Python:出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 0: invalid continuation byte问题
我在导入一个csv文件的时候出现了一个问题

报错的内容是这样的:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 0: invalid continuation byte
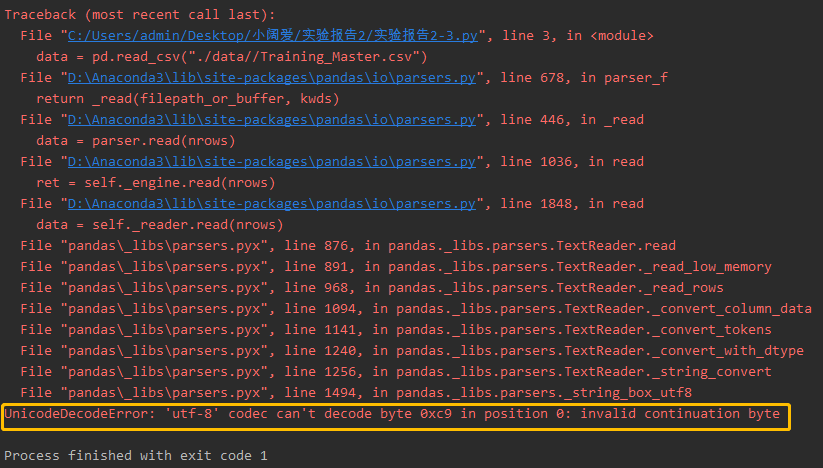
内容显示读取的时候发现了我导入的文件中存在utf-8不可编译的内容,所以我需要使用一种encoding来使文件能够被正常读取。
我向代码中增加了encoding='utf-8'。。。。有点蠢,都说了utf-8不行哈哈哈哈哈

所以结果就是加进去也不行。。。
正确的方案是在后面增加了
encoding='unicode_escape'

代码成功运行!!!!
更新一下:其实可以用notepad直接转换成utf-8
Python:出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 0: invalid continuation byte问题的更多相关文章
- 第一篇:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 0: invalid continuation byte
需求:python如何实现普通用户登录服务器后切换到root用户再执行命令 解决参考: 代码: def verification_ssh(host,username,password,port,roo ...
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 0: invalid continuation byte
需求:python如何实现普通用户登录服务器后切换到root用户再执行命令 解决参考: 代码: def verification_ssh(host,username,password,port,roo ...
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte
用pandas打开csv文件可能会出现这种情况,原因可能是excel自己新建一个*.csv文件时候容易出错.进入文件另存为,然后选择csv文件即可.
- 解决linux 终端UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 0: invalid continuation byte
vi /etc/locale.conf 修改LANG="zh_CN.gbk" 最后执行source /etc/locale.conf 即可永久生效,下次登录,中文就不会乱码了.
- 用python3读csv文件出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
1.python3读取csv文件时报如下图所示的错误 2.分析原因:读取的csv文件不是 UTF8 编码的,而IDE工具默认采用 UTF8 解码.解决方法是修改源文件的解码方式. 3.使用nodepa ...
- windows系统下python setup.py install ---出现cl问题,cpp_extension.py:237: UserWarning: Error checking compiler version for cl: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
将cpp_extension.py文件中的 原始的是 compiler_info.decode() try: if sys.platform.startswith('linux'): minimu ...
- 【安装Python环境】之安装Selenium2时报UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 12: invalid continuation byte问题
问题描述: windows8.1系统,Python3环境安装Selenium2时报错,错误如下: ..... ..... File "F:\软件\python3.6.1\lib\site-p ...
- UnicodeDecodeError: 'utf8' codec can't decode byte 0xce in position 47: invalid continuation byte
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 22: invalid continuation byte
在使用python读取文本文件,一般会这样写: # -*- coding:utf-8 -*- f = open("train.txt", "r", encodi ...
随机推荐
- Nmap工具介绍
使用方法 实例: nmap -v scanme.nmap.org 这个选项扫描主机scanme.nmap.org中 所有的保留TCP端口.选项-v启用细节模式. nmap -sS -O scanme. ...
- Debezium系列随笔
0.Debezium简介 1.Run Debezium for Mysql in docker step by step 2.Run Debezium for SQLServer in docker ...
- 通过IP得到IP所在地省市
/// <summary> /// 通过IP得到IP所在地省市(Porschev) /// </summary> /// <param name="ip&quo ...
- HTML5 & CSS初学者教程(详细、通俗易懂)
前端语言基础:HTML5 & CSS (一) HTML5:超文本标记语言 (1) 基本概念 是由一系列成对出现的元素标签(标记)嵌套组合而成 ( XML也是标签构成的 ) 这些标签以的形式出现 ...
- MySQL函数和过程(三)
--加密32位字符select md5('123456') --获取字符串的长度(一个中文三个长度)select LENGTH('呵呵') --获取字符串字符个数select CHAR_LENGTH( ...
- Javaweb入门 JDBC第一天
JDBC的定义和作用 DBC(Java DataBase Connectivity) Java数据库连接, 其实就是利用Java语言/程序连接并访问数据库的一门技术. 之前我们可以通过cmd或者nav ...
- GCD欧几里得的拓展算法
欧几里得算法的拓展主要是用于求解 : 已知整数 a, b,然后我们进行 ax + by == gcd(a , b) 的问题求解 那么如何进行求解呢?和欧几里得算法一样, 我们需要进行递归的方式进 ...
- git太慢用码云
克隆完之后,我们要对这个仓库进行下修改,将仓库地址修改为git的那个 git remote set-url origin xxxx.git 经过以上操作,这个仓库就和从github上克隆下来的一模一样
- Python二、十、八进制相互转换
进制转换:先介绍用传统数学方法,再介绍用python内置方法 二进制转十进制: 1101 转为十进制 1*2^(4-1)+1*2^(3-1)+0*2^(2-1)+1*2^(1-1) 即各个位拆开,乘以 ...
- selenium登录慕课网
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.s ...