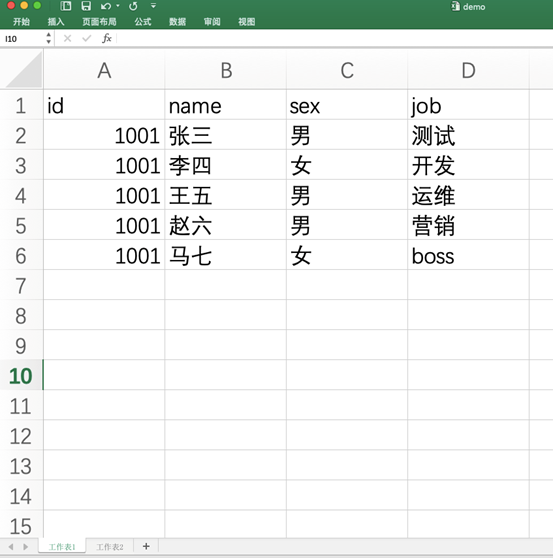
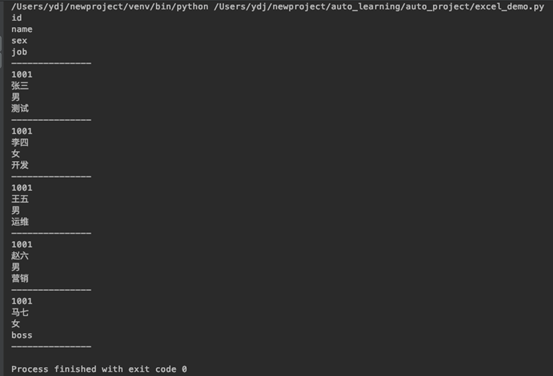
如何在Python对Excel进行读取
pip install xlrd



如何在Python对Excel进行读取的更多相关文章
- 用python在excel中读取与生成随机数写入excel中
今天是我第一次发博客,就关于python在excel中的应用作为我的第一篇吧. 具体要求是:在一份已知的excel表格中读取学生的学号与姓名,再将这些数据放到新的excel表中的第一列与第二列,最后再 ...
- python对Excel的读取
在python自动化中,经常会遇到对数据文件的操作,比如添加多名员工,但是直接将员工数据写在python文件中,不但工作量大,要是以后再次遇到类似批量数据操作还会写在python文件中吗? 应对这一问 ...
- python从excel中读取数据传给其他函数使用
首先安装xlrd库 pip install xlrd 方法1: 表格内容如下: 场景描述,读取该表格A列数据,然后打印出数据 代码何解析如下: import xlrd #引入xlrd库 def exc ...
- python openpyxl模块实现excel的读取,新表创建及原数据表追加新数据
当实际工作需要把excel表的数据读取出来,或者把一些统计数据写入excel表中时,一个设计丰富,文档便于寻找的模块就会显得特别的有吸引力,本文对openpyxl模块的一些常见用法做一些记录,方便工作 ...
- 一篇文章告诉你Python接口自动化测试中读取Text,Excel,Yaml文件的方法
前言 不管是做Ui自动化和接口自动,代码和数据要分离,会用到Text,Excel,Yaml.今天讲讲如何读取文件数据 Python也可以读取ini文件,传送门 记住一点:测试的数据是不能写死在代码里面 ...
- 记录python接口自动化测试--从excel中读取params参数传入requests请求不生效问题的解决过程(第七目)
在第六目把主函数写好了,先来运行一下主函数 从截图中可以看到,请求参数打印出来了,和excel中填写的一致 但是每个接口的返回值却都是400,提示参数没有传进去,开始不知道是什么原因(因为excel中 ...
- [转]用Python读写Excel文件
[转]用Python读写Excel文件 转自:http://www.gocalf.com/blog/python-read-write-excel.html#xlrd-xlwt 虽然天天跟数据打交 ...
- 转:Python 与 Excel 不得不说的事
数据处理是 Python 的一大应用场景,而 Excel 则是最流行的数据处理软件.因此用 Python 进行数据相关的工作时,难免要和 Excel 打交道. 如果仅仅是要以表单形式保存数据,可以借助 ...
- Python导出Excel为Lua/Json/Xml实例教程(三):终极需求
相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 Python导出E ...
随机推荐
- 删库吧,Bug浪——我们在同一家摸鱼的公司
那些口口声声, Bug越来越难写人的,应该盯着你们: 像我一样,我盯着你们,满眼恨意. IT积攒了几十年的漏洞, 所有的死机.溢出.404和超时, 像是专门为你们准备的礼物. 圈复杂度.魔鬼变量.内存 ...
- CentOS 7 Nacos 集群搭建
环境 CentOS 7.4 MySQL 5.7 nacos-server-1.1.2 本次安装的软件全部在 /home/javateam 目录下. MySQL 安装 首先下载 rpm 安装包,地址:h ...
- 01[了解] Dubbo
什么是Dubbo? 概述 Dubbo是阿里巴巴内部使用的分布式业务框架,2012年由阿里巴巴开源. 由于Dubbo在阿里内部经过广泛的业务验证,在很短时间内,Dubbo就被许多互联网公司所采用,并产生 ...
- Java 反射简介
本文部分内容参考博客.点击链接可以查看原文. 1. 反射的概念 反射是指在运行时将类的属性.构造函数和方法等元素动态地映射成一个个对象.通过这些对象我们可以动态地生成对象实例,调用类的方法和更改类的属 ...
- 云服务器解析域名去掉Tomcat的8080端口号显示
- 优雅关闭服务下线(Jetty)
在很多时候 kill -9 pid并不是很友好的方法,那样会将我们正在执行请求给断掉,同时eureka 中服务依旧是处于在线状态,这个时候我们可以使用官方提供的actuator来做优雅的关闭处理 - ...
- Redis 6.0 访问控制列表ACL说明
背景 在Redis6.0之前的版本中,登陆Redis Server只需要输入密码(前提配置了密码 requirepass )即可,不需要输入用户名,而且密码也是明文配置到配置文件中,安全性不高.并且应 ...
- vs2017+opencv3.4.0的配置方法
1.尝试了这个博客的方法: https://blog.csdn.net/u014574279/article/details/50909425/ 结果: 无法打开文件“opencv_ml2410d.l ...
- css自动省略号...,通过css实现单行、多行文本溢出显示省略号
网页开发过程中经常会遇到需要把多行文字溢出显示省略号,这篇文章将总结通过多种方法实现文本末尾省略号显示. 一.单行文本溢出显示省略号(…) 省略号在ie中可以使用text-overflow:ellip ...
- 【盗版动归】Codeforces998C——Convert to Ones 归一操作
嘤嘤嘤,因为最近文化课老师追的紧了+班主任开班会,所以这博客是赶制的赝品 题目: You've got a string a1,a2,…,ana1,a2,…,an, consisting of zer ...