【集成模型】Stacking
0 - 思路
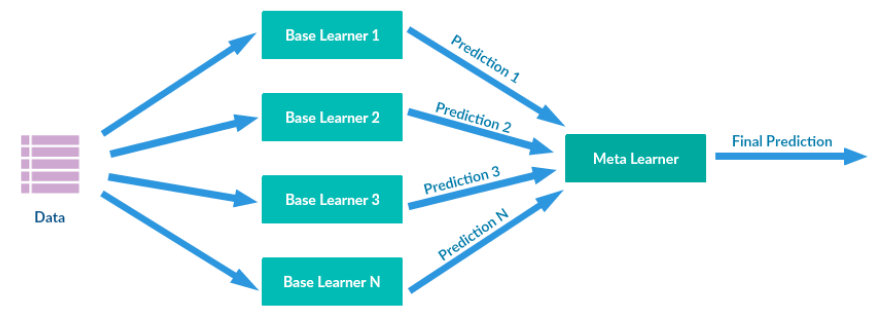
Stacking是许多集成方法的综合。其主要思路如下图所示,通过训练数据训练多个base learners(the first-level learners),这些learners的输出作为下一阶段meta-learners(the second-level learners)的输入,最终预测由meta-learners预测结果得到。
1 - 算法
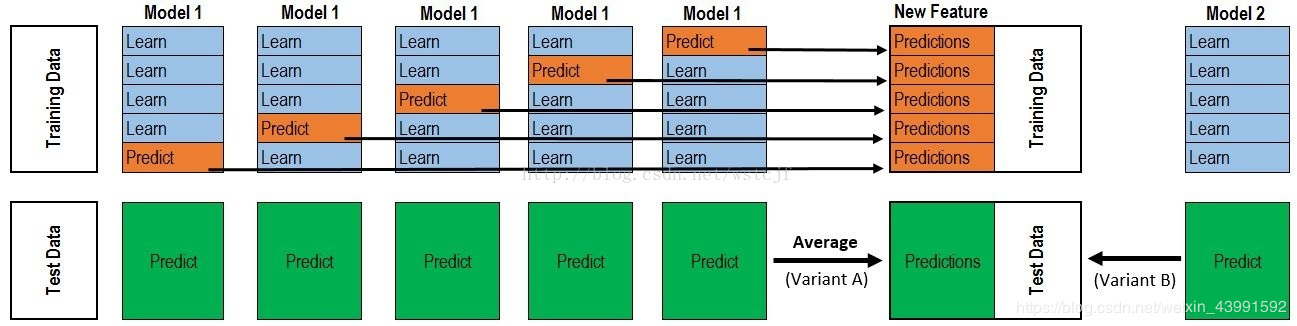
具体地算法如下图所示(图片引自博客)。在第一阶段,采用$K$折交叉验证,首先将训练数据$X_{n\times m}$和对应标签$y_{n}$分成$K$份,训练$K$个base-learners,对于第$i$($i=1,\cdots,K$)个base-learner,将第$i$份数据作为验证集,其余$(K-1)$份数据作为训练集进行训练。而后,将第$i$个base-learners对于各自验证集的预测结果$y_{n_i}^{(i)}$(如图中"Predict"橘红色所示)组合起来,即得到和训练数据规模一样的预测结果$y_{n}^{stage1}$(如图中"Predictions"橘红色所示)。将这个第一阶段的预测结果$y_{n}^{stage1}$以及对应的标签$y_{n}$作为第二阶段的meta-learners的训练数据进行训练即可。
在测试过程中,假设对于测试数据$X_{n\times m}^{test}$,经过$K$个base-learners进行预测得到第一阶段预测结果$y_{n\times K}^{stage1}$,而后可以通过硬投票或者软投票或者其他处理方法得到第一阶段的综合预测结果$y_{n}^{stage1}$,再通过meta-learners预测最终的结果$y_{n}^{stage2}$。
注意到,Stacking可以无限叠加下去,也就是stage可以从2开始一直叠加,但实际运用中,一般选取stage为2或者3,因为太多stage对于精度的提高微乎其微甚至没有而计算量却需要大量增加。
2 - 参考资料
https://blog.csdn.net/weixin_43991592/article/details/89962511
【集成模型】Stacking的更多相关文章
- Python机器学习(基础篇---监督学习(集成模型))
集成模型 集成分类模型是综合考量多个分类器的预测结果,从而做出决策. 综合考量的方式大体分为两种: 1.利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的 ...
- DeepMind提出空间语言集成模型SLIM,有效编码自然语言的空间关系
前不久,DeepMind 提出生成查询网络 GQN,具备从 2D 画面到 3D 空间的转换能力.近日.DeepMind 基于 GQN 提出一种新模型.可以捕捉空间关系的语义(如 behind.left ...
- 『Kaggle』分类任务_决策树&集成模型&DataFrame向量化操作
决策树这节中涉及到了很多pandas中的新的函数用法等,所以我单拿出来详细的理解一下这些pandas处理过程,进一步理解pandas背后的数据处理的手段原理. 决策树程序 数据载入 pd.read_c ...
- 【集成模型】Bootstrap Aggregating(Bagging)
0 - 思想 如下图所示,Bagging(Bootstrap Aggregating)的基本思想是,从训练数据集中有返回的抽象m次形成m个子数据集(bootstrapping),对于每一个子数据集训练 ...
- Kaggle机器学习之模型集成(stacking)
Stacking是用新的模型(次学习器)去学习怎么组合那些基学习器,它的思想源自于Stacked Generalization这篇论文.如果把Bagging看作是多个基分类器的线性组合,那么Stack ...
- sklearn--决策树和基于决策树的集成模型
一.决策树 决策树一般以选择属性的方式不同分为id3(信息增益),c4.5(信息增益率),CART(基尼系数),只能进行线性的分割,是一种贪婪的算法,其中sklearn中的决策树分为回归树和分类树两种 ...
- 监督学习集成模型——AdaBoost
一.集成学习与Boosting 集成学习是指将多个弱学习器组合成一个强学习器,这个强学习器能取所有弱学习器之所长,达到相对的最佳性能的一种学习范式. 集成学习主要包括Boosting和Bagging两 ...
- DAG 模型 stacking boxes 动态规划
题目:UVA 103 stacking boxes 题目大意: 给你两个数,一个是盒子的个数,一个是每一个盒子的维数.将一个个盒子互相装起来,让你求最多可以装多少个,要求字典序最小. 解析:这个就是盒 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
随机推荐
- nginx的应用【虚拟主机】
Nginx主要应用: 静态web服务器 负载均衡 静态代理虚拟主机 虚拟主机 :虚拟主机,就是把一台物理服务器划分成多个“虚拟”的服务器,这样我们的一台物理服务器就可以当做多个服务器来使用,从而可以配 ...
- SLAM、三维重建,语义相关数据集大全
作者朱尊杰,公众号:计算机视觉life,编辑成员 一 主要针对自动驾驶: 1.KITTI数据集: http://www.cvlibs.net/datasets/kitti/index.php(RGB+ ...
- HDU 6187 Destroy Walls (思维,最大生成树)
HDU 6187 Destroy Walls (思维,最大生成树) Destroy Walls *Time Limit: 8000/4000 MS (Java/Others) Memory Limit ...
- Springboot简单集成ActiveMQ
Springboot简单集成ActiveMQ 消息发送者的实现 pom.xml添加依赖 <dependency> <groupId>org.springframework.bo ...
- Mac系统上,Firefox和Selenium不兼容的情况
解决办法,检查环境: Python 2.7.10 Firefox 46版本 Selenium 2.53.6 注意:将Firefox自动更新关闭,否则可能会出现自动升级以后无法执行Selenium用例的 ...
- jquery检测屏幕宽度并跳转页面
jquery检测屏幕宽度并刷新页面 var owidth = ($(window).width()); //浏览器当前窗口可视区域宽度 if(owidth<640){//小于640跳转一个网址, ...
- Coins in a Line II
There are n coins with different value in a line. Two players take turns to take one or two coins fr ...
- SQL数据库调优
1.使用With As做数据库递归,调优树形表结构 例如:设计表结构简化如:ID.ParentID.Name:这里的ParentID就是这个表本身的某个ID WITH cte AS ( UNION A ...
- MyBatis中jdbcType=INTEGER、VARCHAR作用
Mapper.xml中 pid = #{pid,jdbcType=INTEGER} pid = #{pid} 都可以用 Mybatis中什么时候应该声明jdbcType? 当Mybatis不能自动识别 ...
- NodeJS后台
NodeJS后台 后台: 1.PHP 2.Java 3.Python 优势 1.性能 2.跟前台JS配合方便 3.NodeJS便于前端学习 https://nodejs.org/en/ 1.切换盘符 ...