18.linux日志收集数据到hdfs上面
先创建一个目录

在这个job目录下创建upload.sh文件

[hadoop@node1 ~]$ pwd
/home/hadoop
[hadoop@node1 ~]$ mkdir job
[hadoop@node1 ~]$ ls
Desktop Downloads job Music Pictures Templates
Documents hive logs mysql-community-release-el7-.noarch.rpm Public Videos
[hadoop@node1 ~]$ cd job/
[hadoop@node1 job]$ vim upload.sh
对upload.sh进行编辑
#!/bin/bash #set java env
export JAVA_HOME=/opt/modules/jdk1..0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH #set hadoop env
export HADOOP_HOME=/opt/modules/hadoop-2.6.
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH log_src_dir=/home/hadoop/logs/log/
log_toupload_dir=/home/hadoop/logs/toupload/
hdfs_root_dir=/data/clickLog// echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi done #找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
然后新建目录,并上传日志文件
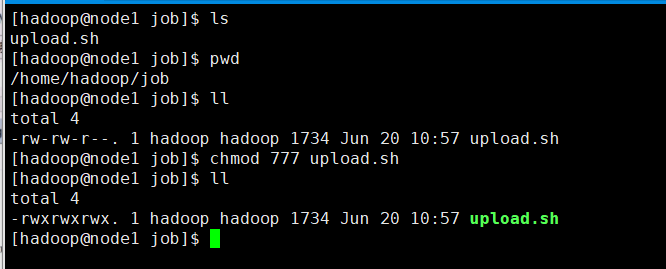
给脚本赋予权限
[hadoop@node1 job]$ ls
upload.sh
[hadoop@node1 job]$ pwd
/home/hadoop/job
[hadoop@node1 job]$ ll
total
-rw-rw-r--. hadoop hadoop Jun : upload.sh
[hadoop@node1 job]$ chmod upload.sh
[hadoop@node1 job]$ ll
total
-rwxrwxrwx. hadoop hadoop Jun : upload.sh
[hadoop@node1 job]$
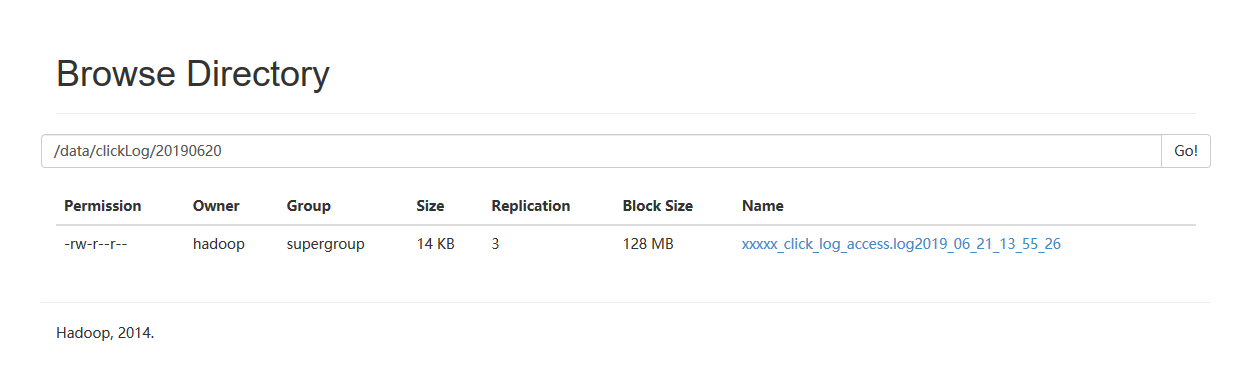
在HDFS上新建目录

执行脚本

可以看到结果

18.linux日志收集数据到hdfs上面的更多相关文章
- 日志审计与分析实验三(rsyslog服务器端和客户端配置)(Linux日志收集)
Linux日志收集 一.实验目的: 1.掌握rsyslog配置方法 2.配置rsyslog服务收集其他Linux服务器日志: C/S架构:客户端将其日志上传到服务器端,通过对服务器端日志的查询,来实现 ...
- 大数据学习——实现多agent的串联,收集数据到HDFS中
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flume agent l ...
- Flume + HDFS + Hive日志收集系统
最近一段时间,负责公司的产品日志埋点与收集工作,搭建了基于Flume+HDFS+Hive日志搜集系统. 一.日志搜集系统架构: 简单画了一下日志搜集系统的架构图,可以看出,flume承担了agent与 ...
- Linux下rsyslog日志收集服务环境部署记录
rsyslog 可以理解为多线程增强版的syslog. 在syslog的基础上扩展了很多其他功能,如数据库支持(MySQL.PostgreSQL.Oracle等).日志内容筛选.定义日志格式模板等.目 ...
- Linux下rsyslog日志收集服务环境部署记录【转】
rsyslog 可以理解为多线程增强版的syslog. 在syslog的基础上扩展了很多其他功能,如数据库支持(MySQL.PostgreSQL.Oracle等).日志内容筛选.定义日志格式模板等.目 ...
- Flume-NG + HDFS + HIVE 日志收集分析
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- Scribe+HDFS日志收集系统安装方法
1.概述 Scribe是facebook开源的日志收集系统,可用于搜索引擎中进行大规模日志分析处理.其通常与Hadoop结合使用,scribe用于向HDFS中push日志,而Hadoop通过MapRe ...
- Linux下单机部署ELK日志收集、分析环境
一.ELK简介 ELK是elastic 公司旗下三款产品ElasticSearch .Logstash .Kibana的首字母组合,主要用于日志收集.分析与报表展示. ELK Stack包含:Elas ...
- Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式
Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式 P703 Linux读写内存数据的三种方式 1.read ,write方式会在用户空间和内核空间不断拷贝数据, ...
随机推荐
- BZOJ 1257 [CQOI2007]余数之和 数学
都不知道说什么好...咕咕到现在.. 求:$\sum_{i=1}^n \space k\space mod \space i$ 即求:$n*k-\sum_{i=1}^n\space \lfloor \ ...
- 小米oj 有多少个等差数列(动态规划)
有多少个等差数列? 序号:#20难度:困难时间限制:500ms内存限制:10M 描述 等差数列是常见数列的一种,如果一个数列从第二项起,每一项与它的前一项的差等于同一个常数,这个数列就叫做等差数列, ...
- [Cogs] 最大数maxnumber
http://cogs.pro:8080/cogs/problem/problem.php?pid=1844 Luogu 的数据真zhizhang Cogs AC #include <iostr ...
- Codevs 2188 最长上升子序列(变式)
2188 最长上升子序列 时间限制: 1 s 空间限制: 32000 KB 题目等级 : 钻石 Diamond 题目描述 Description LIS问题是最经典的动态规划基础问题之一.如果要求一个 ...
- 用sql语句查询一列名中的各个数值的个数
SELECT COUNT(case when f.fileState=2 then 0 end) as fixed,COUNT(case when f.fileState=3 then 0 end) ...
- UVA 796 Critical Links —— (求割边(桥))
和求割点类似,只要把>=改成>即可.这里想解释一下的是,无向图没有重边,怎么可以使得low[v]=dfn[u]呢?只要它们之间再来一个点即可. 总感觉图论要很仔细地想啊- -一不小心就弄混 ...
- conda虚拟环境 相关操作
查询环境 conda env list 或者 conda info --envs 创建环境 conda create -n your_env_name python=3.7 删除环境 conda re ...
- 预处理、const、static与sizeof-为什么要引入内联函数
1:引入内联函数的主要目的是,用它替代C语言中表达形式的宏定义来解决程序中函数调用的效率问题.在C语言里可以使用如下的宏定义: #define ExpressionName(Var1,Var2) (V ...
- 预处理、const、static与sizeof-用#define实现宏并求最大值和最小值
1:实现代码: #define MAX(x,y) (((x)>(y)) ? (x):(y)) #define MIN(x,y) (((x)>(y)) ? (x):(y)) 需要注意的几点: ...
- Linux设备驱动程序 之 open和release
open方法 open方法提供给驱动程序以初始化的能力,在大部分驱动程序汇总,open应该完成以下工作: 1. 检查特定设备的错误,如设备为准备就绪或者硬件问题: 2. 如果设备是首次打开,则对其进行 ...