设置beeline连接hive的数据展示格式
问题描述:beeline -u 方式导出数据,结果文件中含有“|”(竖杠)。
执行的sql为:beeline -u jdbc:hive2://hadoop1:10000/default -e 'select * from tablename' > /home/tmp/result.nb
执行结果如下:

在Beeline中,结果可以被展示为多种格式,格式可以在outputformat参数中设置。下面是支持的输出各式:
- table
- vertical
- xmlattr
- xmlelements
- separated-value formats (csv, tsv, csv2, tsv2, dsv)
其中table、vertical、xmlattr和xmlelements是按照特有的形式展示结果,比如vertical以key-value格式展示,xmlelements以xml格式展示。详情见:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
separated-value formats展示形式是将一行值按照不同分割符分开,主要包括五种分割输出格式:csv, tsv, csv2, tsv2, dsv,目前csv和tsv已经被csv2和tsv2替代了。dsv,csv2和tsv2是从 Hive 0.14 开始引入的SV输出格式,csv2使用的是逗号,tsv2使用的是tab空格,dsv是可配置的。对于dsv格式,分隔符可以通过用参数 delimiterForDSV 进行设置,默认是 '|'。
对于问题描述可知beeline输出结果中字段之间使用“|”分割的,从前面分析可知, csv2和tsv2格式字段值分割符不可能是“|”,只有输出为dsv格式,分割符可以设置,且默认分割符是“|”。可是在执行beeline时并未设置outputformat和delimiterForDSV 参数的值,说明使用的是Beeline默认的输出格式,从outputformat说明中得知Beeline默认的输出各式为table模式,所以接下来就需要弄清楚table模式下字段分隔符是否为“|”。
首先在BeeLine类中找到展示结果相关的代码,如下图所示:
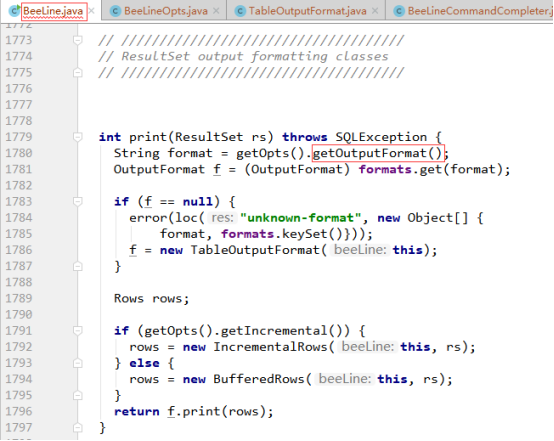
从上图可知,beeline使用的输出格式是通过getOutputFormat()方法获取的,那就进入该方法看看,如下图所示:
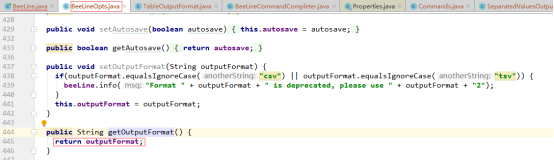
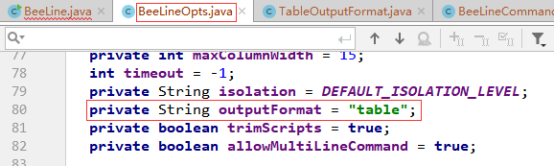
可以看出getOutputFormat()方法直接将outputFormat值返回,接下来就需要看看outputFormat的值从哪来的,通过搜索得知除了outputFormat的默认值外,只有上图中setOutputFormat(String outputFormat)会给outputFormat设置值,可是setOutputFormat(String outputFormat)只有在beeline执行语句中设置outputformat才会被调用,而事实并未在beeline中设置outputformat,所以getOutputFormat()获取的是outputformat默认值,outputformat的默认值为"table",相关代码如下:
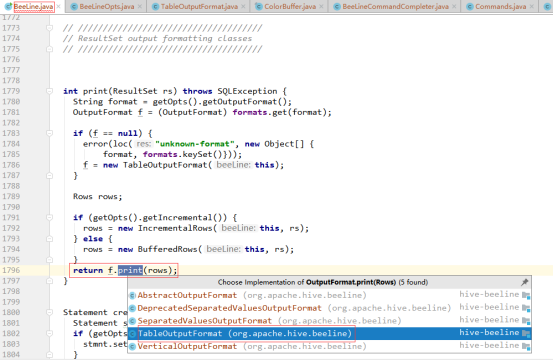
TableOutputFormat类的print()方法实现逻辑如下:
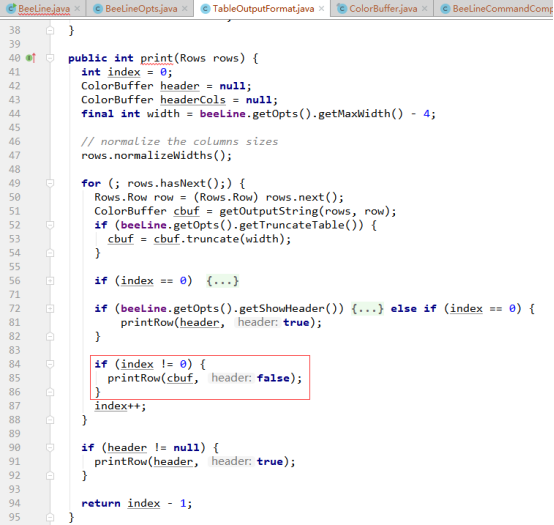
从上图可知,在print()方法中主要是设置表格中表头、表体、表中值的展示格式,这里只关注表中字段值的分割符,因此继续进入图中第85行代码看看对值的格式处理,代码如下:
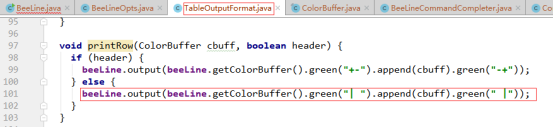
此处要看的是table默认下对值是怎么分割的,故header的值为false,所以会走该段代码的else逻辑,显然从图中红框中的代码可知值之间使用“|”分割的。
经过以上分析可知,如果没有在beeline执行语句中设置outputformat参数,默认展示格式会使用table模式,而table模式下字段值之间的分割符为“|”,因此我们看到beeline展示的结果是以“|”分割的。如果不想使用“|”作为分割符,可以通过以下方式来设置:
方式一:如果值之间用逗号分割,可以在beeline执行语句中加入--outputformat=csv2;如果值之间用tab分割,可以在beeline执行语句中加入--outputformat=tsv2。
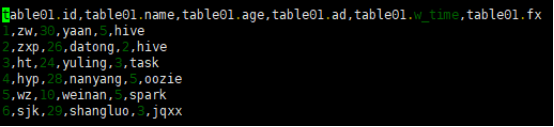
(1)将beeline的输出格式设置为csv2,即以逗号作为值之间的分割符。
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=csv2 -e 'select * from tablename' > /home/tmp/result.nb
展示结果如下:
(2)将beeline的输出格式设置为tsv2,即以tab作为值之间的分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=tsv2 -e 'select * from tablename' > /home/tmp/result.nb
展示结果如下:

方式二:如果方式的分割符不满足需求,想通过其他分割符来分割beeline的执行结果值,可以在beeline执行语句中加入--outputformat=dsv2和--delimiterForDSV=DELIMITER。
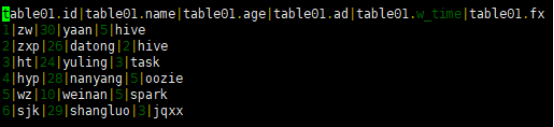
(1)将beeline的输出格式设置为dsv2,使用dsv2默认的分割符,即‘|’。
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:
(2)将beeline的输出格式设置为dsv2,并以tab作为值之间得分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv --delimiterForDSV=$'\t' -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:

(3)将beeline的输出格式设置为dsv2,并以#作为值之间得分割符
SQL示例如下:
beeline -u jdbc:hive2://hadoop1:10000/default --outputformat=dsv --delimiterForDSV=# -e 'select * from tablename' > /home/tmp/result.nb
结果展示如下:

备注:如果使用dsv2输出格式,值之间的分割符使用默认值,在beeline执行语句中只需要加入--outputformat=dsv就可以;如果使用dsv2输出格式,想通过自定义分割符来对值进行分割,不仅要在beeline执行语句中只需要加入--outputformat=dsv,还需要加入--delimiterForDSV=DELIMITER,实际使用时DELIMITER的值可替换为自定义的分割符。
设置beeline连接hive的数据展示格式的更多相关文章
- beeline连接hive server遭遇MapRedTask (state=08S01,code=1)错误
采用beeline连接hive server是遭遇到如下错误: 5: jdbc:hive2://bluejoe0/default> select * from hive_triples wher ...
- 使用 beeline 连接 hive 数据库报错处理
一.beeline连接hive报错 1. User: root is not allowed to impersonate root (state=08S01,code=0) 在初次搭建完hadoop ...
- kettle连接Hive中数据导入导出(6)
1.hive往外写数据 http://wiki.pentaho.com/display/BAD/Extracting+Data+from+Hive+to+Load+an+RDBMS 连接hive
- beeline 连接hive
HiveServer2是一个能使客户端针对hive执行查询的一种服务,与HiverServer1比较,它能够支持多个客户端的并发请求和授权的:HiveCLI 和 hive –e的方式比较单一,HS2允 ...
- 【Oracle】将表名与字段名连接成一行数据展示,字段名使用顿号的分隔
select '<'||a.comments||'>:'||replace(wmsys.wm_concat(b.comments),',','.')||'.' as pjzf from u ...
- beeline连接hive
beeline -u jdbc:hive2://192.168.1.77:10000 zeppelin default jdbc: jdbc:hive2://nn01.ooccpp.com:2181/ ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- java使用JDBC连接hive(使用beeline与hiveserver2)
首先虚拟机上已经安装好hive. 下面是连接hive需要的操作. 一.配置. 1.查找虚拟机的ip 输入 ifconfig 2.配置文件 (1)配置hadoop目录下的core-site.xml和hd ...
- 由“Beeline连接HiveServer2后如何使用指定的队列(Yarn)运行Hive SQL语句”引发的一系列思考
背景 我们使用的HiveServer2的版本为0.13.1-cdh5.3.2,目前的任务使用Hive SQL构建,分为两种类型:手动任务(临时分析需求).调度任务(常规分析需求),两者均通过我们的 ...
随机推荐
- redis字典
字典作为一种保存键值对的数据结构,在redis中使用十分广泛,redis作为数据库本身底层就是通过字典实现的,对redis的增删改查实际上也是构建在字典之上. 一.字典的结构
- web 安全 & web 攻防: XSS(跨站脚本攻击)和 CSRF(跨站请求伪造)
web 安全 & web 攻防: XSS(跨站脚本攻击)和 CSRF(跨站请求伪造) XSS(跨站脚本攻击)和CSRF(跨站请求伪造) Cross-site Scripting (XSS) h ...
- CSS style color all in one
CSS style color all in one https://developer.mozilla.org/en-US/docs/Web/CSS/color_value /* Hexadecim ...
- 二叉搜索树 & 二叉树 & 遍历方法
二叉搜索树 & 二叉树 & 遍历方法 二叉搜索树 BST / binary search tree https://en.wikipedia.org/wiki/Binary_searc ...
- javascript nested object merge
javascript nested object merge deep copy Object reference type function namespace(oNamespace, sPacka ...
- Node.js Learning Paths
Node.js Learning Paths Node.js in Action Node.js Expert situations / scenario Restful API OAuth 2.0 ...
- Vue SSR in Action
Vue SSR in Action https://ssr.vuejs.org/ https://ssr.vuejs.org/api/ https://ssr.vuejs.org/guide/data ...
- 口罩 & 防毒面具 N95 & P100
口罩 & 防毒面具 N95 & P100 N95 口罩 < 防毒面具 P100 https://www.techritual.com/2020/01/30/210599/
- mui上拉刷新
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- spring boot插件开发实战和原理
本文转载自spring boot插件开发实战和原理 实战:编写spring boot插件 为什么要编写boot插件 因为我们在开发的时候需要提供一些共同的功能,所以我们编写个共同的jar包.开发人员在 ...