CKafka 架构原理
消息队列 CKafka 技术原理 - 产品简介 - 文档中心 - 腾讯云 https://cloud.tencent.com/document/product/597/10067
消息队列 CKafka 的架构图如下所示:
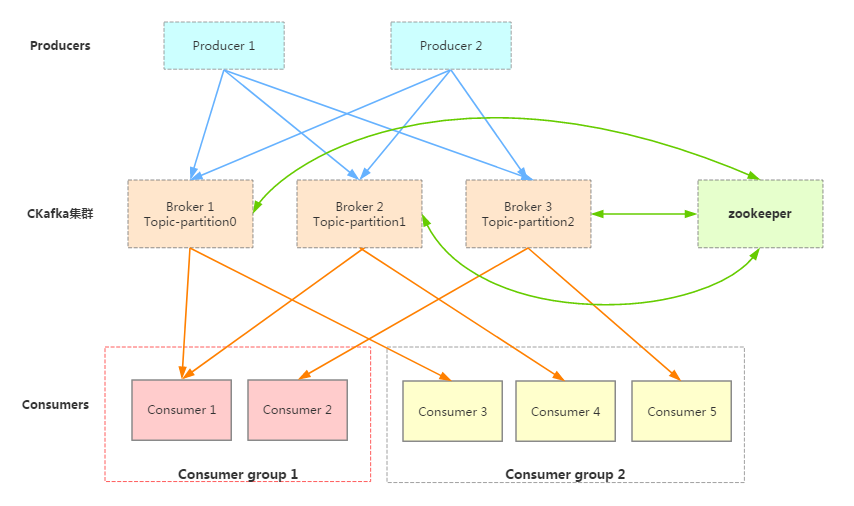
- 生产者 Producer 可能是网页活动产生的消息、服务日志等信息。生产者通过 push 模式将消息发布到 Cloud Kafka 的 Broker 集群。
- 集群通过 Zookeeper 管理集群配置,进行 leader 选举,故障容错等。
- 消费者 Consumer 被划分为若干个 Consumer Group。消费者通过 pull 模式从 Broker 中消费消息。
消息队列 CKafka 相比于自建开源 Apache Kafka 所具备的优势请参考 产品优势。
高吞吐
消息队列 CKafka 中存在大量的网络数据持久化到磁盘和磁盘文件通过网络发送的过程。这一过程的性能直接影响 Kafka 的整体吞吐量,主要通过以下几点实现:
- 高效使用磁盘:磁盘中顺序读写数据,提高磁盘利用率。
- 写 message:消息写到 page cache,由异步线程刷盘。
- 读 message:消息直接从 page cache 转入 socket 发送出去。
- 当从 page cache 没有找到相应数据时,此时会产生磁盘 IO,从磁盘加载消息到 page cache,然后直接从 socket 发出去。
- Broker 的零拷贝(Zero Copy)机制:使用 sendfile 系统调用,将数据直接从页缓存发送到网络上。
- 减少网络开销
- 数据压缩降低网络负载。
- 批处理机制:Producer 批量向 Broker 写数据、Consumer 批量从 Broker 拉数据。
数据持久化
消息队列 CKafka 的数据持久化主要通过如下原理实现:
Topic 中 Partition 存储分布
在消息队列 CKafka 文件存储中,同一 Topic 有多个不同 Partition,每个 Partition 在物理上对应一个文件夹,用户存储该 Partition 中的消息和索引文件。例如,创建两个 Topic,Topic1 中存在5个 Partition,Topic2 中存在10个 Partition,则整个集群上会相应生成5 + 10 = 15个文件夹。Partition 中文件存储方式
Partition 物理上由多个 segment 组成,每个 segment 大小相等,顺序读写,快速删除过期 segment, 提高磁盘利用率。
水平扩展(Scale Out)
- 一个 Topic 可包含多个 Partition,分布在一个或多个 Broker 上。
- 一个消费者可订阅其中一个或者多个 Partition。
- Producer 负责将消息均衡分配到对应的 Partition。
- Partition 内消息是有序的。
Consumer Group
- 消息队列 CKafka 不删除已消费的消息。
- 任何 Consumer 必须属于一个 Group。
- 同一 Consumer Group 中的多个 Consumer 不同时消费同一个 Partition。
- 不同 Group 同时消费同一条消息,多元化(队列模式、发布订阅模式)。
多副本
多副本设计可增强系统可用性、可靠性。
Replica 均匀分布到整个集群,Replica 的算法如下:
- 将所有 Broker(假设共 n 个 Broker)和待分配的 Partition 排序。
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上。
- 将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上。
Leader Election 选举机制
消息队列 CKafka 在 ZooKeeper 中动态维护了一个 ISR(in-sync replicas),ISR 里的所有 Replica 都跟上了 Leader。只有 ISR 里的成员才有被选为 Leader 的可能。
- ISR 中 f + 1个 Replica,一个 Partition 能在保证不丢失已 commit 的消息的前提下
容忍 f 个 Replica 的失败。 - 共有 2f + 1个 Replica(包含 Leader 和 Follower),commit 之前必须保证有 f + 1个
Replica 复制完消息,为了保证正确选出新的 Leader,fail 的 Replica 不能超过 f 个。
CKafka 架构原理的更多相关文章
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- NET/ASP.NET Routing路由(深入解析路由系统架构原理)(转载)
NET/ASP.NET Routing路由(深入解析路由系统架构原理) 阅读目录: 1.开篇介绍 2.ASP.NET Routing 路由对象模型的位置 3.ASP.NET Routing 路由对象模 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Istio入门实战与架构原理——使用Docker Compose搭建Service Mesh
本文将介绍如何使用Docker Compose搭建Istio.Istio号称支持多种平台(不仅仅Kubernetes).然而,官网上非基于Kubernetes的教程仿佛不是亲儿子,写得非常随便,不仅缺 ...
- Hive的配置| 架构原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hi ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- 简单理解Hadoop架构原理
一.前奏 Hadoop是目前大数据领域最主流的一套技术体系,包含了多种技术. 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 有些朋友可能 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
随机推荐
- [.NET] - EventLog.EntryWritten Event
刚看到在MSND论坛上有人问一个EventLog.EntryWritten Event相关的问题,说是在2015触发了一个2013年的EventWritten的事件,比较好奇,然后查看了下这个类: h ...
- 李宏毅机器学习课程笔记-2.5线性回归Python实战
本文为作者学习李宏毅机器学习课程时参照样例完成homework1的记录. 任务描述(Task Description) 现在有某地空气质量的观测数据,请使用线性回归拟合数据,预测PM2.5. 数据集描 ...
- 网易云解锁无版权PC&安卓版
前言 又是一个不太忙碌的周末 好吧,其实智能车有很多东西要做,其他也有很多东西要处理,但我想咸鱼一个早上. 闲着没事去吾爱破解上翻了翻,找找音乐软件,因为Listen 1有个音源挂了,应该是咪咕的,导 ...
- 渗透工具Burp Suite浅析
Burp suite是一款Web安全领域的跨平台工具,基于Java开发.它集成了很多用于发现常见Web漏洞的模块,如Proxy,Spider,Scanner,Intruder,Repeater等.所有 ...
- 线程 - AtomicInteger
原理 AtomicInteger是如何使用非阻塞算法来实现并发控制的 性能提升 避免多线程的优先级倒置和死锁情况的发生 任然可能存在问题 ABA问题 CAS原理 调整具有竞争的并发应用程序的可伸缩性的 ...
- Plugin 插件体系
Solon 的插件也可以叫扩展组件,相当于Spring 的 starter.Solon已经提供了大量的基础插件,但对第三方的框架适配目前较少. 插件 说明 boot插件:: 说明 org.noear: ...
- flink集群模式安装配置
一.手动下载安装包 wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.6.1/flink-1.6.1-bin-hadoop27 ...
- [ABP教程]第一章 创建服务端
Web应用程序开发教程 - 第一章: 创建服务端 关于本教程 在本系列教程中, 你将构建一个名为 Acme.BookStore 的用于管理书籍及其作者列表的基于ABP的应用程序. 它是使用以下技术开发 ...
- 对数几率回归(逻辑回归)原理与Python实现
目录 一.对数几率和对数几率回归 二.Sigmoid函数 三.极大似然法 四.梯度下降法 四.Python实现 一.对数几率和对数几率回归 在对数几率回归中,我们将样本的模型输出\(y^*\)定义 ...
- unity 卡牌聚拢算法
unity 卡牌聚拢算法 前言 代码 前言 笔者在做项目时遇到了一个要聚拢手牌,像三国杀里的手牌聚拢的效果 大概效果图: 代码 public Dictionary<int, int> le ...