MySQL索引介绍和实战
索引是什么
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构,索引的目的是提高查询效率,可以类比英语新华字典,根据目录定位词语
如果没有目录呢,就需要从A到Z,去遍历的查找一遍,一个一个找和直接根据目录定位到数据,差的就是天壤之别
索引底层数据结构
数据库除了存储数据本身之外,还维护着一个满足特定查找算法的数据结构,这些结构以某种方式指向数据,这样就可以基于这些数据结构实现高效查找算法。这种结构就是索引,MySQL中索引是B+树实现的,每个索引都对应一棵B+树
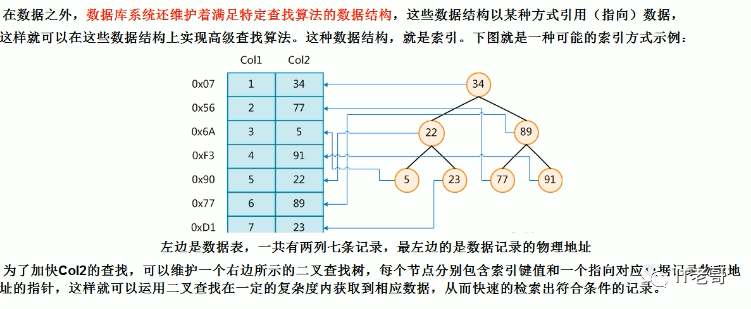
索引的优势
提高数据检索效率,降低数据库IO成本
通过索引列对数据进行排序,降低数据排序成本,降低了CPU消耗
索引的劣势
一个索引都为对应一棵B+树,树中每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,所以一个索引也是会占用磁盘空间的。(空间的代价)
索引是对数据的排序,当对表中的数据进行增、删、改操作时,都要维护修改内容涉及到的B+树索引。所以在进行这些操作时需要额外的时间进行一些记录移动,页面分裂、页面回收等操作来维护索引(时间上的代价)
索引语法
以test_user表为例,建表sql如下
CREATE TABLE `test_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` varchar(36) NOT NULL COMMENT '用户id',
`user_name` varchar(30) NOT NULL COMMENT '用户名称',
`phone` varchar(20) NOT NULL COMMENT '手机号码',
`lan_id` int(9) NOT NULL COMMENT '本地网',
`region_id` int(9) NOT NULL COMMENT '区域',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1010001 DEFAULT CHARSET=utf8mb4;
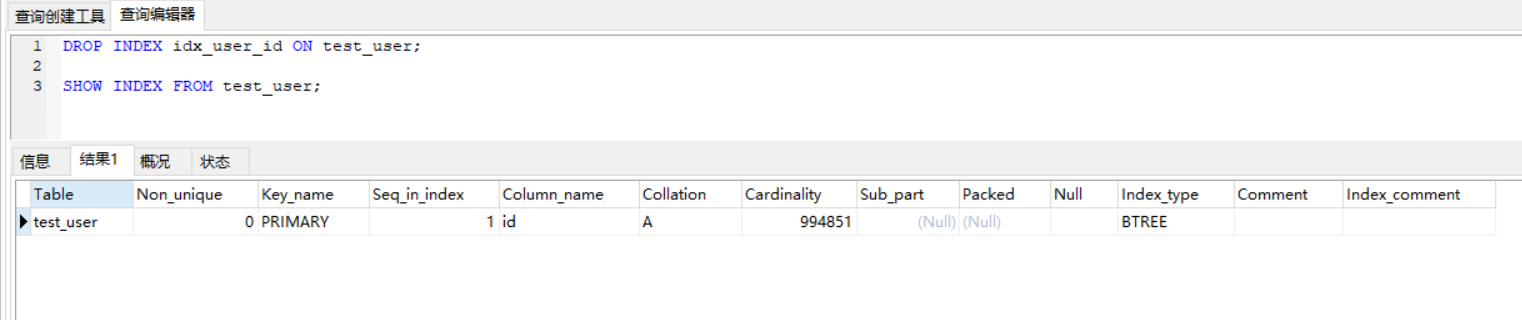
1.查看索引:SHOW INDEX FROM table_name\G
SHOW INDEX FROM test_user;

2.删除索引:DROP INDEX [indexName] ON mytable;
DROP INDEX idx_user_id ON test_user;
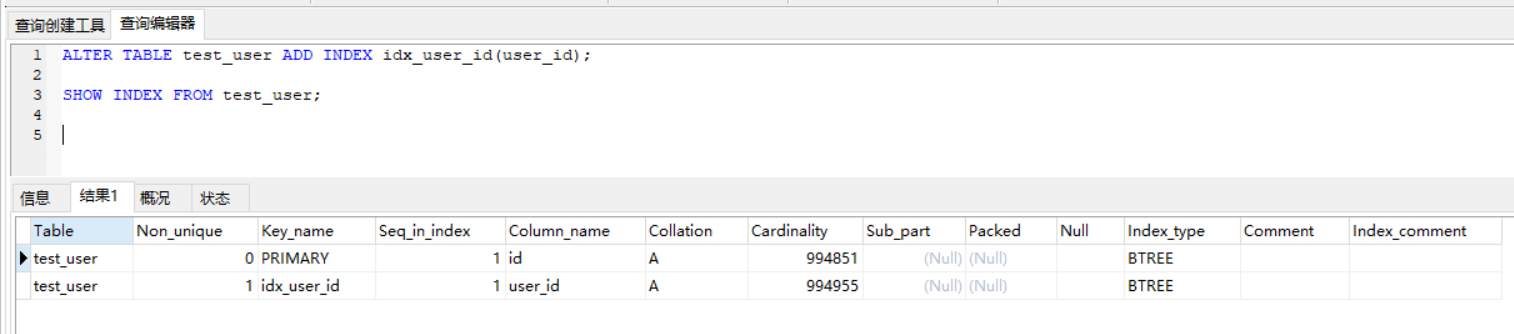
3.创建索引 alter tableName add [unique] index [indexName] on (columnName (length) )
ALTER TABLE test_user ADD INDEX idx_user_id(user_id);
哪些情况需要建索引
- 主键自动建立唯一索引
- 频繁作为查询的条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引:因为每次更新不单单是更新了记录还会更新索引,加重IO负担
- Where条件里用不到的字段不创建索引
- 单间/组合索引的选择问题(在高并发下倾向创建组合索引)
- 查询中排序的字段,若通过索引去访问将大大提高排序的速度
- 查询中统计或者分组字段
哪些不适合建索引
表记录太少
经常增删改的表
数据重复且分布平均的表字段,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
索引实战
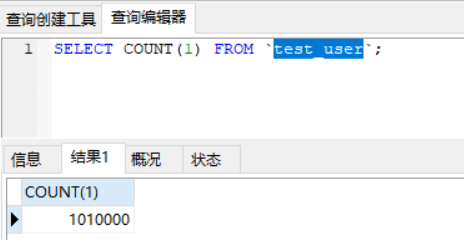
我们在test_user表中有100万数据
优化一:使用全部索引
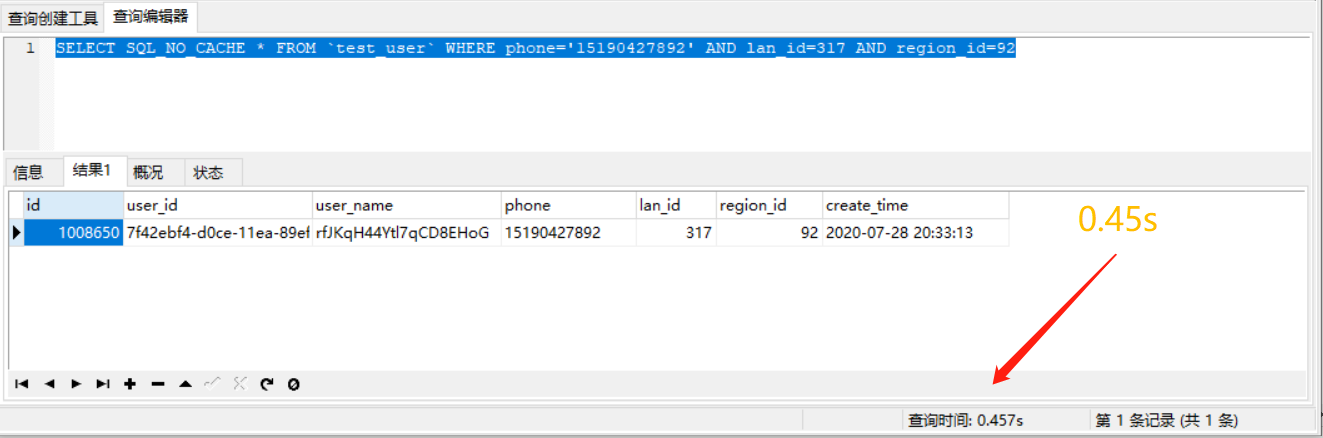
1.不加索引,关闭缓存查一条数据
SELECT SQL_NO_CACHE * FROM `test_user` WHERE phone='' AND lan_id=317 AND region_id=92
2.加一条复合索引
ALTER TABLE test_user ADD INDEX idx_phone_lan_region(phone,lan_id,region_id);
再查一次,看结果
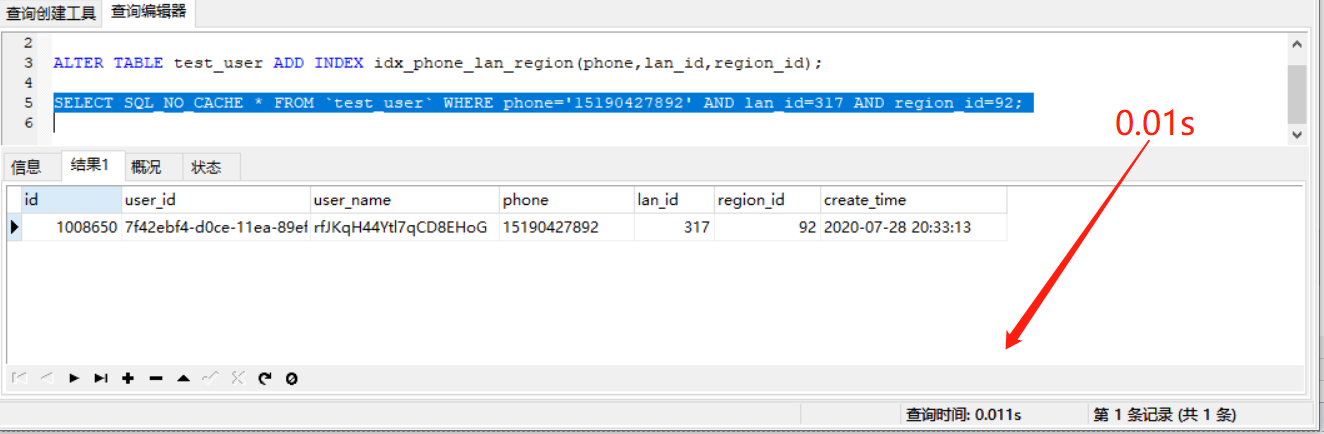
可以看到,加了索引以后,查询效率提高了很多
这里我们建立的复合索引包含的3个字段,查询的时候全部用到了,而且where中的条件严格按照索引顺序,这样查询效率是最高的
我们使用EXPLAIN关键字看一下
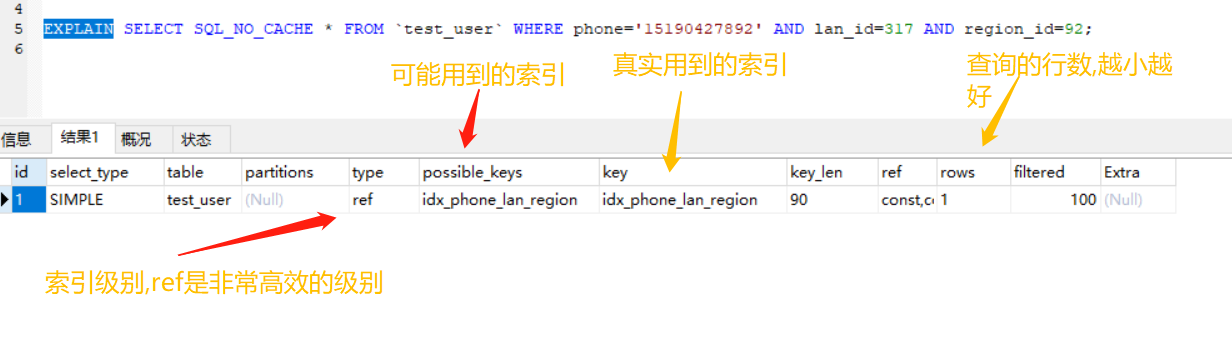
优化二:最左前缀法则
我们把上面那个例子的第一个插件条件删掉
EXPLAIN SELECT SQL_NO_CACHE * FROM `test_user` WHERE lan_id=317 AND region_id=92;
我们使用EXPLAIN关键字看一下
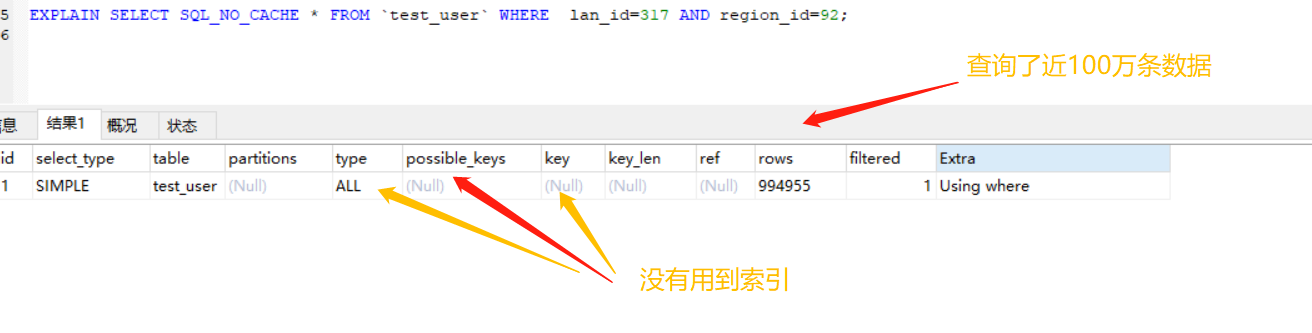
因此,我们得出结论:如果建立的是复合索引,索引的顺序要按照建立时的顺序,即从左到右,如:a->b->c(和 B+树的数据结构有关)
无效索引举例
- a->c:a 有效,c 无效
- b->c:b、c 都无效
- c:c 无效
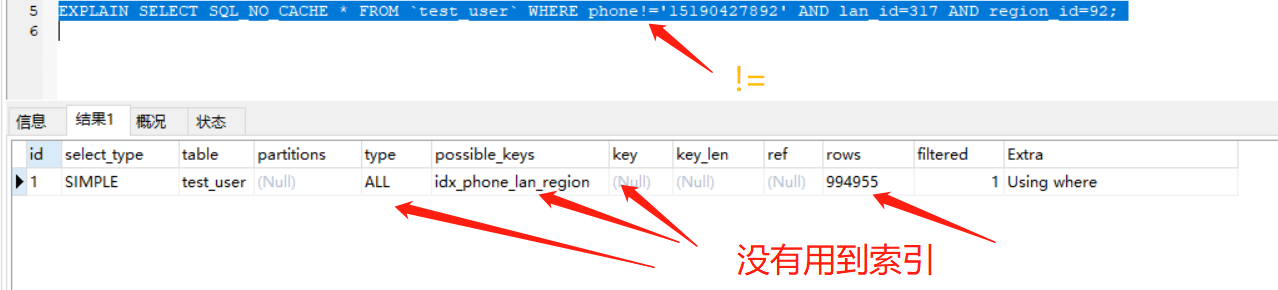
优化三:不要对索引做以下处理
- 计算,如:+、-、*、/、!=、<>、is null、is not null、or
- 函数,如:sum()、round()等等
- 手动/自动类型转换,如:id = "1",本来是数字,给写成字符串了
我们以!=为例演示,我们使用EXPLAIN关键字看一下
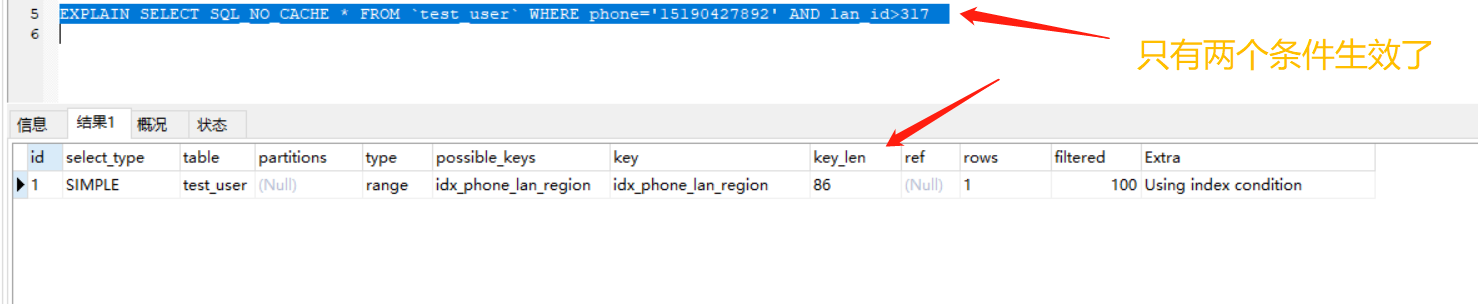
优化四:索引不要放在范围查询右边
比如复合索引:a->b->c,当 where a="" and b>10 and c="",这时候只能用到 a 和 b,c 用不到索引,因为在范围之后索引都失效(和 B+树结构有关)
如下
EXPLAIN SELECT SQL_NO_CACHE * FROM `test_user` WHERE phone='' AND lan_id>317 AND region_id=92;
我们使用EXPLAIN关键字看一下

我们把最后一个条件删除,再看一下
优化五:减少 select * 的使用
select *会查询很多不必要的字段,造成不必要的网络传输和IO消耗
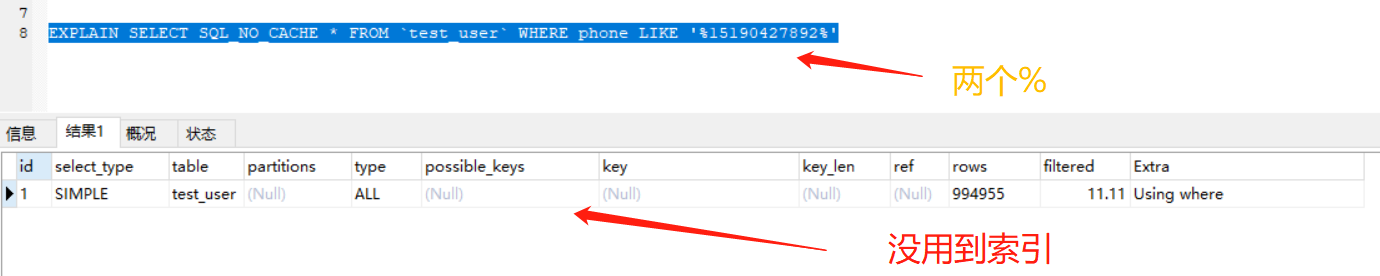
优化六:like 模糊搜索
失效情况
- like "%张三%"
- like "%张三"
解决方案
- 使用复合索引,即 like 字段是 select 的查询字段,如:select name from table where name like "%张三%"
- 使用 like "张三%"


优化七:order by 优化
当查询语句中使用 order by 进行排序时,如果没有使用索引进行排序,会出现 filesort 文件内排序,这种情况在数据量大或者并发高的时候,会有性能问题,需要优化。
filesort 出现的情况举例
- order by 字段不是索引字段
- order by 字段是索引字段,但是 select 中没有使用覆盖索引,如:
select * from staffs order by age asc; - order by 中同时存在 ASC 升序排序和 DESC 降序排序,如:
select a, b from staffs order by a desc, b asc; - order by 多个字段排序时,不是按照索引顺序进行 order by,即不是按照最左前缀法则,如:
select a, b from staffs order by b asc, a asc;
如下情况没有索引

filesort 文件内排序会在内存开辟一块空间,然后把数据复制了一份放到这个空间内,再进行排序,这个是很影响性能的
我们可以为这个字段建一个索引
ALTER TABLE test_user ADD INDEX idx_create_time(create_time);

索引层面解决方法
- 使用主键索引排序
- 按照最左前缀法则,并且使用覆盖索引排序,多个字段排序时,保持排序方向一致
- 在 SQL 语句中强制指定使用某索引,force index(索引名字)
- 不在数据库中排序,在代码层面排序
优化八:group by
其原理也是先排序后分组,其优化方式可参考order by。where高于having,能写在where限定的条件就不要去having限定了。
MySQL索引介绍和实战的更多相关文章
- mysql性能优化-慢查询分析、优化索引和配置 MySQL索引介绍
MySQL索引介绍 聚集索引(Clustered Index)----叶子节点存放整行记录辅助索引(Secondary Index)----叶子节点存放row identifier-------Inn ...
- MySQL索引介绍
引言 今天Qi号与大家分享什么是索引.其实索引:索引就相当于书的目录 索引介绍 用官方的话说就是 索引是为了加速对表中数据行的检索而创建的一种分散的存储结构.索引是针对表而建立的,它是由数据页面以外的 ...
- Mysql索引介绍及常见索引(主键索引、唯一索引、普通索引、全文索引、组合索引)的区别
Mysql索引概念:说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要 ...
- Mysql索引介绍及常见索引的区别
关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车.对于没有索引的表,单表查询可能几十万数据就是瓶颈,而通常大型 ...
- 【真·干货】MySQL 索引及优化实战
热烈推荐:超多IT资源,尽在798资源网 声明:本文为转载文章,为防止丢失所以做此备份. 本文来自公众号:GitChat精品课 原文地址:https://mp.weixin.qq.com/s/6V7h ...
- MySQL索引介绍+索引的存储类型+索引的优点和缺点+索引的分类+删除索引
什么是索引? 索引用于快速找出某个列中有一特定值的行,不使用索引,mysql必须从第1条记录开始读完整的表,直到找出相关的行.表越大,查询数据所花费的实际越多.如果表中查询的列有一个索引,mysql能 ...
- Mysql系列(六)—— MySQL索引介绍
前言 索引种类 索引维护 如何使用索引 一.索引索引种类 MySQL中索引主要包含以下几种: 普通索引 唯一索引 主键索引 联合索引 全文索引 二.索引维护 在简述了索引的类型后,再来了解下如何维护索 ...
- mysql 索引介绍与运用
索引 (1)什么是索引? 是一种提升查询速度的 特殊的存储结构. 它包含了对数据表里的记录的指针,类似于字典的目录. 当我们添加索引时会单独创建一张表来去存储和管理索引,索引比原数据大,会占用更多的资 ...
- MySQL 索引及优化实战
https://blog.csdn.net/qq_21987433/article/details/79753551 https://tech.meituan.com/mysql_index.html ...
随机推荐
- QtableWidget用法流程
QtableWidget用法流程 作者:流火 日期:2020/5/10 QTableWidget的基本构造函数 QTableWidget 是QTableview的子类.主要去呗是QTableVie ...
- Zookeeper 序列化
读完这篇文章你将会收获到 在 Zookeeper 源码项目中新建模块,使用 Jute 进行序列化和反序列化 修改 Jute 中的 buffer size 来序列化/反序列化大对象 序言 从 前面的文章 ...
- Java 从入门到进阶之路(二十八)
在之前的文章我们都是通过 Java 在内存中应用,本章开始我们来看一下 Java 在系统文件(硬盘)上的操作. 系统文件就是我们电脑中的文件,简单来说就是像 Windows 系统中 C D E 等各类 ...
- html实现邮箱发送邮件_js发送邮件至指定邮箱功能
在前端开发中,JavaScript并没有提供直接操作Email邮箱的功能方法,但是遇到这样的需求,我们应该如何实现js发送邮件至指定邮箱功能呢?下面列举能够在通过前端实现邮件发送的几种方式: 方式一: ...
- Python 之父说 Python 历史
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:鸿影洲冷 这篇文章主要内容来源于 Python 编程语言的最初设计者 ...
- Numerical Sequence(hard version),两次二分
题目: 题意: 已知一个序列: 112123123412345123456123456712345678123456789123456789101234567891011... 求这个序列第k个数是多 ...
- 朋友HDU - 5963 (思维题) 三种方法
传送门 题目描述 输入 输出 样例输入 Sample Input 样例输出 Boys win! Girls win! Girls win! Boys win! Girls win! Boys win! ...
- Django---进阶14
目录 登陆功能 首页搭建 admin后台管理 用户头像展示 图片防盗链 个人站点 侧边栏筛选功能 登陆功能 def login(request): if request.method == 'POST ...
- javaWeb7——PrepareStatement原理,Pareparedstatement和Statement的区别
查询数据返回的结果集: ResulSet: 代码实现 : PrepareStatement原理 代码实现: Pareparedstatement和Statement的区别: 注意: Statement ...
- log4j系统日志(转载)
地址:http://www.codeceo.com/log4j-usage.html 日志是应用软件中不可缺少的部分,Apache的开源项目log4j是一个功能强大的日志组件,提供方便的日志记录.在a ...