hive面试题(免费拿走不谢)
Hive 最常见的几个面试题
1.hive 的使用, 内外部表的区别,分区作用, UDF 和 Hive 优化
(1)hive 使用:仓库、工具
(2)hive 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除
外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构。
(3)分区作用:防止数据倾斜
(4)UDF 函数:用户自定义的函数 (主要解决格式,计算问题 ),需要继承 UDF 类
java 代码实现
class TestUDFHive extends UDF {
public String evalute(String str){
try{
return "hello"+str
}catch(Exception e){
return str+"error"
}
}
}
(5)sort by和order by之间的区别?
使用order by会引发全局排序;
select * from baidu_click order by click desc;
使用 distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
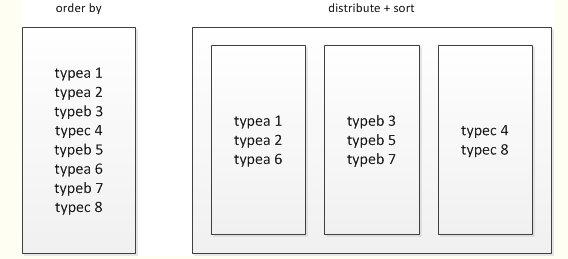
sort by的排序发生在每个reduce里,order by和sort by之间的不同点是前者保证在全局进行排序,而后者仅保证在每个reduce内排序,如果有超过1个reduce,sort by可能有部分结果有序。
注意:它也许是混乱的作为单独列排序对于sort by和cluster by。不同点在于cluster by的分区列和sort by有多重reduce,reduce内的分区数据时一致的。
(6)Hive 优化:看做 mapreduce 处理
排序优化: sort by 效率高于 order by。分区:使用静态分区 (statu_date="20160516",location="beijin") ,每个分区对应 hdfs 上的一个目录,减少 job 和 task 数量:使用表链接操作,解决 groupby 数据倾斜问题:设置hive.groupby.skewindata=true ,那么 hive 会自动负载均衡,小文件合并成大文件:表连接操作,使用 UDF 或 UDAF 函数:
面试题有点多,过几天再来更新
hive面试题(免费拿走不谢)的更多相关文章
- Hive 笔试题
Hive 笔试题 考试时间: 姓名:____________ 考试成绩:____________ 考试时长:180 分钟 注意事项: 1. 自主答题,不能参考任何除本试卷外的其它资料. 2. 总成绩共 ...
- 腾讯音乐Android工程师一面面试题记录,拿走不谢!
最近参加了一次鹅厂音乐Android工程师面试,这里凭记忆记录了一些一面的面试题,希望能帮到正在面试的你! 1.Java调用函数传入实际参数时,是值传递还是引用传递? 2.单例模式的DCL方式,为什么 ...
- hive面试题
1. Hive数据倾斜原因: key分布不均匀 业务数据本身的特性 SQL语句造成数据倾斜解决方法hive设置hive.map.aggr=true和hive.groupby.skewindata=tr ...
- hive 面试题 转载
转自:http://blog.csdn.net/ningguixin/article/details/12852051 有一张很大的表:TRLOG该表大概有2T左右TRLOG:CREATE TABLE ...
- 一道hive面试题:explode map字段
需要找到每个学生最好的课程和成绩,最差的课程和成绩,以及各科的平均分 文本数据如下: name scores张三 语文:,数学:,英语:,历史:,政治:,物理:,化学:,地理:,生物: 李四 语文:, ...
- 转:hive面试题
有一张很大的表:TRLOG该表大概有2T左右TRLOG:CREATE TABLE TRLOG(PLATFORM string,USER_ID int,CLICK_TIME string,CLICK_U ...
- hive 面试题
使用 Hive或者自定义 MR 实现如下逻辑 product_no lac_id moment start_time user_id county_id staytime city_id 134291 ...
- Idea牛逼插件,拿走不谢
1.grep console java 开发的过程中,日志都会输出到console,输出的内容是非常多的,所以需要有一个工具可以方便的查找日志,或者可以非常明显显示我们关注的内容,grep conso ...
- Hive面试题整理(一)
1.Hive表关联查询,如何解决数据倾斜的问题?(☆☆☆☆☆) 1)倾斜原因:map输出数据按key Hash的分配到reduce中,由于key分布不均匀.业务数据本身的特.建表时考虑不周.等原因 ...
随机推荐
- win10 下cuda 9.0 卸载
1.首先 对于cuda8.0.cuda7.5的卸载都可以兼容 安装cuda9.0之后,电脑原来的NVIDIA图形驱动会被更新,NVIDIA Physx系统软件也会被更新(安装低版cuda可能不会被更新 ...
- 高性能高可用的微服务框架TarsGo的腾讯实践
conference/2.3 高性能高可用的微服务框架TarsGo的腾讯实践 - 陈明杰.pdf at master · gopherchina/conferencehttps://github.co ...
- qt application logging
“AnalysisPtsDataTool201905.exe”(Win32): 已加载“F:\OpencvProject\ZY-Project\x64\Debug\AnalysisPtsDataToo ...
- ckpt convert to pb
import tensorflow as tf #from create_tf_record import * from tensorflow.python.framework import grap ...
- (翻译) closures-are-not-complicated
总计:读完这篇文章需要20分钟 这篇文章讲解了闭包的一些内容,作者是拿ES5规范中的一些名词来讲的. 所以可能和博客上一篇文章中提到的binding object, (lexical enviro ...
- kubernetes之StatefulSet部署zk和kafka
前提 至少需要三个node节点,否则修改亲和性配置 如果外部访问,需要自己暴露 需要有个storageClass,这样做的原因是避免手动创建pv了 部署zk和kafka 参考: https://www ...
- Flutter的闪屏动画案例AnimationController
打开一个APP,经常会看到精美的启动页,这种启动页也称为闪屏动画.它是从无到有有一个透明度的渐变动画的.图像展示完事后,才跳转到用户可操作的页面. AnimationController Animat ...
- xshell和Xftp连接虚拟机(转载)
首先连接虚拟机之前,先配置自己的IP地址,见博客https://www.cnblogs.com/xuzhaoyang/p/11264573.html xshell和Xftp下载请到官网http://w ...
- Unity Shader基础(1):基础
一.Shaderlab语法 1.给Shader起名字 Shader "Custom/MyShader" 这个名称会出现在材质选择使用的下拉列表里 2. Properties (属性 ...
- Centos 配置jdk环境变量
1.安装方法 windows 下载,复制到 linux,解压,配置环境变量 linux 使用 wget 下载,解压,配置环境变量 linux 使用 yum 直接安装,环境变量自动配置好 2.查看是否已 ...