hadoop NameNode 手动HA
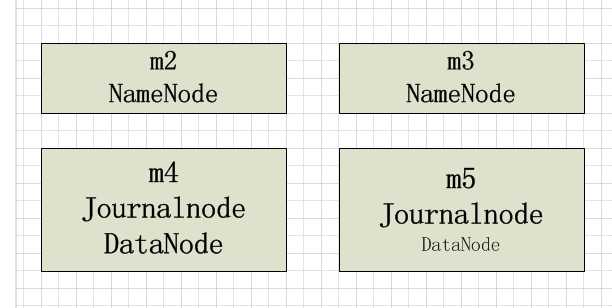
HDFS HA主要是通过Quorum Journal Manager (QJM)在Active NameNode和Standby NameNode之间共享edit logs
hdfs-site.xml的配置
dfs.nameservices - nameservice的逻辑名称,可以是任意的名称,此处配置为cluster
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
dfs.ha.namenodes.[nameservice ID] - 配置nameservice中的每一个NameNode, NameNode的个数建议不超过5个,最好是3个,此处配置两个
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - 配置NameNode的RPC具体地址,m2和m3为主机名
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>m2:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>m3:9820</value>
</property>
dfs.namenode.http-address.[nameservice ID].[name node ID] - 配置NameNode HTTP监听的地址
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>m2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>m3:9870</value>
</property>
dfs.namenode.shared.edits.dir - 配置JournalNodes上NameNode读和写的edits文件URL地址,URL格式: qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://m4:8485;m5:8485;/mycluster</value>
</property>
dfs.client.failover.proxy.provider.[nameservice ID] - HDFS客户端联系Active NameNode的java类
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPr
ovider</value>
</property>
dfs.ha.fencing.methods - 防止脑裂,两种方法,此处使用shell 这种方法
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(shell(/bin/true))</value>
</property>
dfs.journalnode.edits.dir - JournalNode存储本地状态的路径
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value>
</property>
core-site.xml配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value>
</property>
至此配置已经结束,接下来启动集群。
1、首先启动journalnode,通过./hadoop-daemon.sh start journalnode命令启动journalnode(m4, m5节点)
jps:可以发现JournalNode进程
2、通过hdfs namenode -format命令初始化集群,格式化完成后拷贝元数据到另外一个namenode节点上
3、启动hadoop集群start-dfs.sh
4、通过hdfs haadmin手动切换namenode是否为active
hadoop NameNode 手动HA的更多相关文章
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- Hadoop NameNode 高可用 (High Availability) 实现解析
转载自:http://reb12345reb.iteye.com/blog/2306818 在 Hadoop 的整个生态系统中,HDFS NameNode 处于核心地位,NameNode 的可用性直接 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析[转]
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- 【转载】Hadoop NameNode 高可用 (High Availability) 实现解析
转载:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/ NameNode 高可用整体架构概述 在 Had ...
- NameNode的HA
HDFS中的NameNode的HA怎么实现?(一言以蔽之) 在Hadoop集群中配置并启动两个NameNode进程,一个作为Active节点对外提供服务,另一个作为Standby的节点,两个NameN ...
随机推荐
- 连连看beta发布
组名:天天向上 组长:王森 组员:张政.张金生.林莉.胡丽娜 代码地址:HTTPS:https://git.coding.net/jx8zjs/llk.git SSH:git@git.coding.n ...
- JitterBuffer
jitter buffer QoS的解决方案 注:此博客中的某些说法是有问题的,如65536的整数倍,则其buffer会太大=>64k*1.5k=98M,另在超时处理中也有问题 VOIP中何为动 ...
- HRBUST 1430 矩阵快速幂
没错就是这道模板题我做了一个小时...我居然在看第一眼就认为是快速幂的情况下强行找了一发瞬时求出的规律 每个阶段有黑白两种 a[i].black=a[i-1].black*3+a[i].white ...
- laravel url() 和 asset() 的区别
asset()方法用于引入 CSS/JavaScript/images 等文件,文件必须存放在public文件目录下.url()方法生成一个完整的网址.
- PHP函数补完 - var_export
var_export() 函数返回关于传递给该函数的变量的结构信息,它和 var_dump() 类似,不同的是其返回的表示是合法的 PHP 代码.var_export必须返回合法的php代码, 也就是 ...
- OAuth2.0协议
简介 OAuth(Open Authorization),协议为用户资源的授权提供了一个安全的.开放而又简易的标准.与以往的授权方式不同之处是OAuth的授权不会使第三方触及到用户的帐号信息(如用户 ...
- wordpress 添加自定义菜单到管理面板(wp-admin)
如果你在做 wordpress 主题或插件的开发,通常需要在后台dashboard管理面板添加菜单方便用户做主题设置或插件设置.这篇文章要讨论的问题就是怎么样加这个菜单,加在哪里? 添加顶级菜单项 a ...
- ArcGIS Server 缓存服务切图范围
win10 + Server 10.4 + ArcMap 10.4 ArcGIS Server 缓存服务分为创建服务后手动建立缓存和创建服务时同时自动建立缓存两种. 10.2帮助文档:http:/ ...
- Java反射机制深入研究
ava 反射是Java语言的一个很重要的特征,它使得Java具体了“动态性”. 在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能否调用它的任意一个方法? ...
- Yii2 捕获错误日志
在技术开发中,捕获程序框架错误,是非常必要的一件事情,我们公司使用Yii2框架,简单说下Yii2的错误捕获处理 Yii2 web应用 1 配置如下 其中errorHandler就是错误处理配置,执行E ...