机器学习-TensorFlow应用之classification和ROC curve
- 概述
前面几节讲的是linear regression的内容,这里咱们再讲一个非常常用的一种模型那就是classification,classification顾名思义就是分类的意思,在实际的情况是非常常用的,例如咱们可以定义房价是否过高,如果房价高于100万,则房价过高,设置成true;如果房价低于100万,则房价不高,target就可以设置成false。这里的target就只有2种,分别只有True和False,而不像咱们的的linear regression那样target是连续的。在实际的应用中,这是有非常广泛的应用的,这一节的第一部分主要是讲如何用TensorFlow来训练一个classifier模型来预测classification problems。第二部分主要解释一下measure classification模型的的方法,那就是ROC curve。在linear regression中咱们知道有MAE,MSE等等一些列的方式来判断咱们的模型的表现怎么样,那么在classification中,MAE和MSE都不适用的,那么咱们用什么measurement来判断咱们的模型好不好呢?这时候就需要介绍咱们的ROC curve了。
- TensorFlow应用之Classification
如果咱们的target只有2个(True/False 或者 1/0等等),这种情况咱们一般称之为binary classification problem;如果咱们的target的数量大于2,咱们一般称之为multi_class classification problem。这两种方式无论是哪一种,在咱们用TensorFlow训练的时候,它的的API都是一样的,只是multi-class需要在定义模型的的时候设置一个n_classes参数而已,其他都一样。另外的建模过程跟前面章节说的一样,这一节主要介绍一下他在TensorFlow的应用中跟linear regression的区别,所以我就不会展示整个建模的过程,只会展示他们的不同。第一个不同就是模型定义的时候不同,那么现在来看一下吧
linear_classifier = tf.estimator.LinearClassifier(feature_columns = construct_feature_columns(trainning_features),
optimizer = my_optimizer
) linear_classifier = tf.estimator.LinearClassifier(feature_columns = configure_feature_columns(),
n_classes = 10,
optimizer = my_optimizer,
)
上面咱们可以看出来有两种定义classifier的方式,他们用的是LinearClassifier()来实例化模型的,而不像linear regression那样用LinearRegressor(); 其次上面的第一种没有n_classes这个参数,则说明是binary classification,因为他的默认值就是2;上面第二种方式则说明这是一个multi_class classification的问题。所以综上所述,它也是一个非常简单的定义的过程;
其次当咱们用的这个classifier来predict的时候,咱们可以看出来它的结果的数据结构跟linear regressor是不同的,下面我把的的结构在Spyder中打开给大家看一下
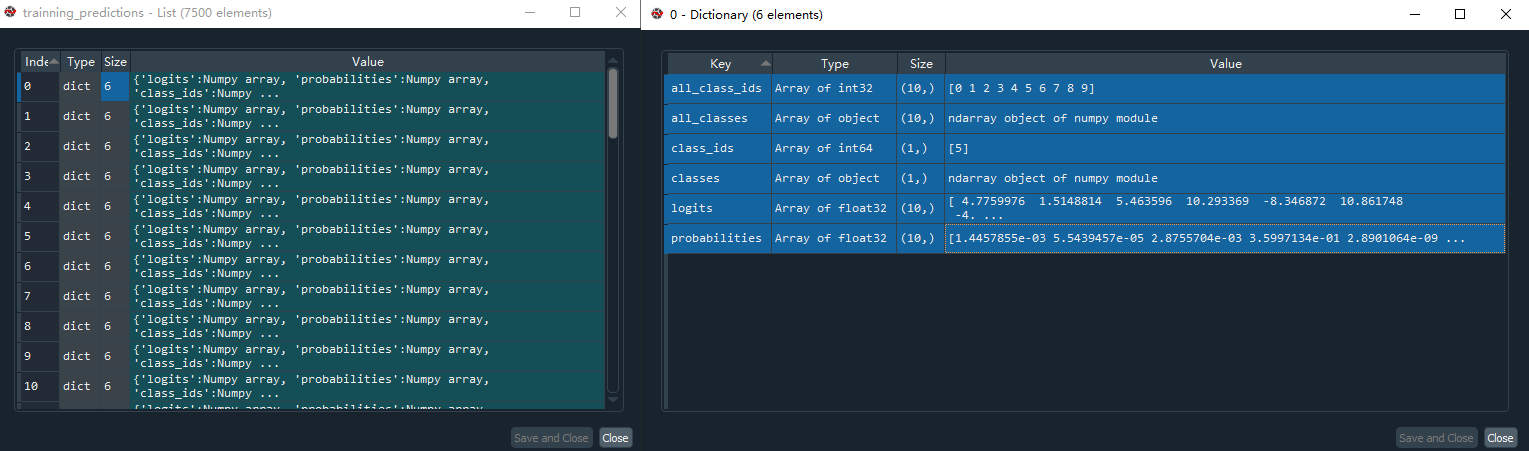
咱们可以看出来,它的prediction的结果是一个list,list里面的element是dictionary,每一个dictionary都有6个key-value pairs。这个dictionary的信息也是非常丰富的,从上面的图片可以看出来咱们的模型计算出来的结果就是class_ids这个key对应的value,当然啦,classifier计算的结果是每一种class的概率,然后选择概率最大的那一个;概率的对于的key很显然是probabilities这个字段。在其他方面,TensorFlow在classification problem中的应用的流程基本跟linear regression是一样的。
- Classifier measurement
- Accuracy
我们知道在前面的linear regression中,咱们可以用MAE,MES等等measurements来判断一个模型是否好呢?这里对于binary classification的问题,咱们可以经常使用Accuracy, ROC等方式来判断一个模型是否合格,另外在multi-classes的场景中,咱们也可以使用Accuracy和logloss等方法来判断,但是英文accuracy有它固定的缺陷,所以咱们经常不拿它作为最终参考的对象,只起一个辅助的作用。好了,那么咱们接下来来分别讲述一下他们的细节部分,在正式将这些metric之前,先给大家看一个谷歌官方教程的matrix
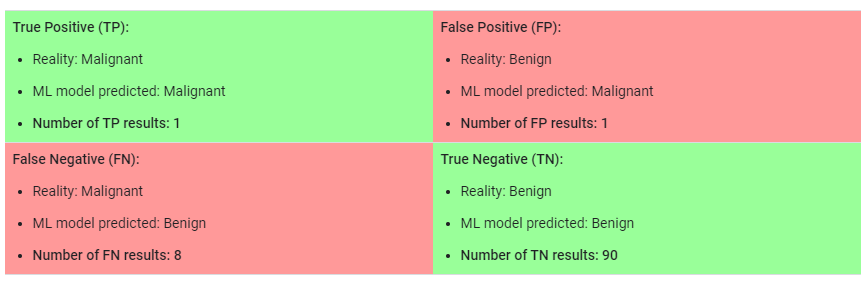
咱先来看看几个概念分别是TP, TN, FP, FN; 在这个例子中我们定义Malignant 的值是True, Benign的值是False。那么很显然上面绿色的部分就是咱们的模型预测的跟实际的是一样的;红色的部分则是怎么预测错误了,就是预测的跟实际的不一样。根据Accuracy的的定义,咱们很容易就能得到下面的公式

咱们来看看上面的例子,咱们总共的数据有100条,分别有91个Benign(良性), 9个Malignant(恶性); 如果咱们的模型预测的结果如上的matrix所示,那么根据accuracy的公式,咱们可以看出咱的的准确率高达91%,看其实还不错哦,对吧?那么咱们能用这个模型来预测吗??答案是不可以!!!咱们来仔细分析一下哈,上面的数据一共有9个malignant 恶性肿瘤,可是咱们的模型竟然只准确的预测出一个malignant (TP),其他的8个malignant竟然都没有预测出来,很显然这是有很大问题的!!!!那么为什么咱们的accuracy还是这么高呢??这是因为咱们的数据target的分布是非常不均匀的,换句话说咱们的数据是class-imbalanced dataset, 例如咱们的数据中有高达91%的Benign, 只有19%的的malignant,这个数据是非常不平衡的;咱们再举个极端的例子,上面的情况,即使咱们的模型prediction始终等于Negative,即无论什么数据送进来,咱们的预测结果始终都是Negative, 咱们的accuracy也是高达91%,这是不是很不合理??所以在判断咱们模型的时候,一定要慎用accuracy,尤其是在class-imbalanced dataset中。
- AUC-ROC Curve
这个是咱们在binary classification problem中判断一个模型好坏的一个最常用的一种方式, AUC是Aera Under Curve的缩写,很显然它是一个计算一条曲线下面的面积的函数, ROC是Receiver Operating Characteristics的缩写;那么根据名字咱们就知道AUC-ROC curve就是计算ROC curve下面的面积的一个方法。那么ROC curve到底长什么样呢?首先ROC的纵坐标是TPR(Ture Positive Rate), 横坐标是FPR(False Positive Rate). 那么具体的TPR和FPR又是什么意思呢,咱们看下面的公式

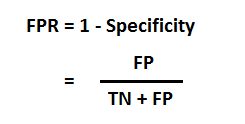
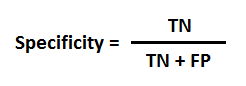
上面的公式分别表达TPR和FPR的定义的意思,其中Specificity咱们可以将它看成是Ture Negative Rate。那么这么看,咱们还是有点懵懵懂懂的不知道他们的具体含有,咱们可以结合下面的图来理解TPR, FPR

结合上面的图片,咱们可以认为TPR就是在所有的Positive的数据中,咱们正确预测出的Positive占咱们整个Positive数据数量的比例; FPR就是在咱们所有的Negative的数据中, 咱们错误的预测的数量占咱们整个Negative数据的比例。上面一句话一定一定要理解,否则什么都白瞎。那么咱们最终的ROC长什么样呢?看下图
咱们每选择一个threshold,咱ROC上面就绘制一个点,通过选择多个threshold最终画出了上面的ROC curve。 那么接着问题又来了,咱们既然已经绘制了ROC curve,咱们如何用它来判断咱们模型的好坏呢?其实就是通过计算ROC curve下面的面积(AUC)来判断的, AUC的意思是代表这这个模型分辨咱们classes的能力!!!!记住这句话,一定要记住。AUC->1代表着咱们的模型能够完全分辨出classes,AUC->0则说明咱们的模型预测的classes完全是相反的,其实这种情况也非常好,咱们只需要通过简单的取反就能够达到几乎完美的模型;最差的一种情况是AUC-> 0.5,这个时候意味着咱们的模型一点分辨能力都没有,跟咱们胡乱猜的结果是一样的。
- Log Loss
根据咱们的分析,上面的ROC的方式只适用于binary classes的情况,那么如果咱们的classes有很多怎么办,例如有10个classes,这时候咱们就无法通过计算AUC-ROC的方式来判断咱们的模型了,咱们就得通过另外一种方式来判断咱们的模型好坏了,那么这个就是Log Loss了。具体LogLoss的数学意义以及原理,我会在下一节来解释,这里我就用最简单的方式演示一下他的应用,其实在classification problem中,咱们的loss function就是Log Loss, 在linear regression中咱们的loss function是 Mean Squared Error. 具体它们的意义,我会在后面的一节详细的展示它们的意义和推导过程。好了,那么现在咱们来看一下,咱们如何计算出咱们的log loss从而来判断出咱们classfier是不是一个好的可用的模型
trainning_predictions_one_hot = tf.keras.utils.to_categorical(trainning_class_id,10)
metrics.log_loss(trainning_targets, trainning_predictions_one_hot)
- 总结
上面咱们介绍了一些classification 模型在训练中和linear regression不一样的地方,以及用什么metrics来最终判断咱们的classification模型,这里介绍了一下Accuracy, AUC-ROC和Log Loss. 其中的重点是AUC-ROC的含义和过程,然后知道Accuracy的一些应用场景,以为为什么有时候不能用它。最后了解一下Log loss是用来干什么的以及如何用它就行了。
机器学习-TensorFlow应用之classification和ROC curve的更多相关文章
- 机器学习入门12 - 分类 (Classification)
原文链接:https://developers.google.com/machine-learning/crash-course/classification/ 1- 指定阈值 为了将逻辑回归值映射到 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- Area Under roc Curve(AUC)
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- AUC(Area Under roc Curve)学习笔记
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- AUC(Area Under roc Curve )计算及其与ROC的关系
转载: http://blog.csdn.net/chjjunking/article/details/5933105 让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准.这样的标准其实有 ...
- 【转】AUC(Area Under roc Curve )计算及其与ROC的关系
让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准.这样的标准其实有很多,例如:大约10年前在machine learning文献中一统天下的标准:分类精度:在信息检索(IR)领域中常用的 ...
- 机器学习-Confusion Matrix混淆矩阵、ROC、AUC
本文整理了关于机器学习分类问题的评价指标——Confusion Matrix.ROC.AUC的概念以及理解. 混淆矩阵 在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型 ...
- iOS机器学习-TensorFlow
人工智能.机器学习都已走进了我们的日常,尤其是愈演愈热的大数据更是跟我们的生活息息相关,做 人工智能.数据挖掘的人在其他人眼中感觉是很高大上的,总有一种遥不可及的感觉,在我司也经常会听到数据科学部的同 ...
随机推荐
- Trie 树的一些题
Trie 树的一些题 牛客练习赛11 假的字符串 (Trie树+拓扑找环) 链接:https://ac.nowcoder.com/acm/problem/15049 来源:牛客网 给定n个字符串,互不 ...
- python基础试题(一)
1.执行 Python 脚本的两种方式 1.python 进入解释器 2.python 1.py 执行文件 limux里 ./1.py 2.简述位.字节的关系 8位1个字节.计算机处理以字节为单位,存 ...
- 0019 盒子模型(CSS重点):边框、内外边距、布局稳定性、PS
typora-copy-images-to: media 第01阶段.前端基础.盒子模型 盒子模型(CSS重点) css学习三大重点: css 盒子模型 . 浮动 . 定位 主题思路: 目标: 理解: ...
- Flask框架知识点整合
Flask 0.Flask简介 Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Werkzeug本质是Socket服务端,其用于接收ht ...
- 006一句话解决主机pc,Vmware虚拟机,开发板之间的ping问题
- ProxyPattern(代理模式)-----Java/.Net
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能.这种类型的设计模式属于结构型模式.
- PrototypePattern(原型模式)-----Java/.Net
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式.
- JAVA8学习——Stream底层的实现(学习过程)
Stream底层的实现 Stream接口实现了 BaseStream 接口,我们先来看看BaseStream的定义 BaseStream BaseStream是所有流的父类接口. 对JavaDoc做一 ...
- 【THE LAST TIME】深入浅出 JavaScript 模块化
前言 The last time, I have learned [THE LAST TIME]一直是我想写的一个系列,旨在厚积薄发,重温前端. 也是对自己的查缺补漏和技术分享. 欢迎大家多多评论指点 ...
- WTM 3.1发布,完美支持.netcore 3.1
在过去的2019年,承蒙各位的厚爱,WTM从零开始一年的时间在GitHub上收获了将近1600星,nuget上的下载量累计超过10万. WTM所坚持的低码开发,快速实现的理念受到了越来越多.netco ...