strom部署问题
1.storm 引用的 kafka和线上的kafka版本不一致
2.bolt的prepare初始化elasticsearch连接慢,导致第一次处理数据是总是有问题
storm调用prepare方法是异步调用,不会等待所有的bolt中的prepare都完成。在处理第一条数据时等待一段时间,
3.时间窗口长度设置,默认情况下时间窗口的时间长度不能超过消息超时时间。否则会出现异常:Window duration (length + sliding interval) value 32000 is more than topology.message.timeout.secs value 10000
设置消息超时时间 topology.message.timeout.secs
4.storm消费kafka的偏移量无法保存,提示:Error:KeeperErrorCode = NoNode for /storm_kafka/consumers_sdk_start
需要配置spoutConfig.zkServers 和 spoutConfig.zkPort 指定偏移量存储的zookeeper服务器
5.kafka客户端与kafka版本不一致问题,运行topology是出现:java.nio.BufferUnderflowException
6.ERROR o.a.s.util - Async loop died! java.lang.RuntimeException: java.nio.channels.ClosedChannelException
去某个partitions中取数据的时候,storm不能访问当前partitions的broker。
是telnet端口,或者ping当天borker不通造成。可能是没有开通权限或者没有配置ip和host的映射
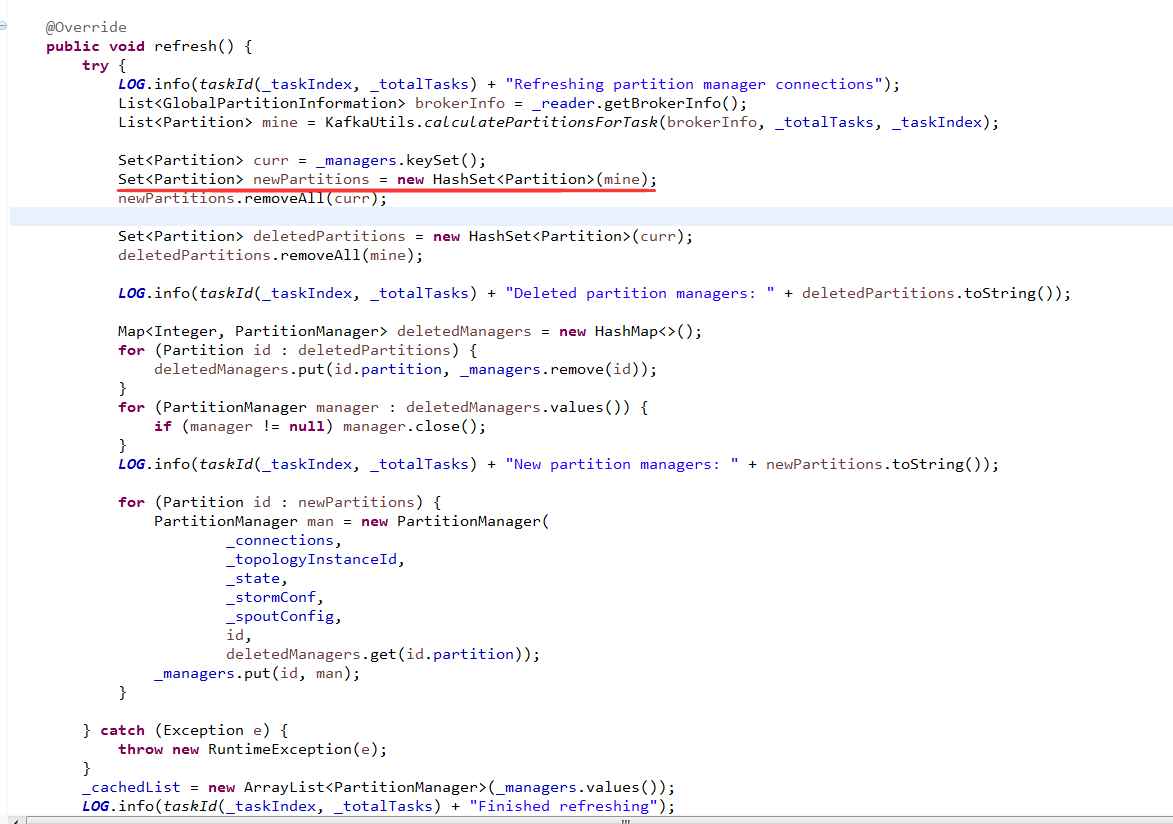
打断点调试org.apache.storm.kafka.ZkCoordinator.refresh的方法,发现newpartitions里面有个存储的是hostname:9092
strom部署问题的更多相关文章
- storm单机环境部署
前面说过storm集群的部署,这篇主要介绍storm单机环境部署,其实他们之间很类似,就是将之前配置文件中所有的集群条目改成本机的地址即可,部署之前应该按前面solr和zookeeper单机环境部署那 ...
- Flume+Kafka+Strom基于伪分布式环境的结合使用
目录: 一.Flume.Kafka.Storm是什么,如何安装? 二.Flume.Kafka.Storm如何结合使用? 1) 原理是什么? 2) Flume和Kafka的整合 3) Kafka和St ...
- 大白话strom——问题收集(持续更新ing)
本文导读: 1.基于storm的应用 2.storm的单点故障解决 3.strom与算法的结合学习4.杂记——常见问题的解答5.http://www.blogchong.com/catalog.asp ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- 对strom的理解
1.什么是strom: storm是一个分布式实时计算系统,用户只需要提供自己的插件(例如一个jar包,其中编写用户自己的逻辑代码),然后将它部署到storm服务器上,storm的master服务器就 ...
- Strom
storm 实时分析概念 离线分析 通常是 需要一段时间的数据积累 积累到一定数量数据后 开始离线分析 无论数据量多大 离线分析 有开始 也有结束 最终得到 ...
- 2017.4.5 Strom
Strom是分布式实时计算系统,它对于实时计算的意义类似于hadoop对于批处理的意义.与Storm关系密切的语言:核心代码用clojure书写,实用程序用python开发,使用java开发拓扑. S ...
- Linux 下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)
一.应用场景介绍 本文主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联网的Linux环境和脱机的Linux环境下是如何安装的.因为大多数时候,公司的生产环境是在内网环境下,无外网 ...
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
随机推荐
- Unity 宽度适配 NGUI
这是很久之前写的一篇Note,现在移到Blog上来,可能有些参数,NGUI插件等等不和现在版本相同.不过大概的思路应该不会错. ps: 可能有部分內容是摘抄自其他作者,没办法考证了,如有请务必联系我. ...
- scss语法格式(常用版记录)
这篇文章是我自己在学习Scss时的笔记~ 更多学习可以参照官网(链接:https://www.sass.hk/docs/) 一,Scss语法格式 1.嵌套规则 2.父选择器&(伪类嵌套 ...
- 【转】Linux下常用压缩 解压命令和压缩比率对比
https://www.cnblogs.com/joshua317/p/6170839.html 常用的格式有:tar, tar.gz(tgz), tar.bz2, 不同方式,压缩和解压方式所耗CPU ...
- Java基础 线程的通信的三个方法/ 交替数数线程 / 生产者&消费者线程问题
线程通讯笔记: /** 线程通信 三个方法: * wait(): 调用该方法 是该调用的方法的线程释放共享资源的锁,进入等待状态,直至被唤醒 * notify() : 可以唤醒队列中的第一个等待同一共 ...
- Nginx服务器的Websockets配置方法
这篇文章主要介绍了简介Nginx服务器的Websockets配置方法,是使用Nginx服务器的网管的必备知识XD~需要的朋友可以参考下 Nginx 1.3.13 已经发布了,该版本支持 Connect ...
- easyui-filebox上传图片到阿里
应用场景:在fixbox图片上传时在预览图片img标签底下点击按钮触发一下函数 参考:https://www.cnblogs.com/awzf/p/9843814.html js //修改该时上传产品 ...
- java web项目中后台控制层对参数进行自定义验证 类 Pattern
Pattern pattern = Pattern.compile("/^([1-9]\d+元*|[0]{0,1})$/");//将给定的正则表达式编译到模式中 if(!" ...
- python中的几种数据类型(一)
一.整型(数字) python2中有长整形long python3 中全都是整型 int n = 56 print(n.bit_length()) # 0011 1000 # 12 ...
- python MySQL安装依赖报错的坑
0X01 问题 MySQL-python是python调用MySQL的常用库 通常安装时会遇到某些坑. EnvironmentError: mysql_config not found yum -y ...
- 006_FreeRTOS其他API函数
(一)FreeRTOS其他API函数是在调试中使用的,具体使用的看书本,贴出来为了方便查找 (二)FreeRTOS其他API函数 (三)常用 1. uxTaskGetSystemState() 获取信 ...