PHP如何实现百万级数据导出
公司目前有一个需求,需要对一个日增量在20万+数据量的数据表中的数据进行可自定义条件筛选的导出数据,该功能需要对多个部门进行开发使用,要保证功能可用的前提下,尽量优化体验。
首先介绍一下当前可利用的资源:
1、MySql - 一主库双从库。
2、分布式服务器集群,选择其中一台中型机作为脚本执行载体。
3、文件系统 - 可以支持上传大数据量文件。
4、编程语言PHP,说实话PHP不太适合来干这个事情。
技术难点:
1、数据太大,对服务器配置要求较高,导出过程中涉及数据的处理(例如各种ID转换名称等操作,我们这次需求这种太多了~~非常的坑)对内存消耗很大,其次涉及到文件压缩,因此对CPU要求较高。
2、因为是跨系统部署,如果走接口,数据量随随便便上百M,传输速度太慢(项目是对外网开放的,然后数据只允许内网访问),那么该如何解决?
3、数据安全性较高,需要对所有导出进行记录,那么如何保证数据安全?
| 技术方案
第一步:设计数据库,对所有导出任务进行实时记录,也可以采用redis,为了方便数据的持久化,我最终采用了mysql数据库的方案。表结构具体包括:ID、用户ID、用户名、发起请求时间、导出具体的参数(包括各个维度的参数选择等,具体根据自身业务而定),任务是否正在处理标识(防止任务多次被处理),导出是否成功标识(可以与前一个用一个字段区分),删除标识等(假删除,便于记录用户实际操作日志)。
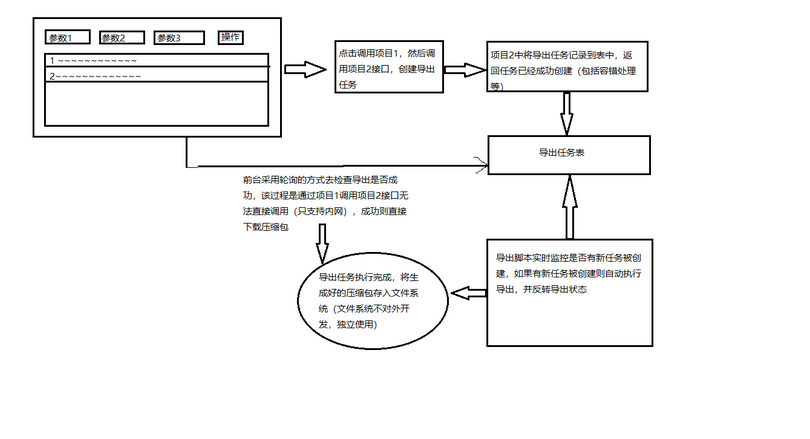
第二步:前台界面编写,具体包括参数选择、导出记录列表等,作用:触发导出任务创建,记录于导出表中,状态:待处理。
第三步:编写导出脚本对任务进行监控并处理,如果有导出任务自动对其执行导出操作。
这里有一个小问题:为什么不在前台触发任务的时候直接执行导出,而是有单独的脚本来执行导出呢?这就是现实业务导致的,因为我们对外开放的机器中有一些是配置很低的,为了保证导出的成功率,我们需要一台配置较高的机器来独立执行导出任务。
| 导出流程
具体流程参考下图,自己画的凑合看吧~~~哈哈哈
代码实现
这里主要着重介绍一下导出脚本的代码,其他步骤的代码根据自己的业务自行编写就可以了。
注意:因为数据量过大~一次性导出可想而知是不合理的,所以我使用了分页导出的形式~
首先查询数据总条数、然后通过每页导出的条数来计算具体导出的页数~
# 获取数据总条数
$dataCount = Data_ExportModel::getExportZipTotalCount($params);
$dataCount = $dataCount[0]['count_num']; # csv
# 输出Excel文件头,可把user.csv换成你要的文件名
$mark = '/tmp/export'; $stepLen = 20000;//每次只从数据库取100000条以防变量缓存太大
# 每隔$limit行,刷新一下输出buffer,不要太大,也不要太小
$limit = 20000;
$maxFileCount = 1000000;
# buffer计数器
$cnt = 0;
$head = self::initColumnDataV2(); // 表头部分根据自身业务自行调整
$fileNameArr = array();
$salesStatisticsData = array();
$startLimitId = 0;
首次导出的每页条数我定的10万条,后来发现对内存消耗过大,改成了两万条,这样的导出速度会慢一点,建议五万条比较适中一点。
for ($j = 0; $j < ceil($dataCount / $maxFileCount); $j++) {
$startSelect = ceil($maxFileCount / $stepLen)*$j;
$fileCsvName = $mark . '_'.$j*$maxFileCount.'_' . ($j+1)*$maxFileCount . '.csv';
$fp = fopen($fileCsvName, 'w'); //生成临时文件
$fileNameArr[] = $fileCsvName;
# 将数据通过fputcsv写到文件句柄
fputcsv($fp, $head);
for ($i = 0; $i < 50; $i++) { // 单个文件支持100万数据条数
$startNum = $j*$maxFileCount + $i*$limit;
if ($startNum > $dataCount) {
break; // 跳出循环
}
# 查询数据
$dataSource = Data_ExportModel::getExportZipTotalInfo($params, $startNum, $stepLen, $startLimitId);
$endMicroTime = microtime(true);
printf("\n[%s -> %s] Begin Time : %s, End Time : %s, Total Count : %s, CostTime: %s.\n",
__CLASS__, __FUNCTION__, $params['begin_date'], $params['end_date'], count($dataSource), ($endMicroTime - $startMicroTime));
if (empty($dataSource)) {
continue;
}
$endMicroTime = microtime(true);
foreach ($dataSource as $_key => $_data) {
$cnt++;
if ($limit == $cnt) {
# 刷新一下输出buffer,防止由于数据过多造成问题
ob_flush();
flush();
$cnt = 0;
}
# 数据处理部分,根据自身业务自行定义,注意中文转码
$salesStatisticsData['name'] = iconv('utf-8', 'GB18030', $salesStatisticsData['c_name']);
fputcsv($fp, $salesStatisticsData);
}
}
fclose($fp); # 每生成一个文件关闭
}
# 进行多文件压缩
$zip = new ZipArchive();
$number = rand(1000,9999);
$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number. ".zip";
$zip->open($filename, ZipArchive::CREATE); //打开压缩包
foreach ($fileNameArr as $file) {
$zip->addFile($file, basename($file)); //向压缩包中添加文件
}
$zip->close(); //关闭压缩包
if (!file_exists($filename)) {
// 首次执行检查生成的压缩文件是否存在失败,进行二次尝试。。。
$endMicroTime = microtime(true);
# 进行二次多文件压缩
$number = rand(1000,9999);
$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number. ".zip";
if (file_exists($filename)) {
unlink($filename);
}
$zip->open($filename, ZipArchive::CREATE); //打开压缩包
foreach ($fileNameArr as $file) {
$zip->addFile($file, basename($file)); //向压缩包中添加文件
}
$zip->close(); //关闭压缩包
}
if (file_exists($filename)) {
$content = file_get_contents($filename);
// 解决读取文件偶尔出现失败的问题,第一读出为空则尝试第二次读取
$forNum = 0;
while (!$content) {
$forNum++;
@$content = file_get_contents($filename);
if ($forNum > 10) {
break; // 防止出现异常情况导致死循环,最多重试10次
}
}
} else {
$endMicroTime = microtime(true);
# 删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {
if (is_file($file)) {
unlink($file);
}
}
// 记录错误日志并且报警
return false;
}
# 删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {
if (is_file($file)) {
unlink($file);
}
}
最后将生成好的文件存入文件系统,上传成功之后反转导出状态,前台检测到导出成功自动进行下载即可
https://blog.csdn.net/bk_guo/article/details/81947010
PHP如何实现百万级数据导出的更多相关文章
- poi实现百万级数据导出
注意使用 SXSSFWorkbook 此类在构造表格和处理行高的时候效率极高,刚开始时我使用的 XSSFWorkbook 就出现构造表格效率极低,一万行基本需要3秒左右,那当导出百万级数据就慢的要死啦 ...
- PHP百万级数据导出方案(多csv文件压缩)
本文转自网络仅供学习之用 概述: 最近公司项目要求把数据除了页面输出也希望有导出功能,虽然之前也做过几个导出功能,但这次数据量相对比较大,差不多一天数据就20W条,要求导7天或者30天,那么数据量就轻 ...
- PHP 百万级数据导出方案(多 CSV 文件压缩)
ps:来源 :https://laravel-china.org/articles/15944/php-million-level-data-export-scheme-multi-csv-file- ...
- Mysql百万级数据索引重新排序
参考https://blog.csdn.net/pengshuai007/article/details/86021689中思路解决自增id重排 方式一 alter table `table_name ...
- 实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- 【转 】实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(37)-文章发布系统④-百万级数据和千万级数据简单测试
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(37)-文章发布系统④-百万级数据和千万级数据简单测试 系列目录 我想测试EF在一百万条数据下的显示时间! ...
- EF查询百万级数据的性能测试--多表连接复杂查询
相关文章:EF查询百万级数据的性能测试--单表查询 一.起因 上次做的是EF百万级数据的单表查询,总结了一下,在200w以下的数据量的情况(Sql Server 2012),EF是可以使用,但是由于 ...
- Sql Server中百万级数据的查询优化
原文:Sql Server中百万级数据的查询优化 万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考 ...
随机推荐
- linux7查看时间同步服务器的匹配源
当服务器时间与设定好的同步时间源的时间有差异的时候,一般都需要先查看本机的时间同步服务功能是否在正常的运转,以及同步的时间源是哪里,在这里为大家提供一个检查时间用的命令. linux/centos 7 ...
- Gulp执行预处理
1. 在项目中安装 gulp-sass插件来编译Sass npm install gulp-sass --save-dev 2. 在gulpfile.js中编写 var gulp = require( ...
- IDEA使用maven插件打jar包流程
idea使用maven插件打jar包步骤以及遇到的问题 idea自带了maven工具,idea右边点击maven选项: 一.在pom中添加插件,直接复制就好,如下选项 <plugin> & ...
- CodeForces祝贺上紫
还是靠手速了. 不少比赛,经常差几分钟/一个细节就能AC一道比较难的题目. 加油! P.S 只能当成休闲性质,不能再当成正业了.迈向科研...
- CSS四种定位及应用
定位(position) 如果,说浮动, 关键在一个 “浮” 字上面, 那么 我们的定位,关键在于一个 “位” 上. PS: 定位是我们CSS算是数一数二难点的了,但是,你务必要学好它,我们CSS离不 ...
- Ruby 数据类型
Ruby 数据类型 本章节我们将为大家介绍 Ruby 的基本数据类型. Ruby支持的数据类型包括基本的Number.String.Ranges.Symbols,以及true.false和nil这几个 ...
- thinkphp Widget扩展
Widget扩展一般用于页面组件的扩展.大理石平台规格 举个例子,我们在页面中实现一个分类显示的Widget,首先我们要定义一个Widget控制器层 CateWidget,如下: namespace ...
- Kafka命令行操作
Kafka命令行操作 1)查看当前服务器中的所有topic [bingo@hadoop101 kafka]$ bin/kafka-topics.sh --list --zookeeper hadoop ...
- 关于C++里set_intersection(取集合交集)、set_union(取集合并集)、set_difference(取集合差集)等函数的使用总结
文章转载自https://blog.csdn.net/zangker/article/details/22984803 set里面有set_intersection(取集合交集).set_union( ...
- [课后作业] 第001讲:我和Python的第一次亲密接触 | 课后测试题的答案
0. Python 是什么类型的语言? Python是脚本语言 脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序.以简单的方式快速完成某些 ...