【2020】DBus,一个更能满足企业需求的大数据采集平台
功能远超Sqoop、DataX、Flume、Logatash、Filebeat等采集工具

注:由于文章篇幅有限,完整文档可扫 免费获取
免费获取
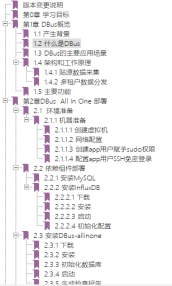
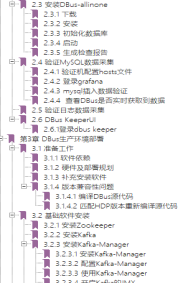

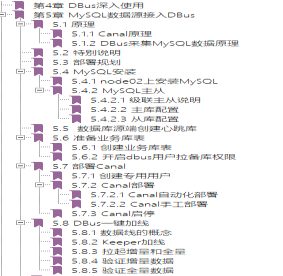
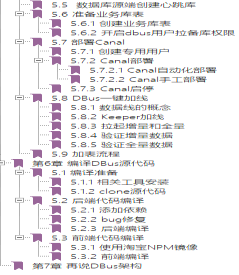
深知其他组件的局限性,才能彰显DBus的优越感
当前有很多数据采集工具(Sqoop、DataX、Flume、Logatash、Filebeat等),他们或多或少都存在一些局限性。
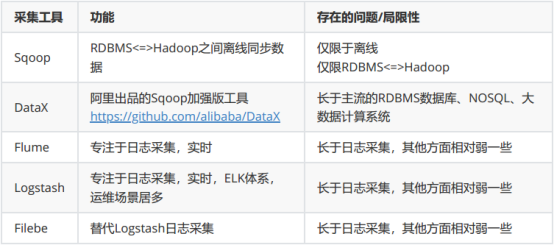
一个共性问题是缺乏统一的数据源端管控,所以也就无法找到统一的数据入口,那后续处理元数据或者血缘分析会异常困难。除此之外,现有各种数据采集工具的数据同步方法也有一定的局限性。比如:
(1)各个数据使用方在业务低峰期各种抽取所需数据(缺点是存在重复抽取而且数据不一致)
(2)由统一的数仓平台通过sqoop到各个系统中抽取数据(缺点是sqoop抽取方法时效性差,一般都是T+1的时效性)
(3)基于trigger或时间戳的方式获得增量的变更(缺点是对业务方侵入性大,带来性能损失等)
这些方案都不能算完美,要想同时解决数据一致性和实时性,比较合理的方法应该是基于日志的解决方案,同时能够提供消息订阅的方式给下游系统使用。在这个背景下DBus就诞生了。
DBus到底是什么?给我一个完美的解释
DBus(数据总线)项目为了统一数据采集需求而生, 专注于数据的收集及实时数据流计算,通过简单灵活的配置,以无侵入的方式对源端数据进行采集,采用高可用的流式计算框架,对公司各个IT系统在业务流程中产生的数据进行汇聚,经过转换处理后成为统一JSON的数据格式(UMS),提供给不同数据使用方订阅和消费,充当数仓平台、大数据分析平台、实时报表和实时营销等业务的数据源。支持多租户管理,提供租户级资源、数据隔离机制。
看DBus官网,了解更多更新一手资料
https://github.com/BriData/DBus
看DBus架构,聚焦DBus两大核心功能
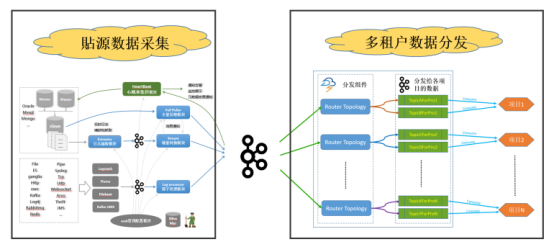
DBUS主要分为两个部分:
(1)贴源数据采集
(2)多租户数据分发
两个部分之间以Kafka为媒介进行衔接。无多租户资源、数据隔离需求的用户,可以直接消费源端数据采集这一级输出到kafka的数据,无需再配置多租户数据分发
继续深入贴源数据采集功能模块
DBUS源端数据采集大体来说分为两部分:
读取RDBMS增量日志的方式来 实时获取增量数据日志,并支持全量拉取;基于logtash,flume,filebeat等抓取工具来实时获得数据,以可视化的方式对数据进行结构化输出;
以下为具体实现原理:
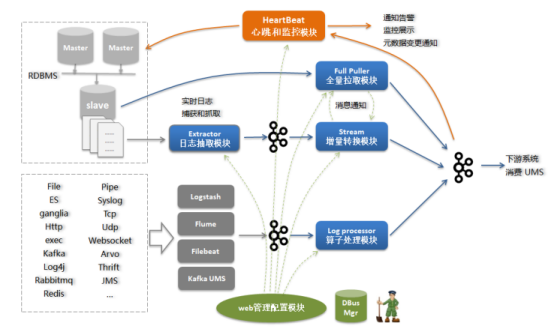
主要模块如下:
(1)日志抓取模块:从RDBMS的备库中读取增量日志,并实时同步到kafka中;
(2)增量转换模块:将增量数据实时转换为UMS数据,处理schema变更,脱敏等;
(3)全量抽取程序:将全量数据从RDBMS备库拉取并转换为UMS数据;
(4)日志算子处理模块:将来自不同抓取端的日志数据按照算子规则进行结构化处理;
(5)心跳监控模块:对于RDMS类源,定时向源端发送心跳数据,并在末端进行监控,发送预警通知;对于日志类,直接在末端监控预警。
(6)web管理模块:管理所有相关模块。
继续深入多租户数据分发功能模块
对于不同租户对不同源端数据有不同访问权限、脱敏需求的情形,需要引入Router分发模块,将源端貼源数据,根据配置好的权限、用户有权获取的源端表、不同脱敏规则等,分发到分配给租户的Topic。这一级的引入,在DBUS管理系统中,涉及到用户管理、Sink管理、资源分配、脱敏配置等。不同项目消费分配给他的topic。

未完待续。由于文章篇幅有限,完整文档可扫码免费获取。

【2020】DBus,一个更能满足企业需求的大数据采集平台的更多相关文章
- FusionInsight,一个融合的大数据平台
随着物联网技术和应用的普及,以运营商.互联网以及实体经济行业为代表的企业产生了越来越多的数据,大数据的发展越来越蓬勃. 从2007年开始,大数据应用成为很多企业的需求,2012年兴起并产生了大数据平台 ...
- 用MVC5+EF6+WebApi 做一个小功能(二) 项目需求整理
在一个项目开始前,需求整理大概要占到整个项目周期15%甚至30%的比重,可以说需求理得越清楚,后续开发中返工几率越小.在一个项目中,开发新功能的花费的精力要远远小于修改功能的精力,这基本是一个共识.老 ...
- 为什么说国产BI更适合国内企业?
就算国外BI发展迅速,产品更加完善成熟,但对国内的企业来说,使用起来难免"水土不服",何况还有服务对接过程中的繁琐程.今天就来讨论一下,国内BI和国外BI到底该怎么选择? 国外B ...
- 在字节跳动,一个更好的企业级SparkSQL Server这么做
SparkSQL是Spark生态系统中非常重要的组件.面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求.本文将详细解读,如何通过构建SparkSQL服务器实现使用效 ...
- COM是一个更好的C++
昨天看了<COM本质论>的第一章”COM是一个更好的C++”,觉得很有必要做一些笔记,于是整理成这篇文章,我相信你值得拥有. 这篇文章主要讲的内容是:一个实现了快速查找功能的类FastSt ...
- 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上)
[转] 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上) jquery的功能总是那么的强大,用他可以开发任何web和移动框架,在浏览器市场,他一直是占有重要的份额,今天,就给大家 ...
- 《COM本质论》COM是一个更好的C++心得分享
昨天看了<COM本质论>的第一章"COM是一个更好的C++",认为非常有必要做一些笔记,于是整理成这篇文章.我相信你值得拥有. 这篇文章主要讲的内容是:一个实现了高速查 ...
- 自定义一个更好用的SwipeRefreshLayout(弹力拉伸效果详解)(转载)
转自: 自定义一个更好用的SwipeRefreshLayout(弹力拉伸效果详解) 前言 熟悉SwipeRefreshLayout的同学一定知道,SwipeRefreshLayout是android里 ...
- 为什么ELT更适合于企业数据应用?
为什么ELT更适合于企业数据应用 DataPipeline 陈肃 为什么现在企业环境中,一个ELT的方案会比ETL的方案更有优势,实际上是由企业数据应用特点决定的. 首先在一个企业数据应用里面我们对数 ...
随机推荐
- 为BlueLake主题增加图片放大效果
fancyBox 是一个流行的媒体展示增强组件,可以方便为网站添加图片放大.相册浏览.视频弹出层播放等效果.优点有使用简单,支持高度自定义,兼顾触屏.响应式移动端特性,总之使用体验相当好. 现在,我们 ...
- KMP——强大的next数组
\(KMP\) 的原理不在这里仔细讲了,主要说说最近刷题总结出的 \(next\) 数组的强大功能. 部分例题来自<信息学奥赛一本通>的配套练习. 基于定义--字符串相同前后缀 " ...
- python+pandas+jupyter notebook 的 hello word
- FluentData 学习 第一弹
地址: http://fluentdata.codeplex.com/ 前世: FluentData 我们公司用的一个增删改查的里面的持久层.之前还不知道 这个持久层叫FluentData. 某天看 ...
- 曹工说Spring Boot源码(15)-- Spring从xml文件里到底得到了什么(context:load-time-weaver 完整解析)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- Docker应用部署实录(包含完善Docker安装步骤)
Docker应用部署实录(包含完善Docker安装步骤) 前言 首先说一下这篇文章的来源.我之前接手的一个IOT项目,需要安装多个中控服务器.中控服务器需要安装RabbitMQ,Mysql,多个服务, ...
- java枚举类的常见用法
枚举类型(Enumerated Type) 很早就出现在编程语言中,它被用来将一组类似的值包含到一种类型当中.而这种枚举类型的名称则会被定义成独一无二的类型描述符,在这一点上和常量的定义相似.不过相比 ...
- 开源项目SMSS发开指南(五)——SSL/TLS加密通信详解(下)
继上一篇介绍如何在多种语言之间使用SSL加密通信,今天我们关注Java端的证书创建以及支持SSL的NioSocket服务端开发.完整源码 一.创建keystore文件 网上大多数是通过jdk命令创建秘 ...
- 认识Git与GitHub
Git介绍 Git是一个开源的分布式版本控制系统,用以有效.高速的处理从很小到非常大的项目版本管理.相比CVS.SVN等版本控制工具,Git更加优秀,功能也更加强大.但是相对也难学. 使用Git来管理 ...
- cookie理解与实践【实现简单登录以及自动登录功能】
cookie理解 Cookie是由W3C组织提出,最早由netscape社区发展的一种机制 http是无状态协议.当某次连接中数据提交完,连接会关闭,再次访问时,浏览器与服务器需要重新建立新的连接: ...