到这件事, 原因也很简单, 因为具体的算子是闭包, 被分发给不同的节点运行, 所以这个闭包中累加的并不是 Driver 中的这个变量
- 全局累加器
-
Accumulators(累加器) 是一个只支持
added(添加) 的分布式变量, 可以在分布式环境下保持一致性, 并且能够做到高效的并发.原生 Spark 支持数值型的累加器, 可以用于实现计数或者求和, 开发者也可以使用自定义累加器以实现更高级的需求
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config) val counter = sc.longAccumulator("counter") sc.parallelize(Seq(1, 2, 3, 4, 5))
.foreach(counter.add(_)) // 运行结果: 15
println(counter.value)注意点:
Accumulator 是支持并发并行的, 在任何地方都可以通过
add来修改数值, 无论是 Driver 还是 Executor只能在 Driver 中才能调用
value来获取数值
在 WebUI 中关于 Job 部分也可以看到 Accumulator 的信息, 以及其运行的情况
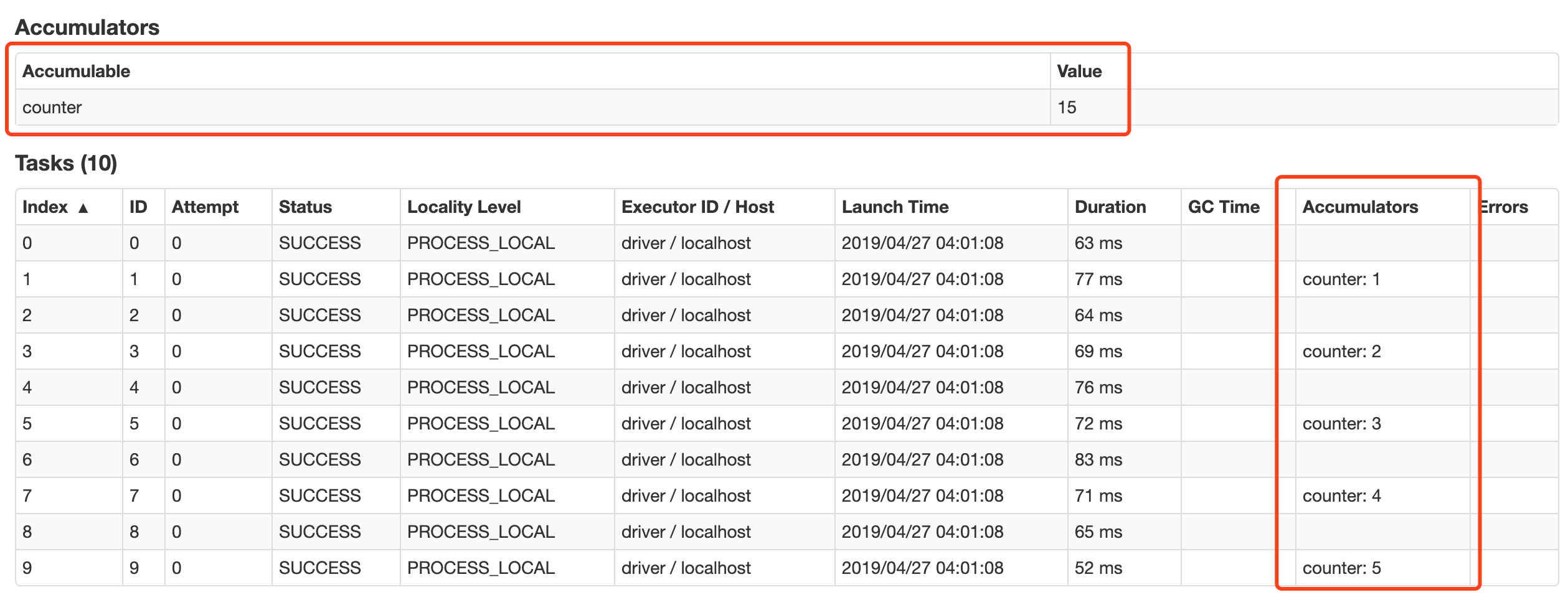
累计器件还有两个小特性, 第一, 累加器能保证在 Spark 任务出现问题被重启的时候不会出现重复计算. 第二, 累加器只有在 Action 执行的时候才会被触发.
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config) val counter = sc.longAccumulator("counter") sc.parallelize(Seq(1, 2, 3, 4, 5))
.map(counter.add(_)) // 这个地方不是 Action, 而是一个 Transformation // 运行结果是 0
println(counter.value) - 自定义累加器
-
开发者可以通过自定义累加器来实现更多类型的累加器, 累加器的作用远远不只是累加, 比如可以实现一个累加器, 用于向里面添加一些运行信息
class InfoAccumulator extends AccumulatorV2[String, Set[String]] {
private val infos: mutable.Set[String] = mutable.Set() override def isZero: Boolean = {
infos.isEmpty
} override def copy(): AccumulatorV2[String, Set[String]] = {
val newAccumulator = new InfoAccumulator()
infos.synchronized {
newAccumulator.infos ++= infos
}
newAccumulator
} override def reset(): Unit = {
infos.clear()
} override def add(v: String): Unit = {
infos += v
} override def merge(other: AccumulatorV2[String, Set[String]]): Unit = {
infos ++= other.value
} override def value: Set[String] = {
infos.toSet
}
} @Test
def accumulator2(): Unit = {
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config) val infoAccumulator = new InfoAccumulator()
sc.register(infoAccumulator, "infos") sc.parallelize(Seq("1", "2", "3"))
.foreach(item => infoAccumulator.add(item)) // 运行结果: Set(3, 1, 2)
println(infoAccumulator.value) sc.stop()
}注意点:
可以通过继承
AccumulatorV2来创建新的累加器有几个方法需要重写
reset 方法用于把累加器重置为 0
add 方法用于把其它值添加到累加器中
merge 方法用于指定如何合并其他的累加器
value需要返回一个不可变的集合, 因为不能因为外部的修改而影响自身的值
7.2. 广播变量
理解为什么需要广播变量, 以及其应用场景
能够通过代码使用广播变量
- 广播变量的作用
-
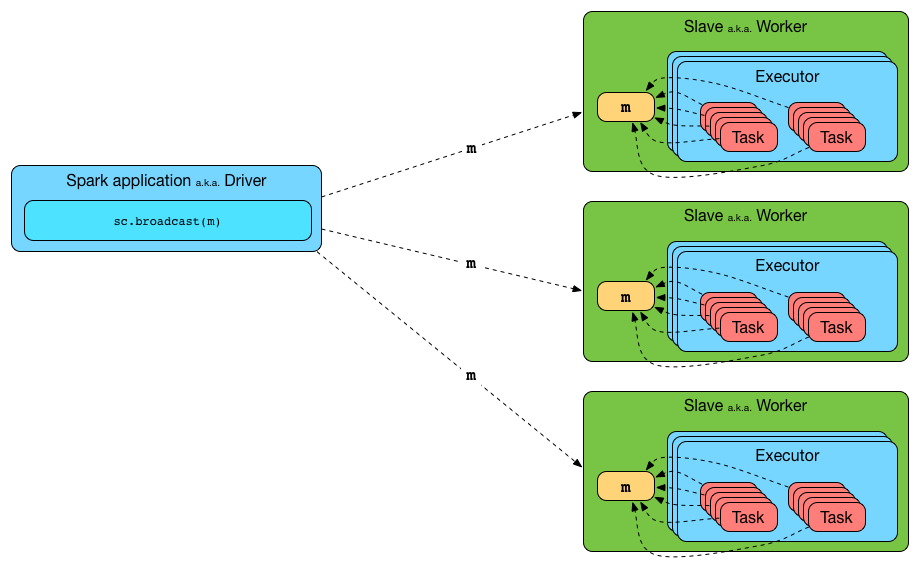
广播变量允许开发者将一个
Read-Only的变量缓存到集群中每个节点中, 而不是传递给每一个 Task 一个副本.集群中每个节点, 指的是一个机器
每一个 Task, 一个 Task 是一个 Stage 中的最小处理单元, 一个 Executor 中可以有多个 Stage, 每个 Stage 有多个 Task
所以在需要跨多个 Stage 的多个 Task 中使用相同数据的情况下, 广播特别的有用
- 广播变量的API
-
方法名 描述 id唯一标识
value广播变量的值
unpersist在 Executor 中异步的删除缓存副本
destroy销毁所有此广播变量所关联的数据和元数据
toString字符串表示
- 使用广播变量的一般套路
-
可以通过如下方式创建广播变量
val b = sc.broadcast(1)如果 Log 级别为 DEBUG 的时候, 会打印如下信息
DEBUG BlockManager: Put block broadcast_0 locally took 430 ms
DEBUG BlockManager: Putting block broadcast_0 without replication took 431 ms
DEBUG BlockManager: Told master about block broadcast_0_piece0
DEBUG BlockManager: Put block broadcast_0_piece0 locally took 4 ms
DEBUG BlockManager: Putting block broadcast_0_piece0 without replication took 4 ms创建后可以使用
value获取数据b.value获取数据的时候会打印如下信息
DEBUG BlockManager: Getting local block broadcast_0
DEBUG BlockManager: Level for block broadcast_0 is StorageLevel(disk, memory, deserialized, 1 replicas)广播变量使用完了以后, 可以使用
unpersist删除数据b.unpersist删除数据以后, 可以使用
destroy销毁变量, 释放内存空间b.destroy销毁以后, 会打印如下信息
DEBUG BlockManager: Removing broadcast 0
DEBUG BlockManager: Removing block broadcast_0_piece0
DEBUG BlockManager: Told master about block broadcast_0_piece0
DEBUG BlockManager: Removing block broadcast_0 - 使用
value方法的注意点 -
方法签名
value: T在
value方法内部会确保使用获取数据的时候, 变量必须是可用状态, 所以必须在变量被destroy之前使用value方法, 如果使用value时变量已经失效, 则会爆出以下错误org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27)
at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144)
at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:69)
... 48 elided - 使用
destroy方法的注意点 -
方法签名
destroy(): Unitdestroy方法会移除广播变量, 彻底销毁掉, 但是如果你试图多次destroy广播变量, 则会爆出以下错误org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27)
at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144)
at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:107)
at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:98)
... 48 elided
- 广播变量的使用场景
-
假设我们在某个算子中需要使用一个保存了项目和项目的网址关系的
Map[String, String]静态集合, 如下val pws = Map("Apache Spark" -> "http://spark.apache.org/", "Scala" -> "http://www.scala-lang.org/") val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pws).collect上面这段代码是没有问题的, 可以正常运行的, 但是非常的低效, 因为虽然可能
pws已经存在于某个Executor中了, 但是在需要的时候还是会继续发往这个Executor, 如果想要优化这段代码, 则需要尽可能的降低网络开销可以使用广播变量进行优化, 因为广播变量会缓存在集群中的机器中, 比
Executor在逻辑上更 "大"val pwsB = sc.broadcast(pws)
val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pwsB.value).collect上面两段代码所做的事情其实是一样的, 但是当需要运行多个
Executor(以及多个Task) 的时候, 后者的效率更高 - 扩展
-
正常情况下使用 Task 拉取数据的时候, 会将数据拷贝到 Executor 中多次, 但是使用广播变量的时候只会复制一份数据到 Executor 中, 所以在两种情况下特别适合使用广播变量
一个 Executor 中有多个 Task 的时候
一个变量比较大的时候
而且在 Spark 中还有一个约定俗称的做法, 当一个 RDD 很大并且还需要和另外一个 RDD 执行
join的时候, 可以将较小的 RDD 广播出去, 然后使用大的 RDD 在算子map中直接join, 从而实现在 Map 端joinval acMap = sc.broadcast(myRDD.map { case (a,b,c,b) => (a, c) }.collectAsMap)
val otherMap = sc.broadcast(myOtherRDD.collectAsMap) myBigRDD.map { case (a, b, c, d) =>
(acMap.value.get(a).get, otherMap.value.get(c).get)
}.collect一般情况下在这种场景下, 会广播 Map 类型的数据, 而不是数组, 因为这样容易使用 Key 找到对应的 Value 简化使用
广播变量用于将变量缓存在集群中的机器中, 避免机器内的 Executors 多次使用网络拉取数据
广播变量的使用步骤: (1) 创建 (2) 在 Task 中获取值 (3) 销毁
Update(Stage4):Spark原理_运行过程_高级特性的更多相关文章
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
- Python笔记_第一篇_面向过程_第一部分_2.内存详解
Python的很多教材中并没有讲内存方面的知识,但是内存的知识非常重要,对于计算机工作原理和方便理解编程语言是非常重要的,尤其是小白,因此需要把这一方面加上,能够更加深入的理解编程语言.这里引用了C语 ...
- Jmeter(三十六)_运行过程中改变负载
顾名思义,jmeter在做性能测试时,可以在不停止脚本的情况下修改负载压力,达到期望的测试效果.我们将通过Constant Throughput Timer(吞吐量计时器)和Beanshell服务器来 ...
- Python笔记_第一篇_面向过程_第一部分_9.Ubuntu基础操作
第一部分 Ubuntu简介 Ubuntu(乌班图)是一个机遇Debian的以桌面应用为主的Linux操作系统,据说其名称来自非洲南部祖鲁语或科萨语的“Ubuntu”一词,意思是“人性”.“我的存在 ...
- Python笔记_第一篇_面向过程_第一部分_3.进制、位运算、编码
通过对内存这一个部分的讲解,对编程会有一个相对深入的认识.数据结构是整个内存的一个重要内容,那么关于数据结构这方面的问题还需要对进制.位运算.编码这三个方面再进行阐述一下.前面说将的数据结构是从逻辑上 ...
- Python笔记_第一篇_面向过程_第一部分_6.语句的嵌套
学完条件控制语句和循环控制语句后,在这里就会把“语言”的精妙之处进行讲解,也就是语句的嵌套.我们在看别人代码的时候总会对一些算法拍案叫绝,里面包含精妙和精密的逻辑分析.语句的嵌套也就是在循环体内可以嵌 ...
- Python笔记_第二篇_面向过程_第二部分_2.路径、栈和队列、内存修改
这一部分分三个主题进行讲解,主要为后面的模块.包.第三方库的概念补充一些相关的内容. 1. 路径(Path): 相对路径和绝对路径. 举例1:我们先导入一个os库(模块)来观察一下路径 import ...
- Python笔记_第二篇_面向过程_第二部分_1.函数
函数:这个词属于一个数学概念,在编程语言借鉴了这个概念,表现形式是一段程序代码的组合,也叫“程序集”.有过编程基础的人很容易理解这个概念,当我们编写程序越来越多的时候,程序设计大师们会把散乱的程序进行 ...
- Python笔记_第一篇_面向过程_第一部分_6.条件控制语句(if)
Python正如其他语言一样存在两种常用的逻辑判断体(也叫结构化程序设计).所谓逻辑判断体是通过你想要完成的编程思路,通过在逻辑判断体中的相互判断和作用得到你想要的结果.逻辑判断体也叫控制语句,Pyt ...
随机推荐
- Form DataGridView绑定BindingSource的几种方式
本文链接:https://blog.csdn.net/qq_15138169/article/details/83341076 在WinForm的开发中,ListView和DataGridView应用 ...
- 线性筛-euler,强大O(n)
欧拉函数是少于或等于n的数中与n互质的数的数目 φ(1)=1(定义) 类似与莫比乌斯函数,基于欧拉函数的积性 φ(xy)=φ(x)φ(y) 由唯一分解定理展开显然,得证 精髓在于对于积性的应用: ){ ...
- new一个对象做了哪些操作
网上其实有很多说new关键字做了哪些操作,读过之后就忘了,这里以自己的理解做一个简单的记录. function Naji () { this.skulk = function () { return ...
- 初学mysql数据库
package com.conn; import java.sql.Connection; import java.sql.DriverManager; public class Conn { pub ...
- php 裁剪图片并处理png图片背景变黑
/*TODO 图片裁剪*/ function img_cutting($file_old,$file_new,$h,$w){ $image = $file_old; // 原图 $dir = 'xxx ...
- selenium+python自动化用例登陆界面模板
一.基本逻辑 1.自动填写用户名和密码登录成功后跳转到相应页面 2.验证相应页面的url与给定的url是否一致,如果一致则测试通过,如果不一致则不通过 二.以jenkins登陆界面为例,代码如下 fr ...
- 理解ASP.NET Core验证模型 Claim, ClaimsIdentity, ClaimsPrincipal
Claim, ClaimsIdentity, ClaimsPrincipal: Claim:姓名:xxx,领证日期:xxx ClaimsIdentity:身份证/驾照 ClaimsPrincipal: ...
- C语言字符串类型转换为double浮点数类型
#include <stdio.h>#include <stdlib.h>char *record; double re = atof(record); 使用 atof()函数 ...
- Linux上临时路由、永久路由配置
Linux下查看路由条目 查看路由表命令 route -n 示例 [root@cobbler_vm ~]# route -n Kernel IP routing table Destination G ...
- C#面向对象三大特性:封装
什么是封装 定义:把一个或多个项目封闭在一个物理的或者逻辑的包中.在面向对象程序设计方法论中,封装是为了防止对实现细节的访问. 封装的优点 1. 隔离性,安全性.被封装后的对象(这里的对象是泛指代码的 ...