异常值检验实战1--风控贷款年龄变量(附python代码)
python风控评分卡建模和风控常识(博客主亲自录制视频教程)

结论只属于教学数据,每个场景不一样,结论不一样,仅供参考
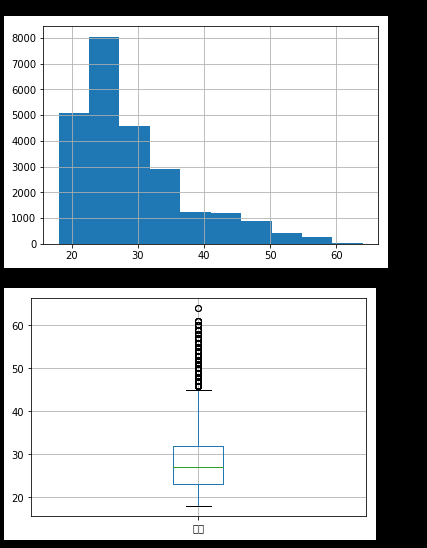
年龄45岁以上属于离群值,有欺诈嫌疑,建议不考虑放贷,可根据其他情况综合判定
1538/28720=0.535
年龄59岁以上属于极端离群值,非常可能是欺诈,不应该考虑放贷
50/28720=0.0017409470752089136
好坏客户比例无法区分:
年龄45岁以上好客户概率
772/1538=0.5019505851755527
年龄45岁以上坏客户概率
766/1538=0.4980494148244473
excel数据
正太分布_箱形图_脱群值挖掘.py
# -*- coding: utf-8 -*-
"""
正太分布_箱形图_脱群值挖掘.py
Created on Fri Mar 9 10:18:04 2018
@author: Toby QQ:231469242
Python视频集合
https://pythoner.taobao.com/ """
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import normality_check
from scipy.stats import mode
#读取文件
FileName="年龄.xlsx"
#读取excel
df=pd.read_excel(FileName)
年龄=df['年龄'] 描述性统计=年龄.describe()
样本量=描述性统计[0]
最小值=年龄.min()
最大值=年龄.max()
平均数=年龄.mean()
中位数=年龄.median()
众数=mode(年龄).mode[0]
四分之一位数=描述性统计[4]
四分之三位数=描述性统计[6]
标准差=描述性统计[2]
IQR=四分之三位数-四分之一位数
异常值上线=四分之三位数+1.5*IQR
异常值下线=四分之一位数-1.5*IQR
upper_outer_fence=四分之三位数+3*IQR
lower_outer_fence=四分之一位数-3*IQR
if lower_outer_fence<0:
lower_outer_fence=0
#避免两端极值和商户活动降价影响
参考区间=(四分之一位数,四分之三位数)
if 样本量>3:
正态性=normality_check.check_normality(年龄)
else:
正态性=False
参考价格=中位数
market_price_range=(异常值下线,异常值上线) #绘制正太分布图
年龄.hist()
df1=pd.DataFrame(年龄)
fig,ax=plt.subplots()
a=df1.boxplot(ax=ax)
plt.savefig('pig.png') def 异常值判断(数字):
if 数字>异常值上线 or 数字<异常值下线:
print("%f 是异常值"%数字)
return True
else:
print("%f 不是异常值"%数字)
return False #箱型图市场价格取值范围
def Boxer_Market_price_range(异常值下线,异常值上线):
if 异常值下线<最小值:
异常值下线=最小值
return (异常值下线,异常值上线) #正态分布市场价格取值范围
market_price_range=Boxer_Market_price_range(异常值下线,异常值上线)
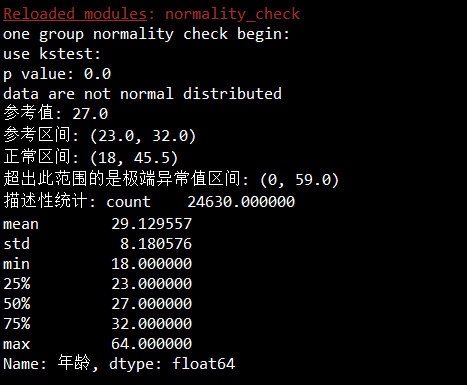
extreme_outlier=(lower_outer_fence,upper_outer_fence) print("参考值:",参考价格)
print("参考区间:",参考区间)
print("正常区间:",market_price_range)
print("超出此范围的是极端异常值区间:",extreme_outlier)
print("描述性统计:",描述性统计)
#测试1.5万是否属于正常市场价格
#异常值判断(15000) #名称列表
list_名称=["样本量","最小值","最大值","平均数","中位数","众数","四分之一位数","四分之三位数","IQR","异常值上线","异常值下线","标准差","正态性","参考价格","参考区间","市场价格正常区间","(区间外)极端异常值"]
list_value=[样本量,最小值,最大值,平均数,中位数,众数,四分之一位数,四分之三位数,IQR,异常值上线,异常值下线,标准差,正态性,参考价格,参考区间,market_price_range,extreme_outlier]
df_save=pd.DataFrame(data=[list_value],index=[0],columns=list_名称)
df_save.to_excel("统计结果.xlsx")
normality_check.py
# -*- coding: utf-8 -*-
'''
normality_check.py
@author: Toby QQ:231469242
Python视频集合
https://pythoner.taobao.com/
all right reversed,no commercial use
正态性检验脚本 ''' import scipy
from scipy.stats import f
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# additional packages
from statsmodels.stats.diagnostic import lillifors #对一列数据进行正态分布测试
def check_normality(testData):
print("one group normality check begin:")
#20<样本数<50用normal test算法检验正态分布性
if 20<len(testData) <50:
p_value= stats.normaltest(testData)[1]
if p_value<0.05:
print("use normaltest")
print("p value:",p_value)
print ("data are not normal distributed")
return False
else:
print("use normaltest")
print("p value:",p_value)
print ("data are normal distributed")
return True #样本数小于50用Shapiro-Wilk算法检验正态分布性
if len(testData) <50:
p_value= stats.shapiro(testData)[1]
if p_value<0.05:
print ("use shapiro:")
print("p value:",p_value)
print ("data are not normal distributed")
return False
else:
print ("use shapiro:")
print("p value:",p_value)
print ("data are normal distributed")
return True if 300>=len(testData) >=50:
p_value= lillifors(testData)[1] if p_value<0.05:
print ("use lillifors:")
print("p value:",p_value)
print ("data are not normal distributed")
return False
else:
print ("use lillifors:")
print("p value:",p_value)
print ("data are normal distributed")
return True if len(testData) >300:
p_value= stats.kstest(testData,'norm')[1]
if p_value<0.05:
print ("use kstest:")
print("p value:",p_value)
print ("data are not normal distributed")
return False
else:
print ("use kstest:")
print("p value:",p_value)
print ("data are normal distributed")
return True
#测试结束
print("-"*100) #对所有样本组进行正态性检验
def NormalTest(list_groups):
for group in list_groups:
#正态性检验
status=check_normality(group)
if status==False :
return False '''
group1=[5,2,4,2.5,3,3.5,2.5,3]
group2=[1.5,2,1.5,2.5,3.3,2.3,4.2,2.5]
group3=[96,90,95,92,95,94,94,94]
list_groups=[group1,group2,group3]
list_total=group1+group2+group3
#对所有样本组进行正态性检验
NormalTest(list_groups)
'''
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源

异常值检验实战1--风控贷款年龄变量(附python代码)的更多相关文章
- outlier异常值检验算法之_箱型图(附python代码)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- day02编程语言,Python语言介绍,Python解释器安装,环境变量,Python代码执行,pip,应用程序使用文件的三步骤,变量,变量的三大组成,比较,pycharm
复习 重点: 1.进制转换:二进制 与十六进制 2.内存分布:栈区 与堆区 # 二进制1111转换十六进制 => 8 4 2 1 => f 10101100111011 => 2a7 ...
- python异常值检验实战2_医美手术价格
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- 异常值检验实战3_NBA球员表现稳定性分析
机器学习_深度学习_入门经典(博主永久免费教学视频系列) https://study.163.com/course/courseMain.htm?courseId=1006390023&sh ...
- R语言︱异常值检验、离群点分析、异常值处理
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:异常值处理一般分为以下几个步骤:异常 ...
- R语言︱处理缺失数据&&异常值检验、离群点分析、异常值处理
在数据挖掘的过程中,数据预处理占到了整个过程的60% 脏数据:指一般不符合要求,以及不能直接进行相应分析的数据 脏数据包括:缺失值.异常值.不一致的值.重复数据及含有特殊符号(如#.¥.*)的数据 数 ...
- 科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码)
科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码) 春有百花秋有月,夏有凉风冬有雪: 若无闲事挂心头,便是人间好时节. --宋.无门慧开 不废话了,以下训练模型数据 ...
- Java代码执行顺序(静态变量,非静态变量,静态代码块,代码块,构造函数)加载顺序
//据说这是一道阿里巴巴面试题,先以这道题为例分析下 public class Text { public static int k = 0; public static Text t1 = new ...
- @有两个含义:1,在参数里,以表明该变量为伪参数 ,在本例中下文里将用@name变量代入当前代码中2,在字串中,@的意思就是后面的字串以它原本的含义显示,如果不
@有两个含义:1,在参数里,以表明该变量为伪参数 ,在本例中下文里将用@name变量代入当前代码中 2,在字串中,@的意思就是后面的字串以它原本的含义显示,如果不加@那么需要用一些转义符\来显示一些特 ...
随机推荐
- 用实例的方式去理解storm的并发度
什么是storm的并发度 一个topology(拓扑)在storm集群上最总是以executor和task的形式运行在suppervisor管理的worker节点上.而worker进程都是运行在jvm ...
- c#读取文件路径并保存在textBox2中
private void button1_Click_1(object sender, EventArgs e) { OpenFileDialog openFileDialog1 = new Open ...
- Caffe---自带工具进行网络结构(xxx.prototxt)可视化
Caffe---自带绘图工具(draw_net.py)绘制网络结构图(xxx.prototxt) 目录: 一,安装依赖库. 二,draw_net.py使用说明. 正文: 一,安装依赖库. 在绘制之前, ...
- java中静态代码块,非静态代码块,构造函数
关于静态代码块 静态代码块的写法: static { System.out.println("我是静态代码块"); } 静态代码块的特点: 1.执行优先级高于非静态的初始化块,它会 ...
- P1582 倒水 题解
来水一发水题.. 题目链接. 正解开始: 首先,我们根据题意,可以得知这是一个有关二进制的题目: 具体什么关系,怎么做,我们来具体分析: 对于每个n,我们尝试将其二进制分解,也就是100101之类的形 ...
- 关于微信小程序的本地存储
微信小程序中会使用wx.setStorage(wx.setStorageSync)来存储数据,问题是:即使小程序被销毁了,本地缓存的数据仍然存在.会造成: 所以要及时清理掉本地缓存的数据.解决思路: ...
- VMware ESXi 和 VMware Server 有区别
VMware ESXi 和 VMware Server 有区别: VMware ESXi 是一个企业级虚拟机管理程序,提供接近本机性能的祼机体系结构.各种旨在提高整合率的功能(例如取消内存复制),以及 ...
- javascript 常用的一些原生方法
一丶javascript------ reduce() reduce()方法: arr.reduce(function(prev,cur,index,arr){ ... }, init); 参数解释: ...
- 粗暴,干就完了----徐晓冬似的C语言自学笔记----前言
10对年前就觉得C/C++语言很酷,第一印象就是90年代末,个人电脑在中华大地开始普及的岁月中,层出不穷的病毒,对了,全是C/C++写的:除了危及人民群众信息安全以外,C系列语言用途甚广,可以发明其他 ...
- bzoj1711[USACO07OPEN]吃饭Dining
题意 有F种食物和D种饮料,每种食物或饮料只能供一头牛享用,且每头牛只享用一种食物和一种饮料.现在有n头牛,每头牛都有自己喜欢的食物种类列表和饮料种类列表,问最多能使几头牛同时享用到自己喜欢的食物和饮 ...