hive面试题(免费拿走不谢)
Hive 最常见的几个面试题
1.hive 的使用, 内外部表的区别,分区作用, UDF 和 Hive 优化
(1)hive 使用:仓库、工具
(2)hive 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除
外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构。
(3)分区作用:防止数据倾斜
(4)UDF 函数:用户自定义的函数 (主要解决格式,计算问题 ),需要继承 UDF 类
java 代码实现
class TestUDFHive extends UDF {
public String evalute(String str){
try{
return "hello"+str
}catch(Exception e){
return str+"error"
}
}
}
(5)sort by和order by之间的区别?
使用order by会引发全局排序;
select * from baidu_click order by click desc;
使用 distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
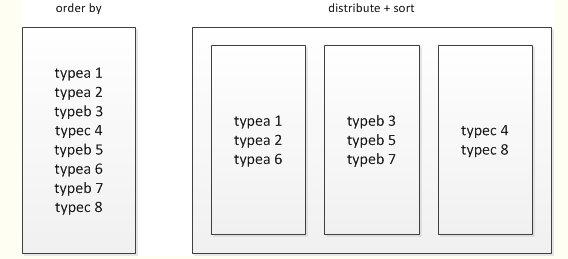
sort by的排序发生在每个reduce里,order by和sort by之间的不同点是前者保证在全局进行排序,而后者仅保证在每个reduce内排序,如果有超过1个reduce,sort by可能有部分结果有序。
注意:它也许是混乱的作为单独列排序对于sort by和cluster by。不同点在于cluster by的分区列和sort by有多重reduce,reduce内的分区数据时一致的。
(6)Hive 优化:看做 mapreduce 处理
排序优化: sort by 效率高于 order by。分区:使用静态分区 (statu_date="20160516",location="beijin") ,每个分区对应 hdfs 上的一个目录,减少 job 和 task 数量:使用表链接操作,解决 groupby 数据倾斜问题:设置hive.groupby.skewindata=true ,那么 hive 会自动负载均衡,小文件合并成大文件:表连接操作,使用 UDF 或 UDAF 函数:
面试题有点多,过几天再来更新
hive面试题(免费拿走不谢)的更多相关文章
- Hive 笔试题
Hive 笔试题 考试时间: 姓名:____________ 考试成绩:____________ 考试时长:180 分钟 注意事项: 1. 自主答题,不能参考任何除本试卷外的其它资料. 2. 总成绩共 ...
- 腾讯音乐Android工程师一面面试题记录,拿走不谢!
最近参加了一次鹅厂音乐Android工程师面试,这里凭记忆记录了一些一面的面试题,希望能帮到正在面试的你! 1.Java调用函数传入实际参数时,是值传递还是引用传递? 2.单例模式的DCL方式,为什么 ...
- hive面试题
1. Hive数据倾斜原因: key分布不均匀 业务数据本身的特性 SQL语句造成数据倾斜解决方法hive设置hive.map.aggr=true和hive.groupby.skewindata=tr ...
- hive 面试题 转载
转自:http://blog.csdn.net/ningguixin/article/details/12852051 有一张很大的表:TRLOG该表大概有2T左右TRLOG:CREATE TABLE ...
- 一道hive面试题:explode map字段
需要找到每个学生最好的课程和成绩,最差的课程和成绩,以及各科的平均分 文本数据如下: name scores张三 语文:,数学:,英语:,历史:,政治:,物理:,化学:,地理:,生物: 李四 语文:, ...
- 转:hive面试题
有一张很大的表:TRLOG该表大概有2T左右TRLOG:CREATE TABLE TRLOG(PLATFORM string,USER_ID int,CLICK_TIME string,CLICK_U ...
- hive 面试题
使用 Hive或者自定义 MR 实现如下逻辑 product_no lac_id moment start_time user_id county_id staytime city_id 134291 ...
- Idea牛逼插件,拿走不谢
1.grep console java 开发的过程中,日志都会输出到console,输出的内容是非常多的,所以需要有一个工具可以方便的查找日志,或者可以非常明显显示我们关注的内容,grep conso ...
- Hive面试题整理(一)
1.Hive表关联查询,如何解决数据倾斜的问题?(☆☆☆☆☆) 1)倾斜原因:map输出数据按key Hash的分配到reduce中,由于key分布不均匀.业务数据本身的特.建表时考虑不周.等原因 ...
随机推荐
- concurrency parallel 并发 并行 parallelism
在传统的多道程序环境下,要使作业运行,必须为它创建一个或几个进程,并为之分配必要的资源.当进程运行结束时,立即撤销该进程,以便能及时回收该进程所占用的各类资源.进程控制的主要功能是为作业创建进程,撤销 ...
- Flex 布局教程实例
Flex 布局教程实例 一.Flex 布局是什么? Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性. 任何一个容器都可以指定为 F ...
- 国内it论坛
社区是聚集一类具有相同爱好或者相同行业的群体,IT技术社区就是聚集了IT行业内的技术人,在技术社区可以了解到行业的最新进展,学习最前沿的技术,认识有相同爱好的朋友,在一起学习和交流. 技术社区一般有三 ...
- 从零搭建配置Cuckoo Sandbox
1.安装依赖 $ sudo apt-get install git mongodb libffi-dev build-essential python-django python python-dev ...
- JAVA 基础编程练习题46 【程序 46 字符串连接】
46 [程序 46 字符串连接] 题目:两个字符串连接程序 package cskaoyan; public class cskaoyan46 { public static void main(St ...
- iOS 11适配
1.http://www.cocoachina.com/ios/20170915/20580.html 简书App适配iOS 11 2.http://www.jianshu.com/p/efb ...
- node.js运行内存堆溢出的解决办法
我是在将一组80多列13万多行的数据通过node-xlsx的时候出现的内存堆溢出的情况. 解决办法时将: node app.js 改成: node --max_old_space_size=10000 ...
- python基础----redis模块
数据库 关系型数据 例如mysql,有表还有约束条件等 非关系型 k-v形式 memcache 存在内存中 redis 存在内存 mongodb 数据存在磁盘 import redis #string ...
- selenium3 web自动化测试框架 二:页面基础操作、元素定位方法封装、页面操作方法封装
学习目的: 掌握自动化框架中需要的一些基础web操作 正式步骤: 使用title_contains检查页面是否正确 # -*- coding:utf-8 -*- import time from se ...
- flask不得不知的基础
python与flask不得不说的小秘密 常识引入 什么是装饰器? 在不改变源码的前提下,对函数之前前后进行功能定制. 开放封闭原则:不改变函数内部代码,在函数外部进行修改. 基本写法 import ...