hadoop NameNode 手动HA
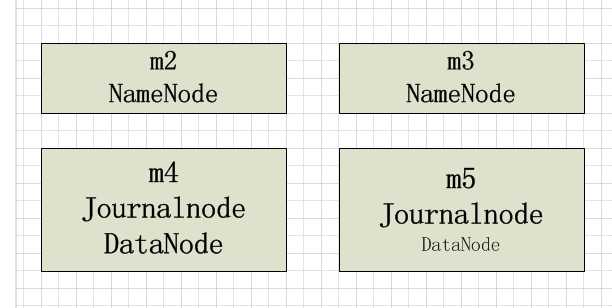
HDFS HA主要是通过Quorum Journal Manager (QJM)在Active NameNode和Standby NameNode之间共享edit logs
hdfs-site.xml的配置
dfs.nameservices - nameservice的逻辑名称,可以是任意的名称,此处配置为cluster
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
dfs.ha.namenodes.[nameservice ID] - 配置nameservice中的每一个NameNode, NameNode的个数建议不超过5个,最好是3个,此处配置两个
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - 配置NameNode的RPC具体地址,m2和m3为主机名
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>m2:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>m3:9820</value>
</property>
dfs.namenode.http-address.[nameservice ID].[name node ID] - 配置NameNode HTTP监听的地址
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>m2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>m3:9870</value>
</property>
dfs.namenode.shared.edits.dir - 配置JournalNodes上NameNode读和写的edits文件URL地址,URL格式: qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://m4:8485;m5:8485;/mycluster</value>
</property>
dfs.client.failover.proxy.provider.[nameservice ID] - HDFS客户端联系Active NameNode的java类
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPr
ovider</value>
</property>
dfs.ha.fencing.methods - 防止脑裂,两种方法,此处使用shell 这种方法
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(shell(/bin/true))</value>
</property>
dfs.journalnode.edits.dir - JournalNode存储本地状态的路径
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value>
</property>
core-site.xml配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value>
</property>
至此配置已经结束,接下来启动集群。
1、首先启动journalnode,通过./hadoop-daemon.sh start journalnode命令启动journalnode(m4, m5节点)
jps:可以发现JournalNode进程
2、通过hdfs namenode -format命令初始化集群,格式化完成后拷贝元数据到另外一个namenode节点上
3、启动hadoop集群start-dfs.sh
4、通过hdfs haadmin手动切换namenode是否为active
hadoop NameNode 手动HA的更多相关文章
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- Hadoop NameNode 高可用 (High Availability) 实现解析
转载自:http://reb12345reb.iteye.com/blog/2306818 在 Hadoop 的整个生态系统中,HDFS NameNode 处于核心地位,NameNode 的可用性直接 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析[转]
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- 【转载】Hadoop NameNode 高可用 (High Availability) 实现解析
转载:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/ NameNode 高可用整体架构概述 在 Had ...
- NameNode的HA
HDFS中的NameNode的HA怎么实现?(一言以蔽之) 在Hadoop集群中配置并启动两个NameNode进程,一个作为Active节点对外提供服务,另一个作为Standby的节点,两个NameN ...
随机推荐
- 修改编码格式MySQL
修改字符集的方法,就是使用mysql的命令 mysql> SET character_set_client = utf8 ; mysql> SET character_set_connec ...
- OC中属性及方法
1.声明式属性 a.实例变量 b.声明属性 自动生成setter/getter方法 .h ->@property 属性类型 属性名; .m ...
- 2016.09.14,英语,《Using English at Work》全书笔记
半个月时间,听完了ESLPod出品的<Using English at Work>,笔记和自己听的时候的备注列在下面.准备把每个语音里的快速阅读部分截取出来,放在手机里反复听. 下一阶段把 ...
- DWZ框架一些技巧
DWZ框架from表单提交后关闭对话框 注意大小写 <input type="hidden" name="callbackType" value=&quo ...
- Unity中的协程(一)
这篇文章很不错的问题,推荐阅读英文原版: Introduction to Coroutines Scripting with Coroutines 这篇文章转自:http://blog.csdn. ...
- C与C++连续赋值的区别
int a,b,c,d; a = b = ; // ( a!=b?a:b) = 1000;//如果a不等于b 那么a = 100;这句话执行完 a还是等于5,b= 100: printf(" ...
- 20145235李涛 《Java程序设计》第3周学习总结
类与对象 定义类 类是对象的“设计图”,对象是类的实际类型.另外,定义时用class,建实例用new. 通过书上的代码才有所理解: class Clothes { String color; char ...
- 百度Ueditor编辑器的Html模式自动替换样式的解决方法
百度的Ueditor编辑器出于安全性考虑,用户在html模式下粘贴进去的html文档会自动被去除样式和转义.虽然安全的,但是非常不方便. 做一下修改把这个功能去掉. 一.打开ueditor.all.j ...
- SQL Server加密存储过程的破解
建好sp后,在“连接到数据库引擎”对话框的“服务器名称”框中,键入 ADMIN:,并在其后继续键入服务器实例的名称.例如,若要连接到名为 ACCT\PAYABLE 的服务器实例,请键入 ADMIN:A ...
- java实验一实验报告
Java实验报告一:Java开发环境的熟悉 ...