LOGIT REGRESSION
Version info: Code for this page was tested in SPSS 20.
Logistic regression, also called a logit model, is used to model dichotomous outcome variables. In the logit model the log odds of the outcome is modeled as a linear combination of the predictor variables.
Please note: The purpose of this page is to show how to use various data analysis commands. It does not cover all aspects of the research process which researchers are expected to do. In particular, it does not cover data cleaning and checking, verification of assumptions, model diagnostics and potential follow-up analyses.
Examples
Example 1: Suppose that we are interested in the factors
that influence whether a political candidate wins an election. The
outcome (response) variable is binary (0/1); win or lose.
The predictor variables of interest are the amount of money spent on the campaign, the
amount of time spent campaigning negatively and whether or not the candidate is an
incumbent.
Example 2: A researcher is interested in how variables, such as GRE (Graduate Record Exam scores),
GPA (grade
point average) and prestige of the undergraduate institution, effect admission into graduate
school. The response variable, admit/don’t admit, is a binary variable.
Description of the data
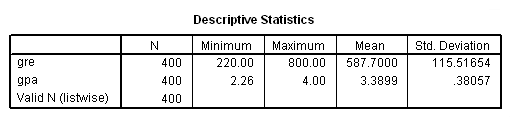
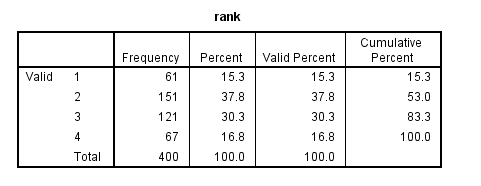
For our data analysis below, we are going to expand on Example 2 about getting into graduate school. We have generated hypothetical data, which can be obtained from our website by clicking on binary.sav. You can store this anywhere you like, but the syntax below assumes it has been stored in the directory c:data. This dataset has a binary response (outcome, dependent) variable called admit, which is equal to 1 if the individual was admitted to graduate school, and 0 otherwise. There are three predictor variables: gre, gpa, and rank. We will treat the variables gre and gpa as continuous. The variable rank takes on the values 1 through 4. Institutions with a rank of 1 have the highest prestige, while those with a rank of 4 have the lowest. We start out by opening the dataset and looking at some descriptive statistics.
get file = "c:databinary.sav". descriptives /variables=gre gpa.
frequencies /variables = rank.
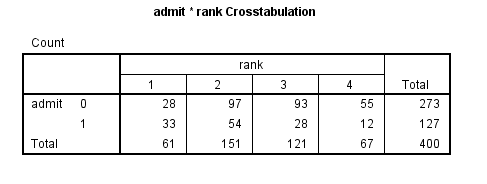
crosstabs /tables = admit by rank.
Analysis methods you might consider
Below is a list of some analysis methods you may have encountered. Some of the methods listed are quite reasonable while others have either fallen out of favor or have limitations.
- Logistic regression, the focus of this page.
- Probit regression. Probit analysis will produce results similar
logistic regression. The choice of probit versus logit depends largely on
individual preferences.
- OLS regression. When used with a binary response variable, this model is known
as a linear probability model and can be used as a way to
describe conditional probabilities. However, the errors (i.e., residuals) from the linear probability model violate the homoskedasticity and
normality of errors assumptions of OLS
regression, resulting in invalid standard errors and hypothesis tests. For
a more thorough discussion of these and other problems with the linear
probability model, see Long (1997, p. 38-40).
- Two-group discriminant function analysis. A multivariate method for dichotomous outcome variables.
- Hotelling’s T2. The 0/1 outcome is turned into the
grouping variable, and the former predictors are turned into outcome
variables. This will produce an overall test of significance but will not
give individual coefficients for each variable, and it is unclear the extent
to which each "predictor" is adjusted for the impact of the other
"predictors."
Logistic regression
Below we use the logistic regression command to run a model predicting the outcome variable admit, using gre, gpa, and rank. The categorical option specifies that rank is a categorical rather than continuous variable. The output is shown in sections, each of which is discussed below.
logistic regression admit with gre gpa rank
/categorical = rank.
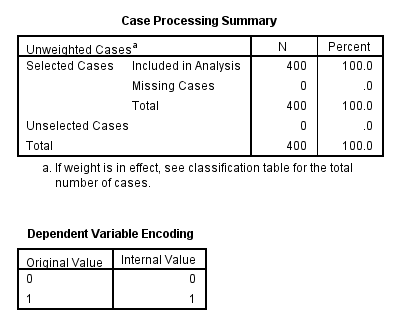
The first table above shows a breakdown of the number of cases used and not used in the analysis. The second table above gives the coding for the outcome variable, admit.
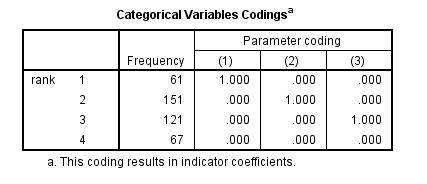
The table above shows how the values of the categorical variable rank were handled, there are terms (essentially dummy variables) in the model for rank=1,rank=2, and rank=3; rank=4 is the omitted category.
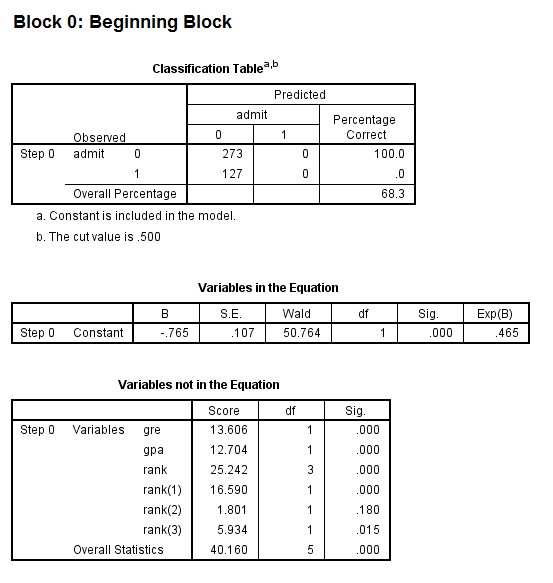
- The first model in the output is a null model, that is, a model with no predictors.
- The constant in the table labeled Variables in the Equation gives the unconditional log odds of admission (i.e., admit=1).
- The table labeled Variables not in the Equation gives the results of a score test, also known as a Lagrange multiplier test. The column labeled Score gives the estimated change in model fit if the term is added to the model, the other two columns give the degrees of freedom, and p-value (labeled Sig.) for the estimated change. Based on the table above, all three of the predictors, gre, gpa, and rank, are expected to improve the fit of the model.
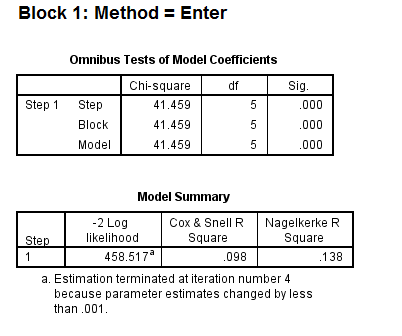
- The first table above gives the overall test for the model that includes the predictors. The chi-square value of 41.46 with a p-value of less than 0.0005 tells us that our model as a whole fits significantly better than an empty model (i.e., a model with no predictors).
- The -2*log likelihood (458.517) in the Model Summary table can be used in comparisons of nested models, but we won’t show an example of that here. This table also gives two measures of pseudo R-square.
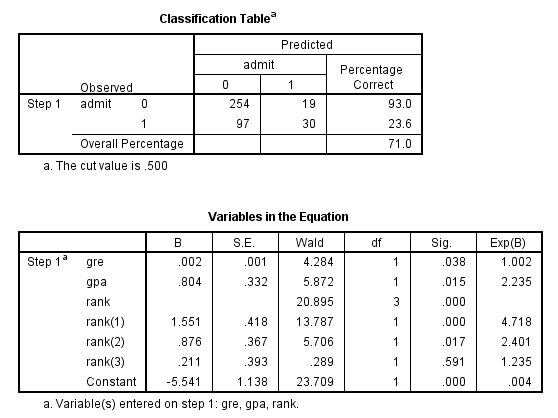
- In the table labeled Variables in the Equation we see the coefficients, their standard errors, the Wald test statistic with associated degrees of freedom and p-values, and the exponentiated coefficient (also known as an odds ratio). Both gre and gpa are statistically significant. The overall (i.e., multiple degree of freedom) test for rank is given first, followed by the terms for rank=1, rank=2, and rank=3. The overall effect of rank is statistically significant, as are the terms for rank=1 and rank=2. The logistic regression coefficients give the change in the log odds of the outcome for a one unit increase in the predictor variable.
- For every one unit change in gre, the log odds of admission (versus non-admission) increases by 0.002.
- For a one unit increase in gpa, the log odds of being admitted to graduate school increases by 0.804.
- The indicator variables for rank have a slightly different interpretation. For example, having attended an undergraduate institution with rank of 1, versus an institution with a rank of 4, increases the log odds of admission by 1.551.
Things to consider
- Empty cells or small cells: You should check for empty or small
cells by doing a crosstab between categorical predictors and the outcome variable. If a cell has very few cases (a small cell), the model may become unstable or it might not run at all.
- Separation or quasi-separation (also called perfect prediction), a condition in which the outcome does not vary at some levels of the independent variables. See our page FAQ: What is complete or quasi-complete separation in logistic/probit regression and how do we deal with them? for information on models with perfect prediction.
- Sample size: Both logit and probit models require more cases than OLS regression because they use maximum likelihood estimation techniques. It is also important to keep in mind that when the outcome is rare, even if the overall dataset is large, it can be difficult to estimate a logit model.
- Pseudo-R-squared: Many different measures of pseudo-R-squared exist. They all attempt to provide information similar to that provided by R-squared in OLS regression; however, none of them can be interpreted exactly as R-squared in OLS regression is interpreted. For a discussion of various pseudo-R-squareds see Long and Freese (2006) or our FAQ page What are pseudo R-squareds?
- Diagnostics: The diagnostics for logistic regression are different from those for OLS regression. For a discussion of model diagnostics for logistic regression, see Hosmer and Lemeshow (2000, Chapter 5). Note that diagnostics done for logistic regression are similar to those done for probit regression.
See also
- Annotated Output for Logistic Regression
- Textbook Example: Applied Logistic Regression (2nd Edition) by David Hosmer and Stanley Lemeshow
- SPSS Frequently Asked Questions
- SPSS Code Fragments
- Stat Books for Loan, Logistic Regression and Limited Dependent Variables
References
- Hosmer, D. & Lemeshow, S. (2000). Applied Logistic Regression (Second Edition).
New York: John Wiley & Sons, Inc.
- Long, J. Scott (1997). Regression Models for Categorical and Limited Dependent Variables.
Thousand Oaks, CA: Sage Publications.
LOGIT REGRESSION的更多相关文章
- Logistic回归模型和Python实现
回归分析是研究变量之间定量关系的一种统计学方法,具有广泛的应用. Logistic回归模型 线性回归 先从线性回归模型开始,线性回归是最基本的回归模型,它使用线性函数描述两个变量之间的关系,将连续或离 ...
- 机器学习算法基础(Python和R语言实现)
https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/?spm=5176.100239.blo ...
- Day3 《机器学习》第三章学习笔记
这一章也是本书基本理论的一章,我对这章后面有些公式看的比较模糊,这一会章涉及线性代数和概率论基础知识,讲了几种经典的线性模型,回归,分类(二分类和多分类)任务. 3.1 基本形式 给定由d个属性描述的 ...
- 从线性模型(linear model)衍生出的机器学习分类器(classifier)
1. 线性模型简介 0x1:线性模型的现实意义 在一个理想的连续世界中,任何非线性的东西都可以被线性的东西来拟合(参考Taylor Expansion公式),所以理论上线性模型可以模拟物理世界中的绝大 ...
- 壁虎书4 Training Models
Linear Regression The Normal Equation Computational Complexity 线性回归模型与MSE. the normal equation: a cl ...
- python: 模型的统计信息
/*! * * Twitter Bootstrap * */ /*! * Bootstrap v3.3.7 (http://getbootstrap.com) * Copyright 2011-201 ...
- [译]用R语言做挖掘数据《四》
回归 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: 1. ...
- Machine Learning and Data Mining(机器学习与数据挖掘)
Problems[show] Classification Clustering Regression Anomaly detection Association rules Reinforcemen ...
- (数据科学学习手札24)逻辑回归分类器原理详解&Python与R实现
一.简介 逻辑回归(Logistic Regression),与它的名字恰恰相反,它是一个分类器而非回归方法,在一些文献里它也被称为logit回归.最大熵分类器(MaxEnt).对数线性分类器等:我们 ...
随机推荐
- 下一代容器技术podman简介
PODMAN主要由红帽发起和推动,是下一代的容器技术,包括如下三个模块:Podman,Skopeo和Buildah这三个工具都是符合OCI计划下的工具(github/containers).主要是由R ...
- C语言例题
1.连接两个字符串 将两个字符串连接,不要用stract函数 2.求矩阵外围元素之和 求3行3列矩阵的外围元素之和. 3.求矩阵主对角线和副对角线元素之和 求5行5列矩阵的主对角线和副对角线元素之和. ...
- Xilinx FFT IP核缩放因子说明
以1024点FFT为例, reg [9:0] scale_sch = 10'b11_10_01_01_01; 流水线结构中,将每个基 2 的蝶形处理单元视为一个阶段. 每个阶段进行一次数据的缩减,缩减 ...
- 017_linuxC++之_多态的引入
多态:一种接口,多种方法(同一种调用方法,根据不同的对象,调用不同类中的函数)静态联编:非虚函数,在编译时确定好动态联编: 1. 对象里有指针,指向虚函数表 2. 通过指针,找到表,调用虚函数 3 ...
- http message
- Non-standard serial port baud rate setting
////combuad_recv.cpp #include <stdio.h> /*标准输入输出定义*/ #include <stdlib.h> /*标准函数库定义*/ #in ...
- 还是畅通工程(HDU 1233)
某省调查乡村交通状况,得到的统计表中列出了任意两村庄间的距离.省政府"畅通工程"的目标是使全省任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只要能间接通过公路可达即可 ...
- [linux]kali apt-get 安装mysql
环境: Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux 本来是想要装m ...
- 【SecureCRT】SecureCRT 护眼配色
终端有一个好的配色,不仅能保护自己的眼睛,也能给人一个好心情,本配色方案适合任意一种SSH客户端软件. 设置背景颜色 Options => Sessions options => ...
- HTTP第八、九章之网关、隧道、web机器人
网关 网关(gateway): 资源和应用程序之间的粘合剂.应用程序可以(通过HTTP或其它已定义的接口)请求网关来处理某条请求,网关可以提供一条响应.网关可以向数据库发送查询语句,或者生成动态的内容 ...