Mixed Precision Training —— caffe-float16
简介
最近有了突如其来的想法,如何把caffe的变得更小更快。后来翻到Nvidia开发caffe-float16,同时也看到它的论文。看完大致了解一番后,就做一下记录。
该工作的目标是,减少网络的所需的内存大小和提升网络的 inference(推理)速度。nvidia通过才用自己开发的 float16 半精度 cuda_fp16.h 数据类型,在forward和backward propagation中代替 float 32 bits的单精度数据类型。因此,在降低网络的数据的 precision 时候,导致产生了网络 accuracy 降低和 gradient 消失无法收敛的问题。当然,我在这里并不想重复的写出文中所有的点(因为其中总体的idea在量化quantization 方面是“general” 的),仅对该工作我觉得特有的点或感兴趣的点进行简述。
Mixed Precision
在caffe-float16 中的Blob重写,改为data和diff分别用不同的数据类型表示,这可以选着你所需的精确的数据类型:
//blob.hpp
protected:
Blob(Type data_type, Type diff_type)
: data_tensor_(make_shared<Tensor>(data_type)),
diff_tensor_(make_shared<Tensor>(diff_type)),
count_(0) {}
而Master-Weights(F32)-->float2half的实现就是每次this->blobs_[0]->template gpu_data<Ftype>(); 中做一次类型转换:
//conv_layer.cu
const Ftype* weight = this->blobs_[0]->template gpu_data<Ftype>();
//blob.hpp
template<typename Dtype>
const Dtype* gpu_data() const {
convert_data(tp<Dtype>());
return static_cast<const Dtype*>(data_tensor_->synced_mem()->gpu_data());
}
void convert_data(Type new_data_type) const {
data_tensor_->convert(new_data_type);
}
//tensor.cpp
void Tensor::convert(Type new_type) {
if (new_type == type_) {
return;
}
const shared_ptr<SyncedMemory>& current_mem = synced_mem();
shared_ptr<SyncedMemory>& new_mem = synced_arrays_->at(new_type);
if (!new_mem || !new_mem->is_valid()) {
const std::size_t new_cap = even(count_) * tsize(new_type);
if (!new_mem || new_mem->size() != new_cap) {
new_mem = make_shared<SyncedMemory>(new_cap);
}
const bool data_gpu = Caffe::mode() == Caffe::GPU;
if (current_mem->head() != SyncedMemory::UNINITIALIZED) {
copy_helper(data_gpu, count_,
data_gpu ? current_mem->gpu_data() : current_mem->cpu_data(),
type_,
data_gpu ? new_mem->mutable_gpu_data() : new_mem->mutable_cpu_data(),
new_type);
}
} // we just trust its current status otherwise
type_ = new_type;
new_mem->validate();
}
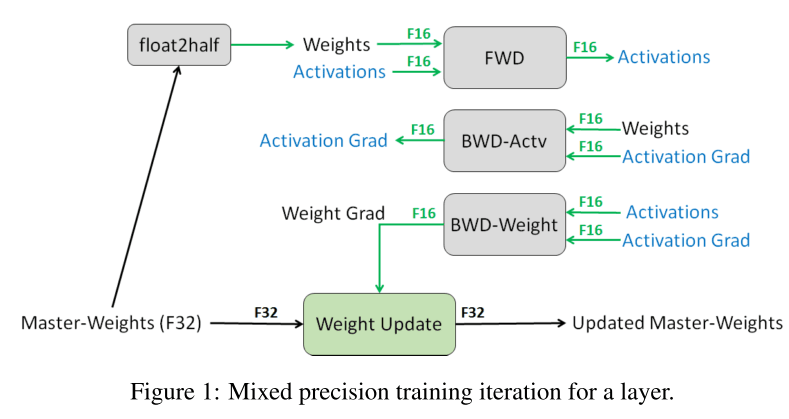
神经网络的 quantization 一般可分 activation、weight 部分,当然也存在继续对不同类型 layer 的 weghit 进行 quantization 的。而 Nvidia 则提出了 gradient 也是要 quantization 。上图是文中的整个方法的流程图,为了防止用无法拟合,采用全精度的 flaot32 来保存完整的权重信息(其他文章又叫 full precision shadow weight ),每次 forward 是都做copy 和 round/quantization 。 这是有两个原因:
- 因为 gradient x learning rate < \(2^{-24}\) ,小于float16 范围,导致梯度消失无法更新。
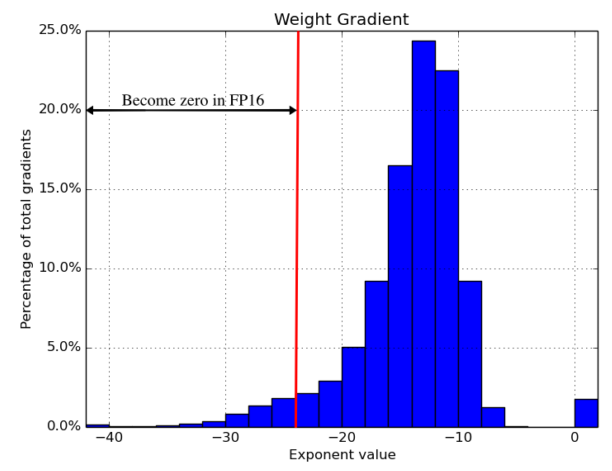
2.由于浮点型的特性,相加时会进行小数点对齐(即对其 exponent)。由于float16 表示的weight 与 float16表示的 gradient 相差2048倍(因为float16 的 mantissa 只有 10bits,有右移超过11bits ,即2048倍),则 gradient 变成0。float16 各个部分:
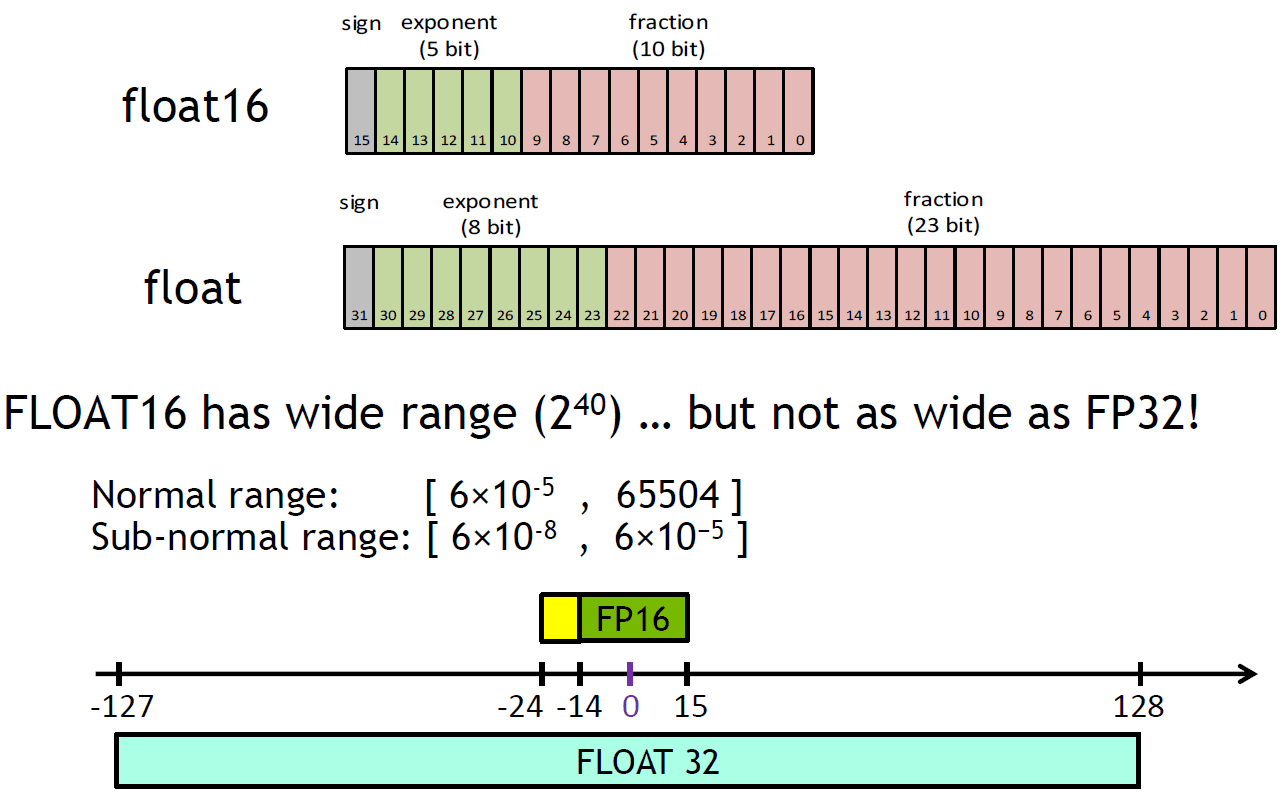
除非指数位全是0,否则就会假定隐藏的起始位是1。因此只有10位 mantissa在内存中被显示出来,而总精度是11位。据IEEE 754的说法,虽然尾数只有10位,但是尾数精度是11位的(log10(211) ≈ 3.311 十进制数).
而Weight Update,会对diff进行类型转换
//blob.hpp
// The "update" method is used for parameter blobs in a Net, which are stored
// as TBlob<float> or TBlob<double> -- hence we do not define it for
// TBlob<int> or TBlob<unsigned int>.
void Blob::Update() {
convert_diff(data_type()); // align data&diff types
shared_ptr<SyncedMemory>& data_mem = data_tensor_->mutable_synced_mem();
const shared_ptr<SyncedMemory>& diff_mem = diff_tensor_->synced_mem();
// We will perform update based on where the data is located.
switch (data_mem->head()) {
case SyncedMemory::HEAD_AT_CPU:
// perform computation on CPU
cpu_axpy(count_, data_type(), -1.F,
diff_mem->cpu_data(), data_mem->mutable_cpu_data());
break;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
gpu_axpy(count_, data_type(), -1.F,
diff_mem->gpu_data(), data_mem->mutable_gpu_data());
#else
NO_GPU;
#endif
break;
default:
LOG(FATAL) << "Syncedmem not initialized.";
}
CHECK(is_current_data_valid());
CHECK(is_current_diff_valid());
}
Lose Scaling
从上面float16 各个部分位宽可以得到,float16 可以表示的范围是\([2^{-24},2^{15}]\)(exponent表示范围是\([2^{-14},2^{15}]\),其中 mantissa是10bits)。但是 activation的 gradient的分布却在 \([2^{-60},2^{-10}]\),在float16 中有非常大的表示范围并没用,同时导致大多数的activation gradient变成0。因此,对activation gradient在forward后,backward propagation前做scaling/shift 。并且,在链式法则backward propagation 中的所有activation gradient按想用的量进行scaling。
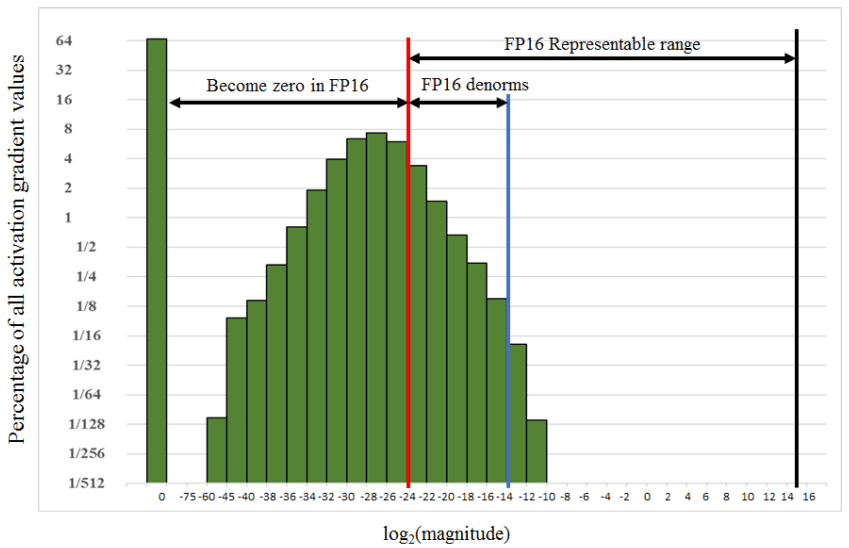
具体操作(因为activation gradient做scaling,那么也要对learning rate和weight_decay做scaling):
#caffe train_val.prototxt
#To sfift gradients dE/dX we will scale up the loss function by constant (e.g. by 1000):
layer {
type: "SoftMaxWithLoss"
loo_weight: 1000.
}
#and adjust learning rate and weights decay accordingly
base_lr: 0.00001 #(original value is 0.01, 0.01 / 1000)
weight_decay: 0.5 #(original value is 0.0005, 0.5 * 1000)
其中decay_weight公式为:
\]
而在softmax_loss_layer.cu的实现为:
template <typename Ftype, typename Btype>
void SoftmaxWithLossLayer<Ftype, Btype>::Backward_gpu(const vector<Blob*>& top,
const vector<bool>& propagate_down, const vector<Blob*>& bottom) {
...
float loss_weight = float(top[0]->cpu_diff<Btype>()[0]) /
get_normalizer(normalization_, valid_count);
if (this->parent_net() != NULL) {
loss_weight *= this->parent_net()->global_grad_scale();
}
caffe_gpu_scal<Btype>(prob_->count(), loss_weight , bottom_diff);
}
}
FP16 Master Weight Storage
在该论文之外,Nvidia还考虑避免每次foward都复制权重,用float16进行权重更新的问题。
- 最核心一点就是避免gradient \(\eta{{\partial E}\over \partial \omega_i}=\eta\Delta \omega_i\)消失。
那么Nvidia提出对momentum SGD 进行改进
- Compute momentum \(H\) : \(H(t+1)=m*H(t)-\lambda \Delta W(t)\)
- Update wights with \(H\): \(W(t+1)=W(t)+H(t+1)\)
假设\(\lambda\)为常数,把式①展开:
\]
\]
因此新的公式:
- Compute momentum \(H\) : \(H(t+1)=m*H(t)-\color{#F00}{\cancel{\lambda}}\Delta W(t)\)
- Update wights with \(H\): \(W(t+1)=W(t)+\color{#F00}{\lambda} H(t+1)\)
这样可以避免\(H\)在\(\lambda \Delta W(t)\)消失时,momentum不断的消失。因为新的公式避免了\(\Delta W(t)\)的消失,而且momentum会不断更新。
ps:这里Nvidia解释是 Moment works as average of gradients.
Nvidia的总结
懒癌犯了- -!!

Mixed Precision Training —— caffe-float16的更多相关文章
- [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架
[源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 目录 [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 0x00 摘要 0x01 架构图 ...
- [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构
[源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 目录 [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 0x00 摘要 0x01 ...
- 使用 PyTorch Lightning 将深度学习管道速度提高 10 倍
前言 本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,主要包括有为什么优化深度学习管道很重要.使用 PyTorch Lightning 加快实验周期的六种 ...
- Bag of Tricks for Image Classification with Convolutional Neural Networks笔记
以下内容摘自<Bag of Tricks for Image Classification with Convolutional Neural Networks>. 1 高效训练 1.1 ...
- Pytorch原生AMP支持使用方法(1.6版本)
AMP:Automatic mixed precision,自动混合精度,可以在神经网络推理过程中,针对不同的层,采用不同的数据精度进行计算,从而实现节省显存和加快速度的目的. 在Pytorch 1. ...
- [源码解析] 深度学习分布式训练框架 Horovod (1) --- 基础知识
[源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 目录 [源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 0x00 摘要 0x01 分布式并 ...
- 用NVIDIA A100 GPUs提高计算机视觉
用NVIDIA A100 GPUs提高计算机视觉 Improving Computer Vision with NVIDIA A100 GPUs 在2020年英伟达GPU技术会议的主题演讲中,英伟达创 ...
- 基于OpenSeq2Seq的NLP与语音识别混合精度训练
基于OpenSeq2Seq的NLP与语音识别混合精度训练 Mixed Precision Training for NLP and Speech Recognition with OpenSeq2Se ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
随机推荐
- 数据可视化之PowerQuery篇(十五)如何使用Power BI计算新客户数量?
https://zhuanlan.zhihu.com/p/65119988 每个企业的经营活动都是围绕着客户而开展的,在服务好老客户的同时,不断开拓新客户是每个企业的经营目标之一. 开拓新客户必然要付 ...
- [Android] keytools生成jsk文件以及获取sha1码
生成jks文件 进入要生的jks文件的路径,打开windows的命令提示符(CMD) keytool -genkey -alias dct -keyalg RSA -keysize 1024 -key ...
- Xamarin.Android调用百度地图
下载百度地图API Android SDK 在Visual Studio中创建绑定库(Android)项目 将jar文件添加到Jars文件夹中 生成该项目,如果遇到变量名称之类的问题,可在Transf ...
- 数据规整:连接、联合与重塑知识图谱-《利用Python进行数据分析》
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载或者右击保存图片. 其他章 ...
- java 使用正则去重
//去重复 public static void test1() { String str = "aaactttsssfvvvvds"; String regex = " ...
- vue : 对 vue-class-component 的个人理解
vue-class-component 是 vue 的官方库,作用是用类的方式编写组件. 这种编写方式可以让.vue文件的js域结构更扁平,并使vue组件可以使用继承.混入等高级特性. 简单的示例: ...
- 关于 iframe 的小问题若干
我们知道,iframe在传统的MVC项目里是个很常用的东西. 但这玩意用起来有时会有点烦人. 比如说:我有个一个页面套了一个iframe,iframe里面的页面通过a标签来切换.怎么做? <li ...
- 跳过Google开机设置/验证/向导
Google 的开机设置向导,亦或称作开机验证,对于刷机党来说最熟悉不过了.一般情况下,刷类原生或是原生系统,再刷 Gapps,开机就需要进行一些 Google 验证.这些验证,与国内的手机厂商所设置 ...
- 给咱的WP站点搬家
前言 WordPress 作为全球最流行的博客系统,使用简单,功能丰富,用它来建站的用户非常多.对于站长们来说,网站搬家也是少不了的,有时我们需要更换主机空间,把网站从一个服务器迁移到另一个服务器上, ...
- consul++ansible+shell批量下发注册node_exporter
--日期:2020年7月21日 --作者:飞翔的小胖猪 文档功能说明: 文档通过ansible+shell+consul的方式实现批量下发安装Linux操作系统监控的node_exporter软件, ...