Flink可靠性的基石-checkpoint机制详细解析
Checkpoint介绍
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状态的一致性。Flink的checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
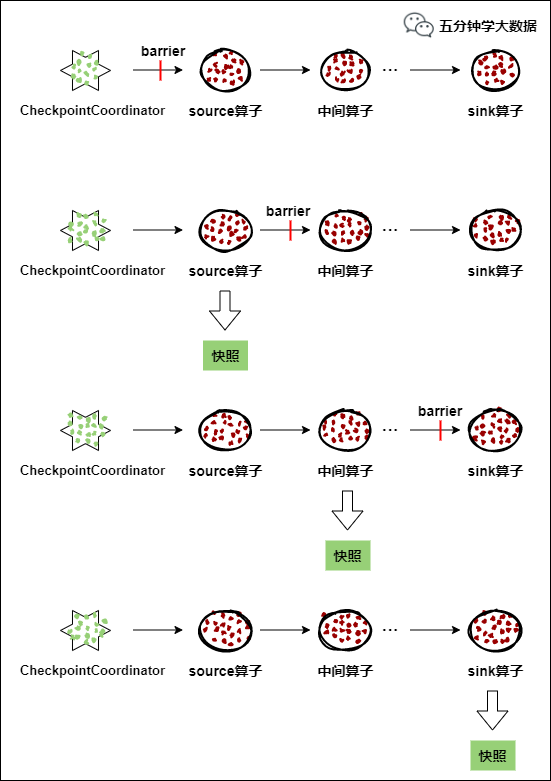
CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
如果一个算子有两个输入源,则暂时阻塞先收到barrier的输入源,等到第二个输入源相 同编号的barrier到来时,再制作自身快照并向下游广播该barrier。具体如下图所示:
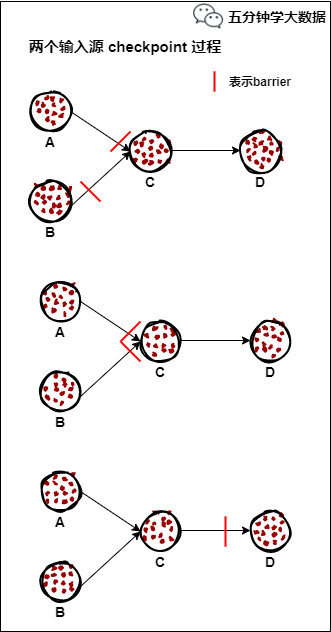
假设算子C有A和B两个输入源
在第i个快照周期中,由于某些原因(如处理时延、网络时延等)输入源A发出的 barrier 先到来,这时算子C暂时将输入源A的输入通道阻塞,仅收输入源B的数据。
当输入源B发出的barrier到来时,算子C制作自身快照并向 CheckpointCoordinator 报告自身的快照制作情况,然后将两个barrier合并为一个,向下游所有的算子广播。
当由于某些原因出现故障时,CheckpointCoordinator通知流图上所有算子统一恢复到某个周期的checkpoint状态,然后恢复数据流处理。分布式checkpoint机制保证了数据仅被处理一次(Exactly Once)。
持久化存储
MemStateBackend
该持久化存储主要将快照数据保存到JobManager的内存中,仅适合作为测试以及快照的数据量非常小时使用,并不推荐用作大规模商业部署。
MemoryStateBackend 的局限性:
默认情况下,每个状态的大小限制为 5 MB。可以在MemoryStateBackend的构造函数中增加此值。
无论配置的最大状态大小如何,状态都不能大于akka帧的大小(请参阅配置)。
聚合状态必须适合 JobManager 内存。
建议MemoryStateBackend 用于:
本地开发和调试。
状态很少的作业,例如仅包含一次记录功能的作业(Map,FlatMap,Filter,...),kafka的消费者需要很少的状态。
FsStateBackend
该持久化存储主要将快照数据保存到文件系统中,目前支持的文件系统主要是 HDFS和本地文件。如果使用HDFS,则初始化FsStateBackend时,需要传入以 “hdfs://”开头的路径(即: new FsStateBackend("hdfs:///hacluster/checkpoint")), 如果使用本地文件,则需要传入以“file://”开头的路径(即:new FsStateBackend("file:///Data"))。在分布式情况下,不推荐使用本地文件。如果某 个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败。
建议FsStateBackend:
具有大状态,长窗口,大键 / 值状态的作业。
所有高可用性设置。
RocksDBStateBackend
RocksDBStatBackend介于本地文件和HDFS之间,平时使用RocksDB的功能,将数 据持久化到本地文件中,当制作快照时,将本地数据制作成快照,并持久化到 FsStateBackend中(FsStateBackend不必用户特别指明,只需在初始化时传入HDFS 或本地路径即可,如new RocksDBStateBackend("hdfs:///hacluster/checkpoint")或new RocksDBStateBackend("file:///Data"))。
如果用户使用自定义窗口(window),不推荐用户使用RocksDBStateBackend。在自定义窗口中,状态以ListState的形式保存在StatBackend中,如果一个key值中有多个value值,则RocksDB读取该种ListState非常缓慢,影响性能。用户可以根据应用的具体情况选择FsStateBackend+HDFS或RocksStateBackend+HDFS。
语法
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000)
// advanced options:
// 设置checkpoint的执行模式,最多执行一次或者至少执行一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 设置checkpoint的超时时间
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 如果在只做快照过程中出现错误,是否让整体任务失败:true是 false不是
env.getCheckpointConfig.setFailTasksOnCheckpointingErrors(false)
//设置同一时间有多少 个checkpoint可以同时执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
修改State Backend的两种方式
第一种:单任务调整
修改当前任务代码
env.setStateBackend(new FsStateBackend("hdfs://namenode:9000/flink/checkpoints"));
或者new MemoryStateBackend()
或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依赖】
第二种:全局调整
修改flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
注意:state.backend的值可以是下面几种:jobmanager(MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
Checkpoint的高级选项
默认checkpoint功能是disabled的,想要使用的时候需要先启用checkpoint开启之后,默认的checkPointMode是Exactly-once
//配置一秒钟开启一个checkpoint
env.enableCheckpointing(1000)
//指定checkpoint的执行模式
//两种可选:
//CheckpointingMode.EXACTLY_ONCE:默认值
//CheckpointingMode.AT_LEAST_ONCE
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
一般情况下选择CheckpointingMode.EXACTLY_ONCE,除非场景要求极低的延迟(几毫秒)
注意:如果需要保证EXACTLY_ONCE,source和sink要求必须同时保证EXACTLY_ONCE
//如果程序被cancle,保留以前做的checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
默认情况下,检查点不被保留,仅用于在故障中恢复作业,可以启用外部持久化检查点,同时指定保留策略:
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:在作业取消时保留检查点,注意,在这种情况下,您必须在取消后手动清理检查点状态
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业在被cancel时,删除检查点,检查点仅在作业失败时可用
//设置checkpoint超时时间
env.getCheckpointConfig.setCheckpointTimeout(60000)
//Checkpointing的超时时间,超时时间内没有完成则被终止
//Checkpointing最小时间间隔,用于指定上一个checkpoint完成之后
//最小等多久可以触发另一个checkpoint,当指定这个参数时,maxConcurrentCheckpoints的值为1
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
//设置同一个时间是否可以有多个checkpoint执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
指定运行中的checkpoint最多可以有多少个
env.getCheckpointConfig.setFailOnCheckpointingErrors(true)
用于指定在checkpoint发生异常的时候,是否应该fail该task,默认是true,如果设置为false,则task会拒绝checkpoint然后继续运行
Flink的重启策略
Flink支持不同的重启策略,这些重启策略控制着job失败后如何重启。集群可以通过默认的重启策略来重启,这个默认的重启策略通常在未指定重启策略的情况下使用,而如果Job提交的时候指定了重启策略,这个重启策略就会覆盖掉集群的默认重启策略。
概览
默认的重启策略是通过Flink的 flink-conf.yaml 来指定的,这个配置参数 restart-strategy 定义了哪种策略会被采用。如果checkpoint未启动,就会采用 no restart 策略,如果启动了checkpoint机制,但是未指定重启策略的话,就会采用 fixed-delay 策略,重试 Integer.MAX_VALUE 次。请参考下面的可用重启策略来了解哪些值是支持的。
每个重启策略都有自己的参数来控制它的行为,这些值也可以在配置文件中设置,每个重启策略的描述都包含着各自的配置值信息。
| 重启策略 | 重启策略值 |
|---|---|
| Fixed delay | fixed-delay |
| Failure rate | failure-rate |
| No restart | None |
除了定义一个默认的重启策略之外,你还可以为每一个Job指定它自己的重启策略,这个重启策略可以在 ExecutionEnvironment 中调用 setRestartStrategy() 方法来程序化地调用,注意这种方式同样适用于 StreamExecutionEnvironment。
下面的例子展示了如何为Job设置一个固定延迟重启策略,一旦有失败,系统就会尝试每10秒重启一次,重启3次。
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 延迟时间间隔
))
固定延迟重启策略(Fixed Delay Restart Strategy)
固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过了最大的重启次数,Job最终将失败。在连续的两次重启尝试之间,重启策略会等待一个固定的时间。
重启策略可以配置flink-conf.yaml的下面配置参数来启用,作为默认的重启策略:
restart-strategy: fixed-delay
| 配置参数 | 描述 | 默认值 |
|---|---|---|
| restart-strategy.fixed-delay.attempts | 在Job最终宣告失败之前,Flink尝试执行的次数 | 1,如果启用checkpoint的话是Integer.MAX_VALUE |
| restart-strategy.fixed-delay.delay | 延迟重启意味着一个执行失败之后,并不会立即重启,而是要等待一段时间。 | akka.ask.timeout,如果启用checkpoint的话是1s |
例子:
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
固定延迟重启也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))
失败率重启策略
失败率重启策略在Job失败后会重启,但是超过失败率后,Job会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
restart-strategy:failure-rate
| 配置参数 | 描述 | 默认值 |
|---|---|---|
| restart-strategy.failure-rate.max-failures-per-interval | 在一个Job认定为失败之前,最大的重启次数 | 1 |
| restart-strategy.failure-rate.failure-rate-interval | 计算失败率的时间间隔 | 1分钟 |
| restart-strategy.failure-rate.delay | 两次连续重启尝试之间的时间间隔 | akka.ask.timeout |
例子:
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启尝试的时间间隔
))
无重启策略
Job直接失败,不会尝试进行重启
restart-strategy: none
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())
搜索公众号:五分钟学大数据,发送 秘籍,即可获取大数据学习秘籍大礼包,深入钻研大数据技术!
Flink可靠性的基石-checkpoint机制详细解析的更多相关文章
- 面试必问:JVM类加载机制详细解析
前言 在Java面试中,简历上有写JVM(Java虚拟机)相关的东西,JVM的类加载机制基本是面试必问的知识点. 类的加载和卸载 JVM是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是cla ...
- Hibernate 缓存机制详细解析
一.why(为什么要用Hibernate缓存?) Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能. 缓存内的数据是对物理数 ...
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
- Flink状态管理和容错机制介绍
本文主要内容如下: 有状态的流数据处理: Flink中的状态接口: 状态管理和容错机制实现: 阿里相关工作介绍: 一.有状态的流数据处理# 1.1.什么是有状态的计算# 计算任务的结果不仅仅依赖于输入 ...
- [转]Android事件分发机制完全解析,带你从源码的角度彻底理解(上)
Android事件分发机制 该篇文章出处:http://blog.csdn.net/guolin_blog/article/details/9097463 其实我一直准备写一篇关于Android事件分 ...
- 转:二十一、详细解析Java中抽象类和接口的区别
转:二十一.详细解析Java中抽象类和接口的区别 http://blog.csdn.net/liujun13579/article/details/7737670 在Java语言中, abstract ...
- Mysql怎么判断繁忙 checkpoint机制 innodb的主要参数
Mysql怎么判断繁忙,innodb的主要参数,checkpoint机制,show engine innodb status 2018年07月13日 15:45:36 anzhen0429 阅读数 ...
- Spark cache、checkpoint机制笔记
Spark学习笔记总结 03. Spark cache和checkpoint机制 1. RDD cache缓存 当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出 ...
- ASP.NET机制详细的管道事件流程(转)
ASP.NET机制详细的管道事件流程 第一:浏览器向服务器发送请求. 1)浏览器向iis服务器发送请求网址的域名,根据http协议封装成请求报文,通过dns解析请求的ip地址,接着通过socket与i ...
随机推荐
- python简单的函数应用
一个简单的函数应用,包括自定义函数,lambda函数,列表解析. 1 #!usr/bin/env python3 2 # -*- coding:utf-8 -*- 3 4 #开始定义函数 5 def ...
- 如何在visual studio中,更改删除团队资源管理器的tfs地址 不能弹出来
C:\Users\Administrator\AppData\Roaming\Microsoft\VisualStudio\16.0_8c6724b7\Team Explorer 进入文件夹:AppD ...
- 【命令】set命令
1.查看所有的本地变量和环境变量. 2.检测变量是否定义: 开启检测功能: set -u 关闭检测功能: set +u [root@localhost likui]# unset mm 删除了m ...
- java.io.IOException: Target host must not be null, or set in parameters. scheme=null, host=null, path=/
使用的 xutils 出现标题中的错误 原因:没有添加 Cookie 1 params.addHeader("Cookie", CurrentUserSettings.getCoo ...
- C#——时间之不同国家的显示格式
对于时间的显示,不同的地方有不同的时间格式,代码如下: public class Common_DateFormat { public Common_DateFormat() { // // TODO ...
- 技术选型关于redis客户端选择
redis作为分布式缓存框架的首选 相信已经毋庸置疑.能高效.合理的使用好它 必定能提升系统的可用性,高性能.高吞吐量的保障.但选择一个客户端,充分发挥它的能力,就是一个选型问题.现在市场上能选择 ...
- 如何在Nginx不绑定域名下使用SSL/TLS证书?
前提 该文主要记录如何在没有购买域名的情况下使用SSL/TLS协议,即地址前面的http变成了https.但是这样的SSL协议是会被浏览器认为是不安全的.在开发或者测试环境可以这样搞,生产环境下还是乖 ...
- .NET 云原生架构师训练营(模块二 基础巩固 MongoDB 问答系统)--学习笔记
2.5.6 MongoDB -- 问答系统 MongoDB 数据库设计 API 实现概述 MongoDB 数据库设计 设计优化 内嵌(mongo)还是引用(mysql) 数据一致性 范式:将数据分散到 ...
- 认识PHP8
PHP 团队于2020年11月26日宣布 PHP 8 正式发布!这意味着将不会有 PHP 7.5 版本.PHP8 目前正处于非常活跃的开发阶段,所以在接下来的几个月里,情况可能会发生很大的变化.我也分 ...
- spark的thriftservr的高可用
triftserver是基于jdbc的一个spark的服务,可以做web查询,多客户端访问,但是thriftserver没有高可用,服务挂掉后就无法在访问,所有使用注册到zk的方式来实现高可用 一.版 ...