Java面试—消息队列
消息队列面试题
题目来自于中华石杉,解决方案根据自己的思路来总结而得。
题目主要如下:
1. 为什么要引入消息队列?
消息队列的引入可以解决3个核心问题:
- 解耦
- 异步
- 削峰
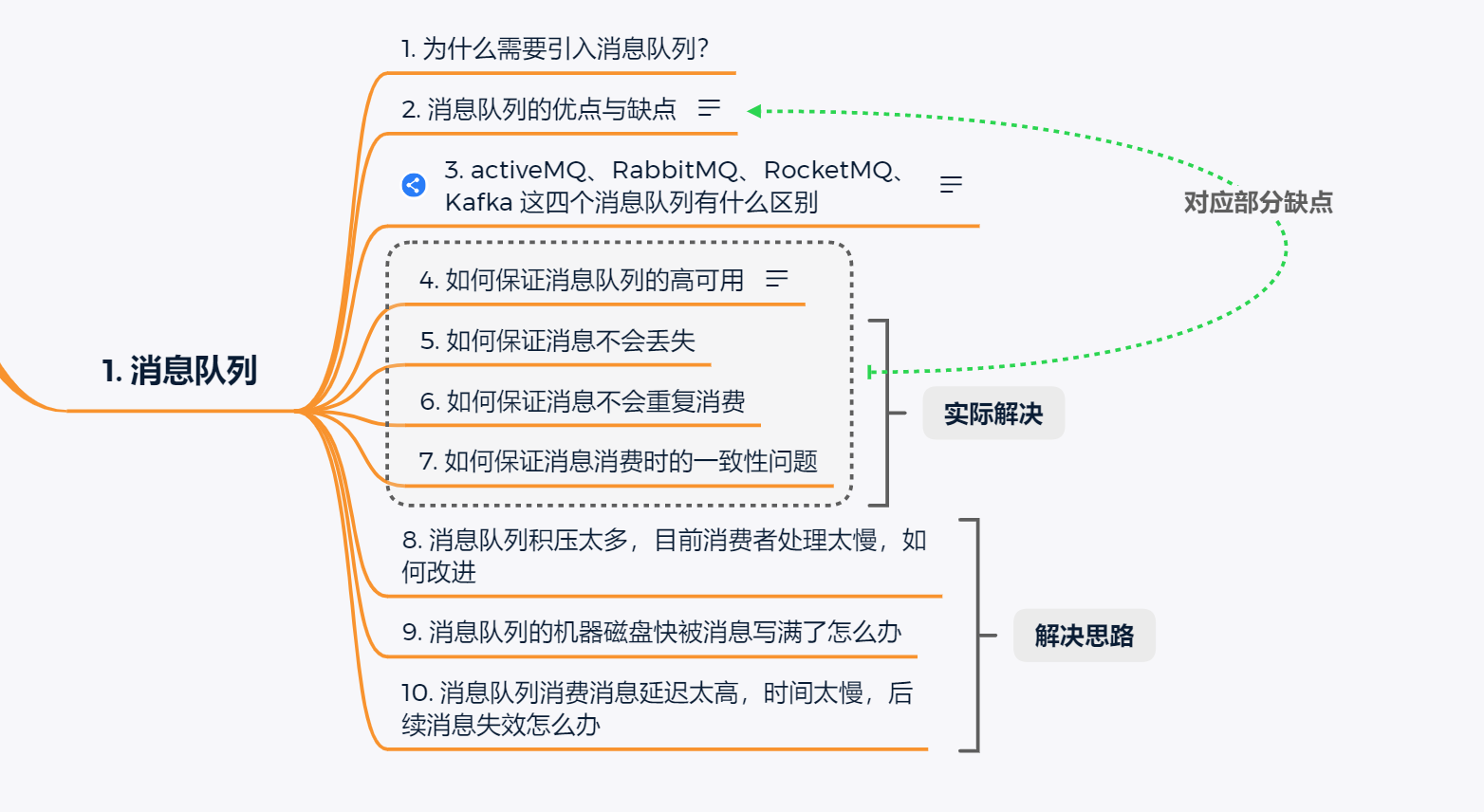
- 解耦
在一个项目中,如果一个模块A产生的一个关键数据,需要调用其他模块接口服务;而需要调用的接口很多,又不确定之后是否还需要将数据传给其他模块的接口时。这时可以使用消息队列,使用了消息队列之后,模块A不需要在对接各个模块,而是直接对接消息队列。这样一来。当其他的模块需要这个数据时,也不用再修改A数据,而是去到MQ中订阅这个Topic。使得模块A与其他模块之间耦合度降低。
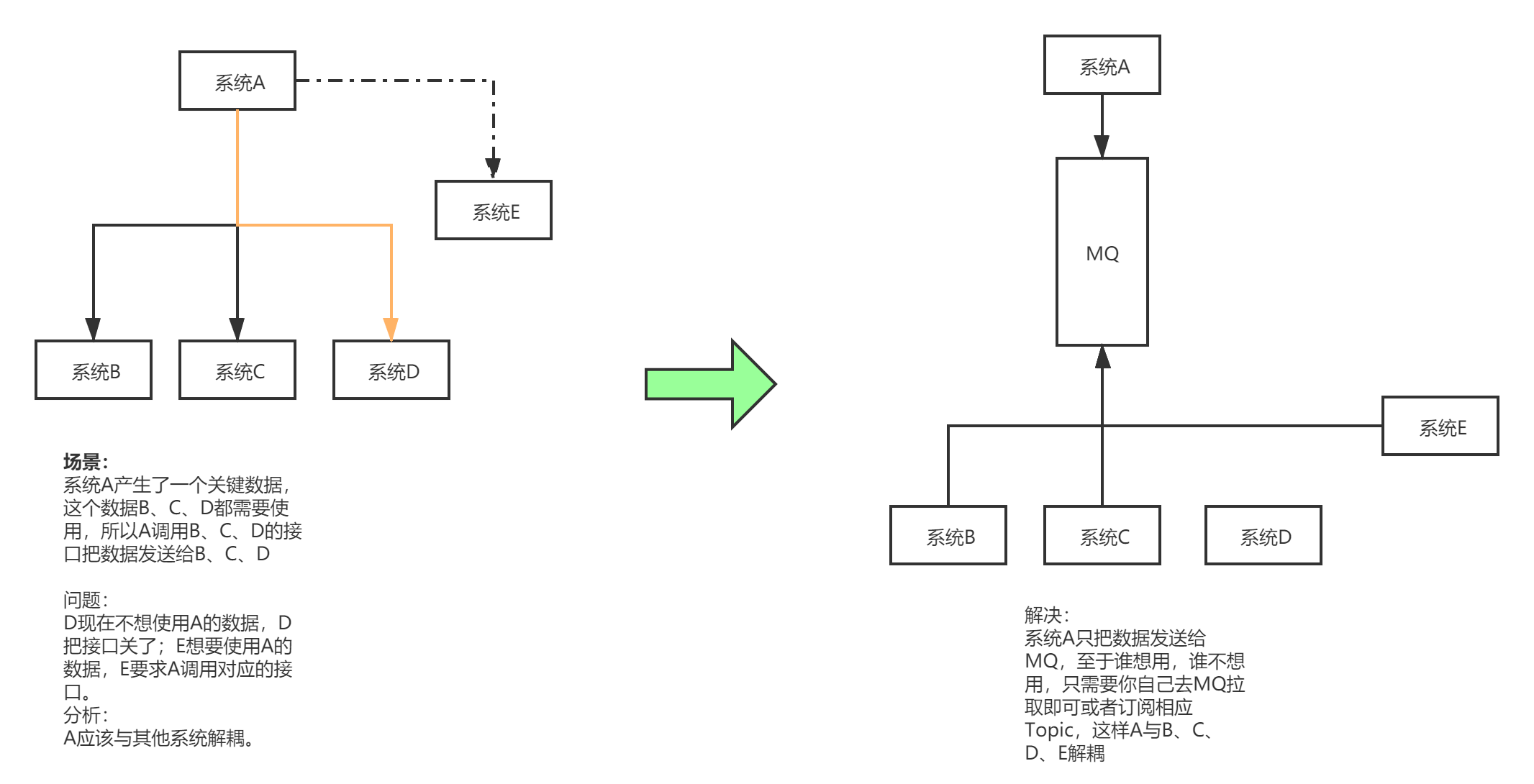
- 异步
在一个项目中,如果模块A的请求处理需要20ms,而模块A又依赖了模块B,模块C ,模块D 。在A请求处理结束后,A需要调用
模块B,C,D的对应请求处理,这时B请求处理需要100ms,C 需要200ms,D 需要400ms。这样一来,总体一个请求的总时长为
20 + 100 + 200 + 400 = 720 ms 远远大于模块A的请求处理时间。另一方面,模块B 模块C 模块D之间 并没有顺序关系。
这时可以引入消息队列 ,模块A在请求处理结束后,将自己的数据发送给消息队列MQ,由B,C ,D去消息队列获取数据,自行处理
模块A在处理完成后直接返回给客户端处理结果,而不需要等待B,C,D处理结束,如此一来,一个请求处理的就只需要计算
模块A的处理时间=20ms,大大提高了用户体验。
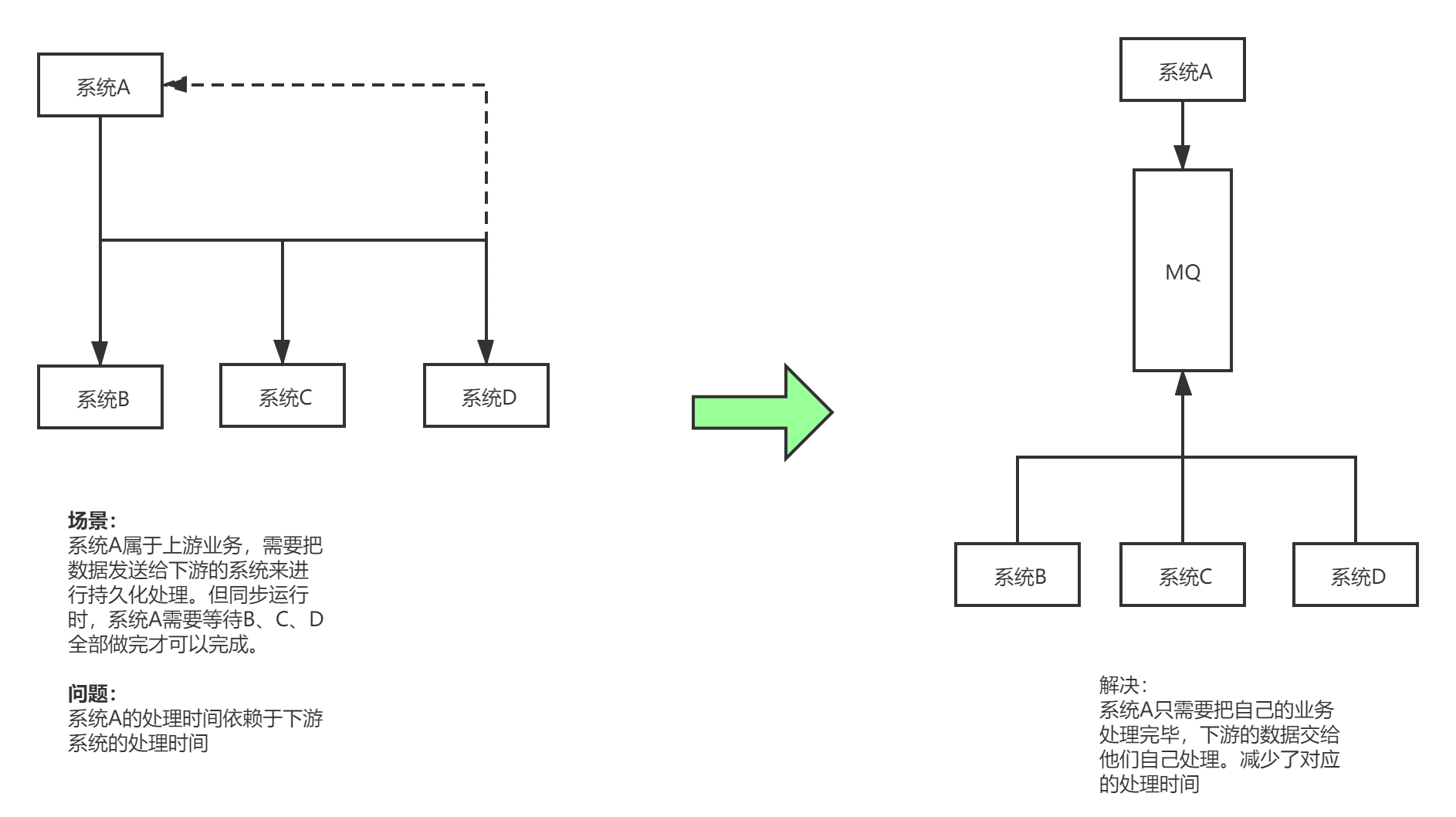
- 削峰
如果一个系统只能一秒钟处理5000个请求(MySQL一般只能2000QPS),而在特殊时期就只要1个小时的时间段内,请求量暴涨,一秒钟来了1W个请求。从而系统会之间宕机。但这种情况可能在平时不会发生,不需要升级相应的服务器配置。
问题在于在1小时的时间段,如何把请求从10000QPS 下降到5000QPS 使得系统能够正常运转而不发生宕机。
这时候可以引入消息队列,假设模块A负责处理请求,模块B负责将数据持久化到数据库。模块A在接受到请求时,把请求交给消息队列,由消息队列来缓解对应的请求压力,类似于Buffer建立一个缓冲区,模块B根据自己的请求处理速度去到消息队列中去消费数据。这样一来就解决了对应特定时间段的削峰问题。
- 要结合实际项目来说明:
体现上述的三个点。
2. MQ有什么缺点?
任何技术都是一把双刃剑,在引入消息队列的同时必定也会伴随着相应的问题,正如《人月神话》中所说,没有银弹。
消息队列的引入会带来3个核心的问题:
- 系统可靠性降低
在引入MQ时,MQ作为了中间层,这就使得模块与对应的MQ是紧耦合的关系。一旦MQ宕机,下游服务即使正常运行,但整个系统却无法使用。这个问题的解决方式是 MQ的高可用,使得MQ高可用,不会那么容易宕机达到5个9。
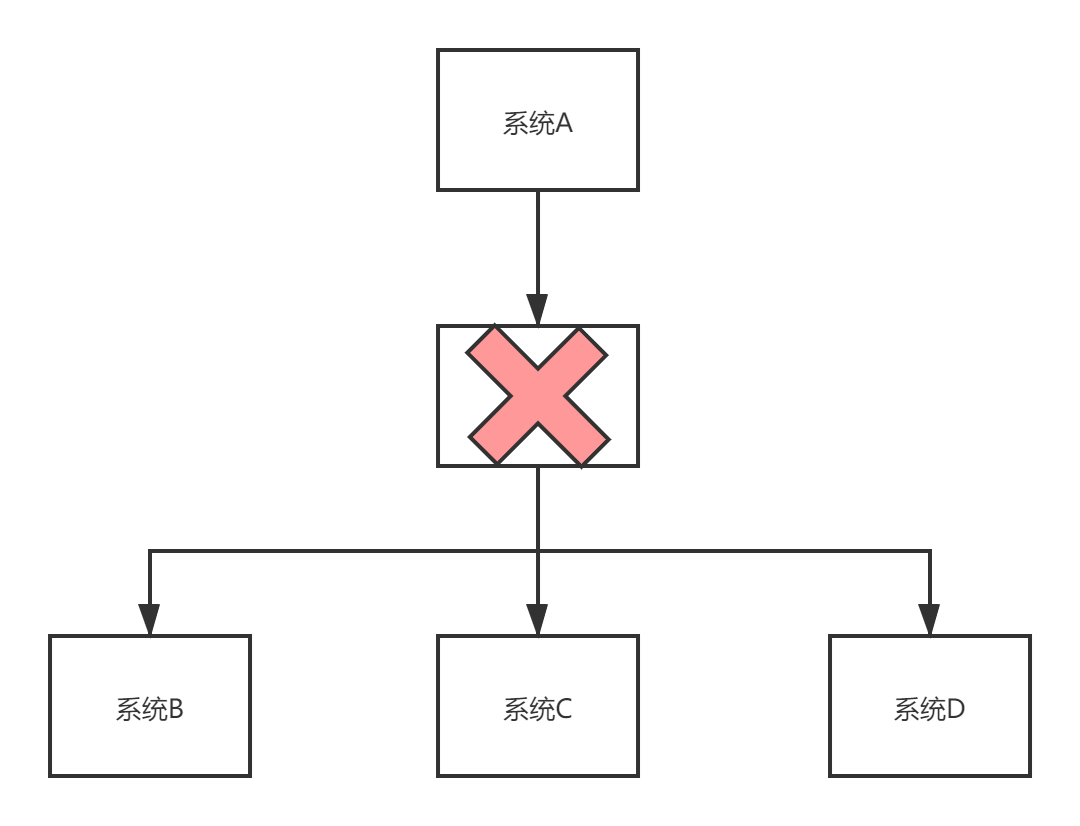
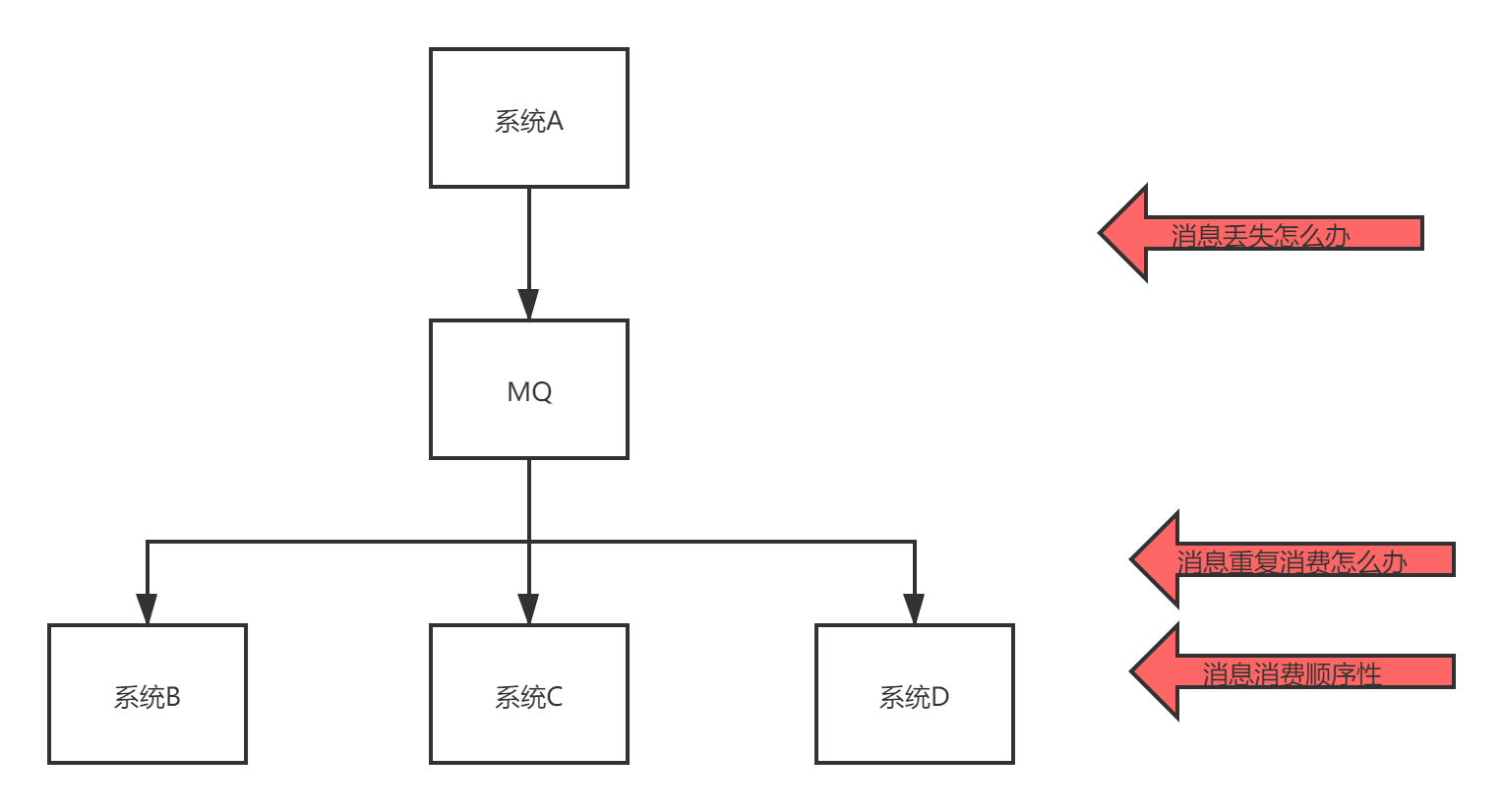
- 系统复杂度提高
引入MQ,需要考虑的问题变复杂,随之而来的问题是- 消息丢了怎么办
- 重复消费消息问题
- 消息的顺序问题
这几个问题都有对应的解决方案。
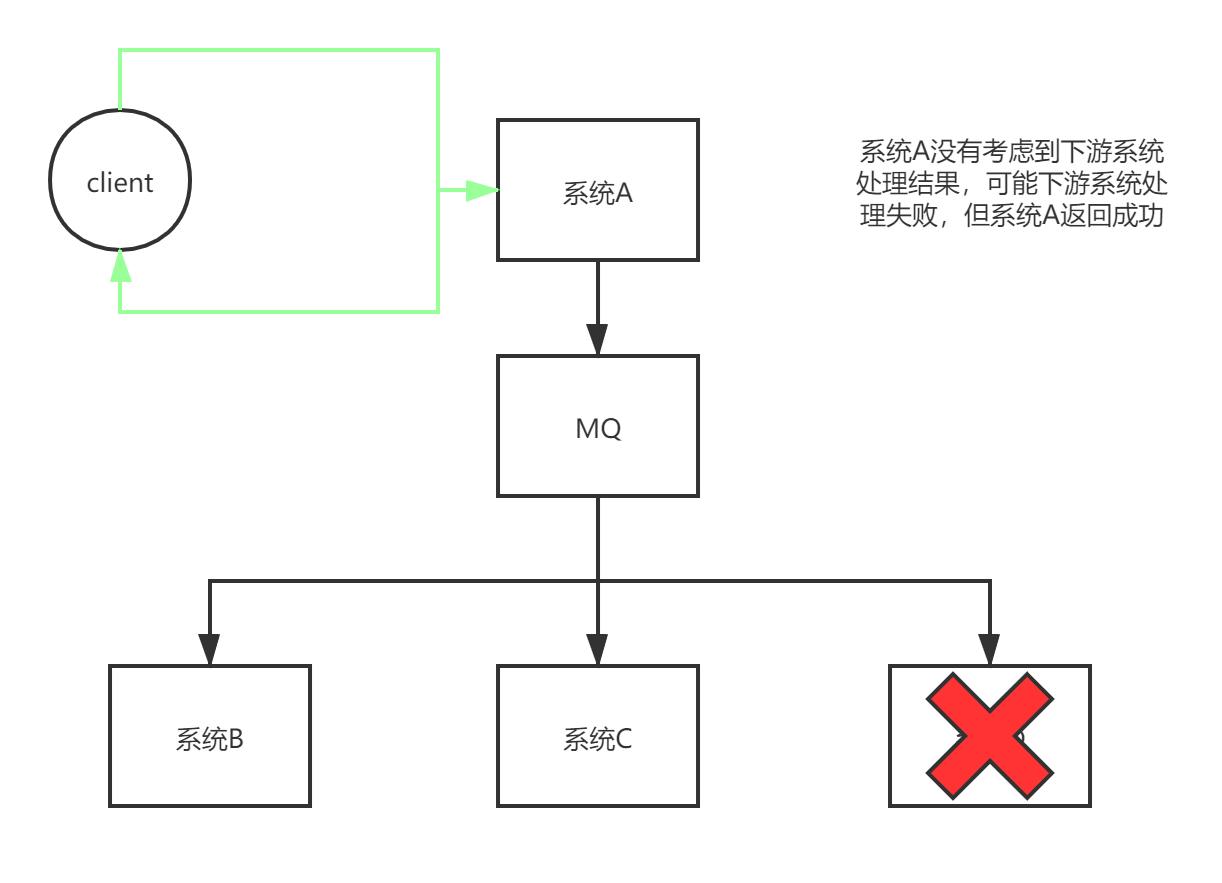
- 处理结果的最终一致性问题
引入MQ会导致处理结果的最终一致性问题,因为模块A与其他模块之间解耦,从而模块A不知道其他模块的处理结果
这就导致模块A以为处理结果OK,但实际上可能模块B处理结果失败,这也是异步化所带来的最终一致性问题。
3. 你都了解过哪些MQ? 他们之间有什么区别吗?
这个问题可以延伸为技术选型问题,关于这个问题可以认为凭什么你选择了这个MQ,而没有选择其他MQ。对应可以扩展为spring-security 与shiro 都是安全框架都实现了Oauth2协议,而且shiro是轻量级的,为什么你选择了Spring-Security这个安全框架这个问题比较考察技术广度。
首先我了解过的MQ有:activeMQ,RabbitMQ,RocketMQ,Kafka
| activeMQ | RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 并发量 | 万级 | 万级 | 十万级 | 万级 |
| 处理时长 | 毫秒 | 微妙 | 毫秒 | 毫秒 |
| 开发语言 | Java | ErLang | Java | Java Scala |
| 功能完备 | 完备 | 完备 且提供了插件与管理界面 | 完备 | 完备 |
| 常用场景 | 小型项目demo | * | * | 大数据领域日志处理、实时计算 |
| 社区活跃度 | 较低 | 高 | 高 | 高 |
activeMQ社区活跃度较低,不建议使用。
RabbitMQ社区活跃度高,更新版本频繁,但使用开发语言为ErLang , 当有定制化需求无法进行扩展
RocketMQ 阿里出品,但存在着后续项目不更新情况,这就使得企业自行维护相应的功能或者定制化功能
Kafka 大数据领域 主要用来进行实时计算,日志采集的消息队列,功能相比于其他MQ少,但是kafka是大数据领域公认的消息队列
如果对功能有要求,小公司可以选择RabbitMQ, 有技术团队的大公司可以使用RocketMQ,大数据生态为了与其他组件配合所以使用Kafka
4. 如何保证MQ的高可用
- RabbitMQ的HA
RabbitMQ的解决方式为=>集群模式 + 镜像
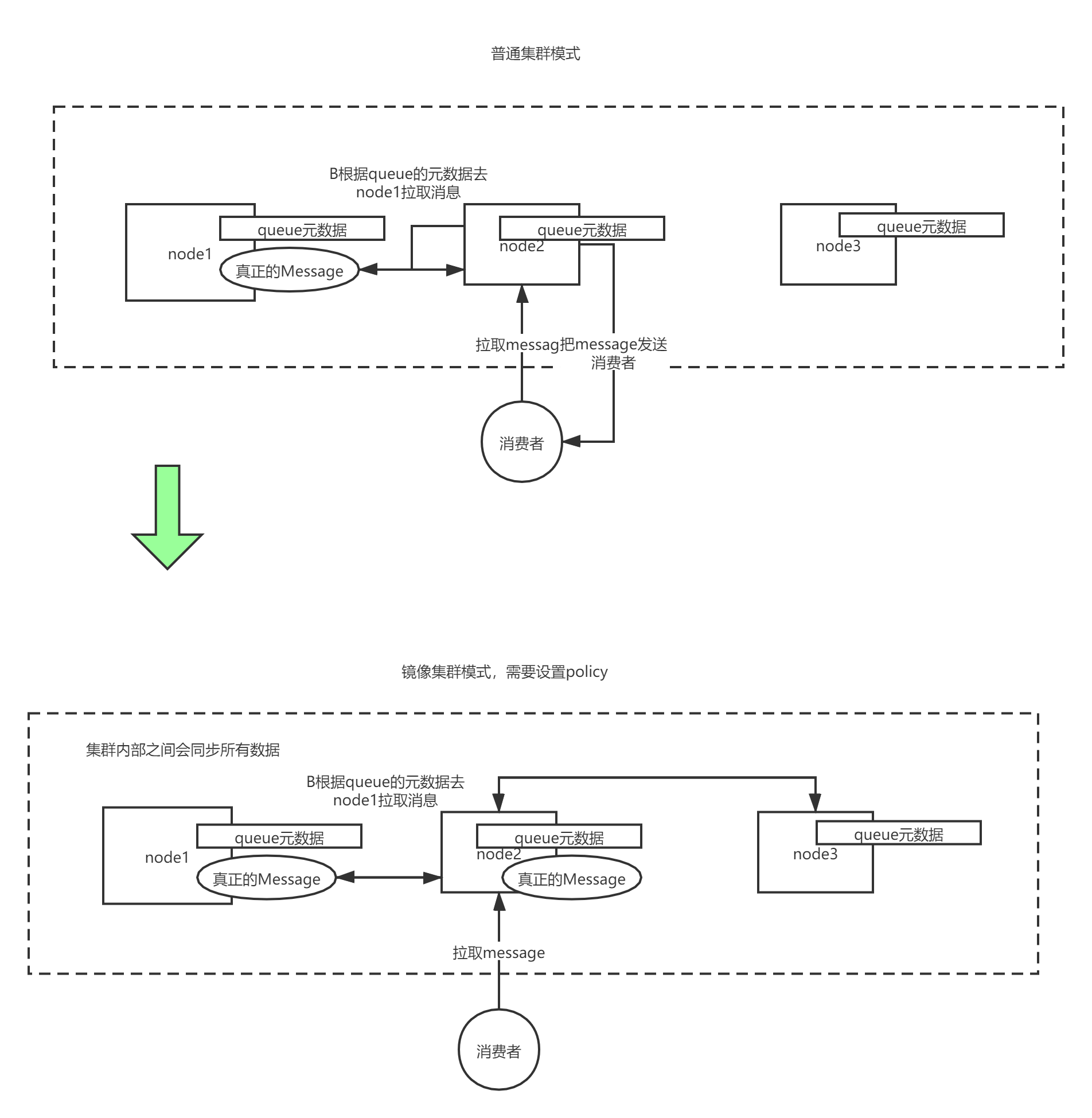
普通集群模式:
queue创建之后,如果没有其它policy(策略),则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列。
只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。
假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
镜像集群模式:
核心在于:镜像集群会同步消息
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用,
一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。但这不是分布式存储,而是多节点主备存储。相比于Kafka的分布式架构会多消耗资源。 - Kafka实现高可用
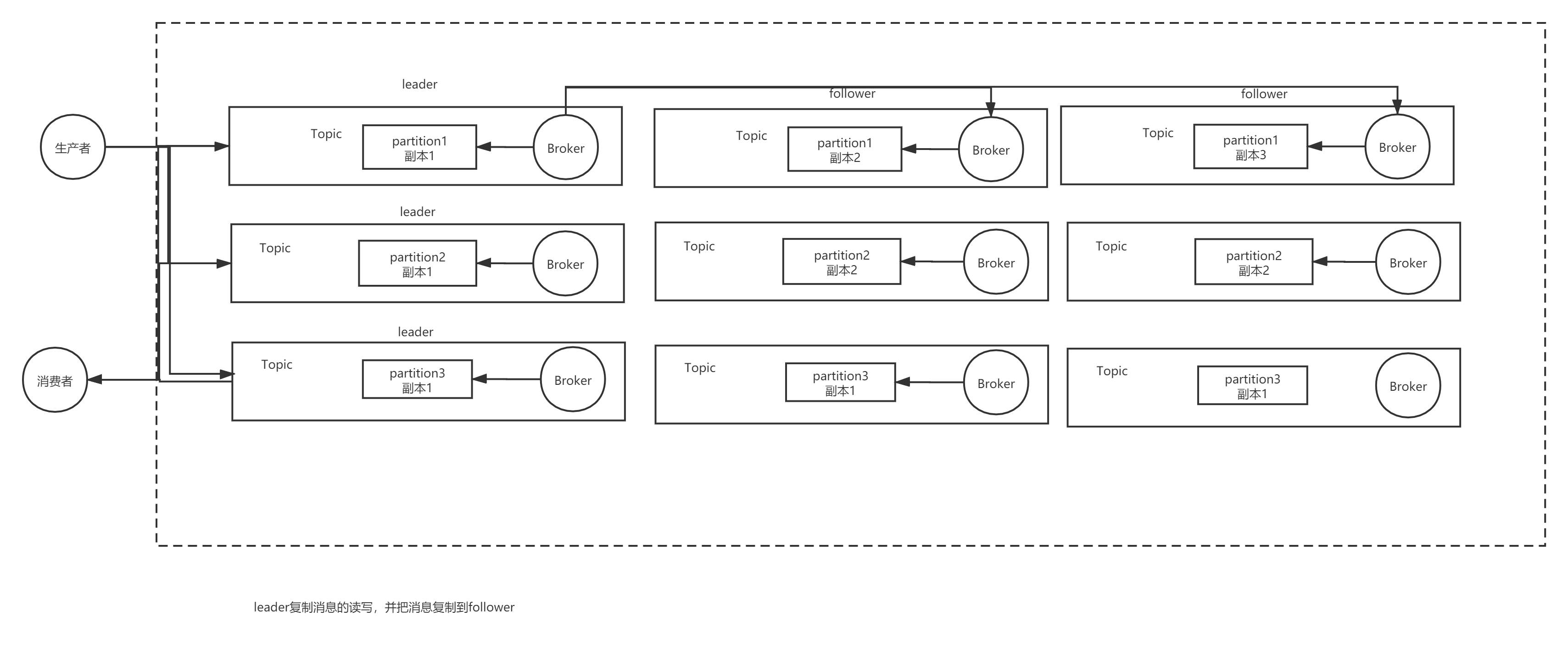
Kafka的高可用主要是通过Kafka通过把每个Topic中的消息分成多个Partition,每个Partition做一个集群。而每一个Partition内部集群通过选举得到一个leader,其他是follower,leader复制消息的读写,并把消息复制到follower。Kafka在发送消息时,只有当每个partition的follower复制到了消息才确认消息已经被存储。
5. 如何保证消息不会丢失?
- RabbitMQ方式
1.1 生产者方面- 开启RabbitMQ的事务方式txSelect()。当生产者写入消息失败时,采取重试机制。但这个写入是同步的。
- 使用confirm方式: 其中confirm也可以使用三种方式:
- 普通confirm
- 批量confirm
- 异步confirm 设置监听器
channel.confirmSelect();
//普通confirm
if (channel.waitForConfirms()) {
System.out.println("消息发送成功" );
}
//批量confirm 失败会报错
channel.waitForConfirmsOrDie();
//异步监听confirm
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("未确认消息,标识:" + deliveryTag);
}
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println(String.format("已确认消息,标识:%d,多个消息:%b", deliveryTag, multiple));
}
});
1.2 RabbitMQ方面
RabbitMQ在内存缓存消息,当MQ宕机时,会发生消息丢失现象。这一点需要RabbitMQ将消息持久化到硬盘上。减小消息丢失的可能
1.3 消费者方面
RabbitMQ默认是autoAck=true,这样就使得消费者在接受到消息时,立马告知MQ我消费了数据,但还没有来得及处理。所以需要把autoAck=false,之后当消息处理完成之后手动提交。
2 kafka方面
- 生产端
数据丢失发送在leader向follower同步消息的时候,leader宕机使得消息丢失。
解决方案是设置4个参数:- replication.factor = n > 1 设置partition有多少个副本数
- kafka咋服务端设置mini.sync.replicas=1 即一个leader至少保证有一个follower存活
- producer在发送消息时,设置acks=all 设置所有消息必须全部写入replication后返回成功。
- retries=Integer.MAX 把重试次数调制最大
- 消费端
在消费者端关闭自动确认消息,这样需要手动确认 保证消息不会丢失。
6. 如何保证消息不会重复消费?
- 在消费者消费消息时,把对应的唯一值放入HashSet 或者Redis来避免同一条消息消费多次
- 使用数据库的唯一键约束来报错处理
7. 如何保证消费者消费消息时消息的顺序性?
消息队列本身就是为了把多个任务解耦并行化处理,如果要保证消息的顺序消息,实际上就是取消并行处理,改成串行处理。
- RabbitMQ
将一组消息放入同一个queue,这样就只会有一个consumer来消费这个queue中的数据,在consumer内部采用队列的方式来处理顺序消息 - Kafka
生产者写消息时,每次写入一个topic,将partition对应key值修改同一key,这样消息只会进入一个partition,也只有一个消费者在进行消费,之后也采用内存队列的方式顺序处理消息。
8. 消息队列积压太多,目前消费者处理太慢,如何改进?
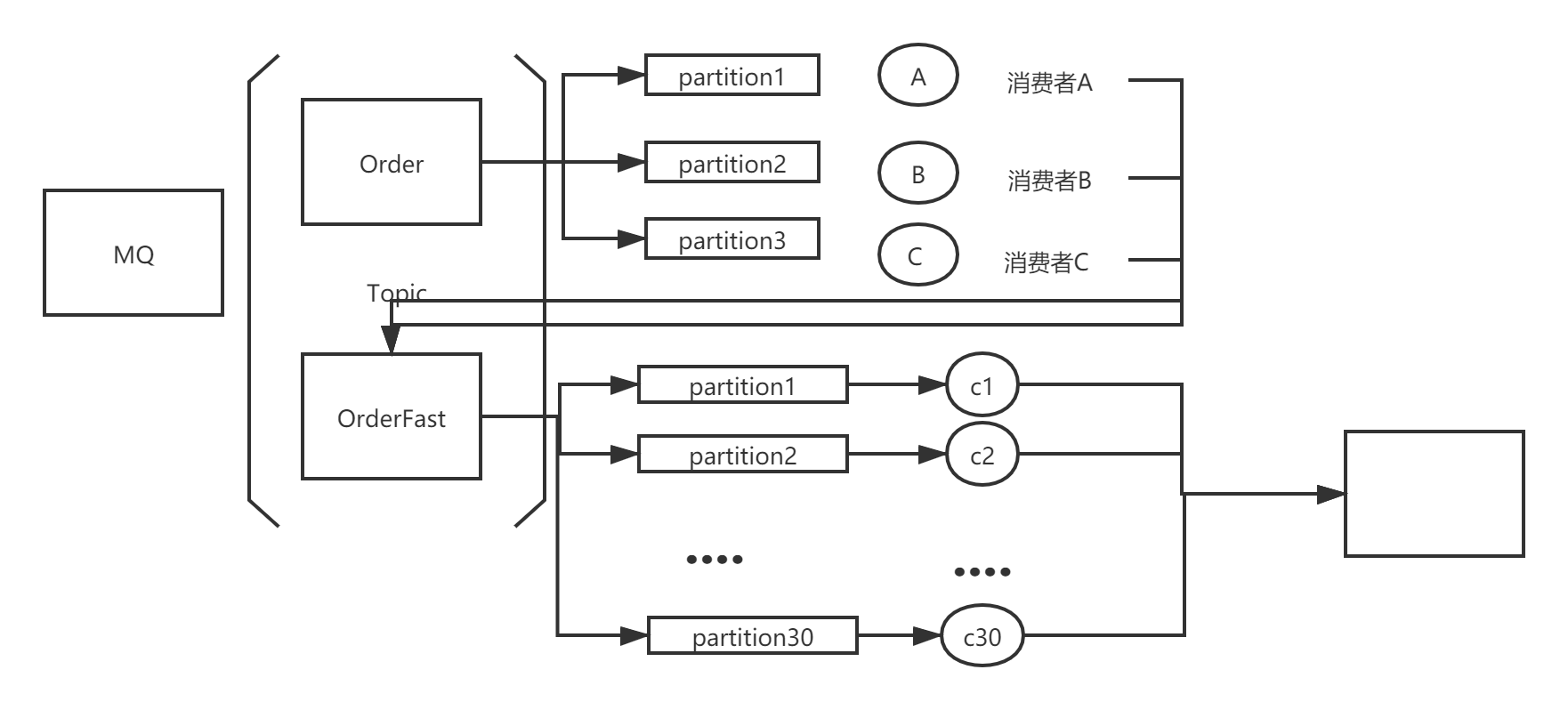
目前的消费者难以在短时间内处理这么多条消息,考虑引入多个消费者,但引入这多个消费者只用于消费当前消息,并不是长期使用。假定长期使用的消费者为A、B、C 订阅的Topic是Order。新申请3 * 10~20 = 30~60个机器 作为新的消费者组GroupNew。 GroupNew 订阅新的Topic - OrderFast,从这个topic中获取消息并消费。将原有长期使用的消费者组修改代码,不处理消息 直接将消息写入到新的Topic - OrderFast
9. 消息队列的机器磁盘快被消息写满了怎么办?
- 可以采取上述方案,不同的是写入到另外一台MQ中,而不是在本机的Topic
- 下一个消息直接丢弃不处理,到消息队列机器恢复之后,将生产者与消费者之间通过代码查询出对应的缺失部分,再进行补偿式操作。
10. 消息队列消费消息太慢,消息过期失效怎么办?
- 生产环境设置消息不过期
- 如果已经过期失效,那么需要查出过期失效的消息,重新进行补偿式操作
本文由博客一文多发平台 OpenWrite 发布!
Java面试—消息队列的更多相关文章
- java JMS消息队列
http://blog.csdn.net/shirdrn/article/details/6362792 http://haohaoxuexi.iteye.com/blog/1893038 http: ...
- JAVA记录-消息队列介绍
1.JMS概述 JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消 ...
- Java服务器端消息队列实战
服务端口监听--报文接收--报文解码--业务处理--报文编码--写回客户端 从服务端与客户端成功握手并产生一个socket后,为了提高吞吐能力,接下来的事情就可以交给多线程去处理. 为了对接入的请求做 ...
- java之消息队列ActiveMQ实践
原创论文:https://www.cnblogs.com/goujh/p/8510239.html 消息队列的应用场景: 消息队列应用场景 异步处理,应用解耦,流量削锋和消息通讯四个场景 异步处理: ...
- Java基础——消息队列
1.消息队列的适用场景:商品秒杀.系统解耦.日志记录等 2.使用Queue实现消息对列 双端队列(Deque)是 Queue 的子类也是 Queue 的补充类,头部和尾部都支持元素插入和获取阻塞队列指 ...
- [Java] 分布式消息队列(MQ)
概述 场景 服务解耦 削峰填谷 异步化缓冲:最终一致性/柔性事务 MQ应用思考点 生产端可靠性投递 消费端幂等:消息只能消费一次 高可用.低延迟.可靠性 消息堆积能力 可扩展性 业界主流MQ Acti ...
- java学习-消息队列rabbitmq的组成
rabbitMQ组成部分 rabbitmq有以下组成部分,分别为: 1. Server(broker)接受客户端连接,实现AMQP消息队列和路由功能的进程 2.虚拟主机virtual host虚拟主机 ...
- java 框架-消息队列ActiveMQ
https://www.jianshu.com/p/ecdc6eab554c ActiveMQ从入门到精通(一) 22017.03.11 21:40:42字数 2650阅读 57286 这是关于消息中 ...
- java面试-阻塞队列
一.阻塞队列 当阻塞队列是空,从队列中获取元素的操作会被阻塞 当阻塞队列是满,往队列中添加元素的操作会被阻塞 二.为什么用,有什么好处? 我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为 ...
随机推荐
- git工作中总结
# .克隆到本地 git clone url git clone -b 分支 url # 注意:克隆完成后,要删除.git隐藏文件夹 # .修改代码 # .生成master git init git ...
- powershell Google Firefox
$firefox = @{ DisplayName = "Mozilla Firefox"; filename = "Firefox Setup 68.0b7.msi&q ...
- mysql 用户操作和授权
1.查看mysql的版本 mysql -V 2.用户操作 # 创建用户 create user 'username'@'ip地址' identified by '密码'; # 用户重命名 rename ...
- 美食家App开发日记4
研究了卡片式布局中的Recyclerview的用法,但是调试了很长时间,导入包总是有问题,一到手机上运行就会闪退.还是在网上查了很多方法,很不开心我还是解决不了.
- LightningChart® .NET 8.5版重磅上线,新年特惠
新年回馈用户 新年伊始,全球领先的数据可视化图表工具LightningChart®正式发布了.Net 8.5版本,新版软件在外观.功能和用户体验上都做了突破性的改进.LightningChart®同时 ...
- 将DataTable数据转换成List泛型数据
这里有一个实体类: public class Menuss { public int Id { get; set; } public string Te ...
- javascript的对象、类和方法
1.类和对象的概念: 1.所有的事物都是一个对象,而类就是具有相同属性和行为方法的事物的集合 2.在JavaScript中建立对象的目的就是将所有的具有相同属性的行为的代码整合到一起,方便使用者的管理 ...
- spring4.2.4整合ehcache
最近工作中遇到个功能需要整合ehcache,由于spring版本用的是4.2.4,而在ehcache官网找到的集成配置文档是spring3.1的,因此配了几次都不成功,在历经一番波折后终于成功集成了s ...
- 【Java并发基础】利用面向对象的思想写好并发程序
前言 下面简单总结学习Java并发的笔记,关于如何利用面向对象思想写好并发程序的建议.面向对象的思想和并发编程属于两个领域,但是在Java中这两个领域却可以融合到一起.在Java语言中,面向对象编程的 ...
- Python里的装饰器
装饰器 装饰器是干什么用的? 装饰器可以在不修改某个函数的情况下,给函数添加功能. 形象点来说,从前有一个王叔叔,他一个人住在家里,每天打扫家,看书.于是定义如下一个函数: def uncle_wan ...