caffe数据集——LMDB
LMDB介紹
Caffe使用LMDB來存放訓練/測試用的數據集,以及使用網絡提取出的feature(為了方便,以下還是統稱數據集)。數據集的結構很簡單,就是大量的矩陣/向量數據平鋪開來。數據之間沒有什麼關聯,數據內沒有復雜的對象結構,就是向量和矩陣。既然數據並不復雜,Caffe就選擇了LMDB這個簡單的數據庫來存放數據。
LMDB的全稱是Lightning Memory-Mapped Database,閃電般的內存映射數據庫。它文件結構簡單,一個文件夾,裡面一個數據文件,一個鎖文件。數據隨意複製,隨意傳輸。它的訪問簡單,不需要運行單獨的數據庫管理進程,只要在訪問數據的代碼裡引用LMDB庫,訪問時給文件路徑即可。
圖像數據集歸根究底從圖像文件而來。既然有ImageDataLayer可以直接讀取圖像文件,為什麼還要用數據庫來放數據集,增加讀寫的麻煩呢?我認為,Caffe引入數據庫存放數據集,是為了減少IO開銷。讀取大量小文件的開銷是非常大的,尤其是在機械硬盤上。 LMDB的整個數據庫放在一個文件裡,避免了文件系統尋址的開銷。 LMDB使用內存映射的方式訪問文件,使得文件內尋址的開銷非常小,使用指針運算就能實現。數據庫單文件還能減少數據集複製/傳輸過程的開銷。一個幾萬,幾十萬文件的數據集,不管是直接複製,還是打包再解包,過程都無比漫長而痛苦。 LMDB數據庫只有一個文件,你的介質有多塊,就能複制多快,不會因為文件多而慢如蝸牛。
Datum數據結構
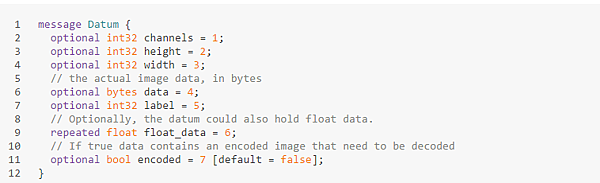
首先需要注意的是,Caffe並不是把向量和矩陣直接放進數據庫的,而是將數據通過caffe.proto裡定義的一個datum類來封裝。數據庫裡放的是一個個的datum序列化成的字符串。 Datum的定義摘錄如下:
所以要使用的話 首先要用pip 下載 lmdb
由於小編已經安裝過了
所以顯示already satisfied

程式碼:
1.從 array 做出 lmdb
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
import numpy as npimport lmdbimport caffeN = 1000# Let's pretend this is interesting dataX = np.zeros((N, 3, 32, 32), dtype=np.uint8)print "x shape is :",X.shape[1]y = np.zeros(N, dtype=np.int64)print "y shape is :",y.shape# We need to prepare the database for the size. We'll set it 10 times# greater than what we theoretically need. There is little drawback to# setting this too big. If you still run into problem after raising# this, you might want to try saving fewer entries in a single# transaction.map_size = X.nbytes * 10print "map_size is:3*32*32*1000*10 --",map_sizeenv = lmdb.open('mylmdb', map_size=map_size)with env.begin(write=True) as txn: # txn is a Transaction object for i in range(N): datum = caffe.proto.caffe_pb2.Datum() #set channels=3 datum.channels = X.shape[1] #set height =32 datum.height = X.shape[2] #set width = 32 datum.width = X.shape[3] datum.data = X[i].tobytes() # or .tostring() if numpy < 1.9 datum.label = int(y[i]) str_id = '{:08}'.format(i) # The encode is only essential in Python 3 txn.put(str_id.encode('ascii'), datum.SerializeToString()) |
產生的資料如下:

2.從lmdb讀取資料:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
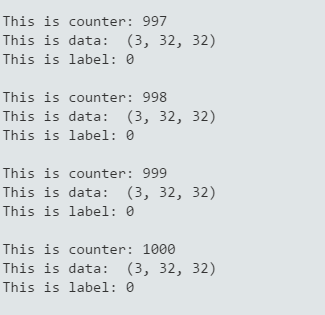
import caffeimport lmdblmdb_env = lmdb.open('mylmdb')lmdb_txn = lmdb_env.begin()lmdb_cursor = lmdb_txn.cursor()datum = caffe.proto.caffe_pb2.Datum()i=0for key, value in lmdb_cursor: i=i+1 datum.ParseFromString(value) label = datum.label data = caffe.io.datum_to_array(datum) print "This is counter:",i print "This is data: ",data.shape print "This is label:",label,"\n" |
運行結果如下:
參考資料:
http://darren1231.pixnet.net/blog/post/328463403-%E5%AD%B8%E6%9C%83%E5%81%9A%E5%87%BA%E8%87%AA%E5%B7%B1%E7%9A%84%E6%95%B8%E6%93%9A%E9%9B%86%28imdb%29--caffe
http://deepdish.io/2015/04/28/creating-lmdb-in-python/
http://rayz0620.github.io/2015/05/25/lmdb_in_caffe/
https://lmdb.readthedocs.io/en/release/
http://stackoverflow.com/questions/33117607/caffe-reading-lmdb-from-python
caffe数据集——LMDB的更多相关文章
- caffe数据集LMDB的生成
本文主要介绍如何在caffe框架下生成LMDB.其中包含了两个任务的LMDB生成方法,一种是分类,另外一种是检测. 分类任务 第一步 生成train.txt和test.txt文件文件 对于一个监督学 ...
- 利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning 数据的组织格式为: 首先,所需要的脚本指令路径为: /home/wangxiao/Downloads/caffe-maste ...
- caffe python lmdb读写
caffe中可以采取lmdb健值数据库的方式向网络中输入数据. 所以操作lmdb就围绕"键-值"的方式访问数据库就好了. Write 我们可以采用cv2来读入自己的图像数据,采用d ...
- Caffe︱构建lmdb数据集、binaryproto均值文件及各类难辨的文件路径名设置细解
Lmdb生成的过程简述 1.整理并约束尺寸,文件夹.图片放在不同的文件夹之下,注意图片的size需要规约到统一的格式,不然计算均值文件的时候会报错. 2.将内容生成列表放入txt文件中.两个txt文件 ...
- 非图片格式如何转成lmdb格式--caffe
链接 LMDB is the database of choice when using Caffe with large datasets. This is a tutorial of how to ...
- caffe读取多标签的lmdb数据
问题描述: lmdb文件支持数据+标签的形式,但是却只能写入一个标签,引入多标签的解决方法有很多,这儿详细说一下我的办法:制作多个data数据,分别加入一个标签.我的方法只适用于标签数量较少的情况,标 ...
- SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证.本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注2 数据集的转换3 使用SSD如 ...
- Windows下用Caffe跑自己的数据(遥感影像)
1 前言 Caffe对于像我这样的初学者来说是一款非常容易上手的深度学习框架.关于用Caffe跑自己的数据这样的博客已经非常多,感谢前辈们为我们提供的这么好的学习资源.这里我主要结合我所在的行业,说下 ...
- 利用Caffe训练模型(solver、deploy、train_val)+python使用已训练模型
本文部分内容来源于CDA深度学习实战课堂,由唐宇迪老师授课 如果你企图用CPU来训练模型,那么你就疯了- 训练模型中,最耗时的因素是图像大小size,一般227*227用CPU来训练的话,训练1万次可 ...
随机推荐
- Angular6项目搭建
参照 草根专栏- ASP.NET Core + Ng6 实战:https://v.qq.com/x/page/b076702elvw.html 安装工具: Nodejs, npm 最新版, h ...
- C++clock()延时循环
函数clock(),返回程序开始执行后所用的系统时间,但是有两个复制问题. 1.clock()返回时间的单位不一定是秒 2.该函数的返回类型在某些系统上可能是Long,也可能是unsigned lon ...
- poj 2155 (二维树状数组 区间修改 求某点值)
Matrix Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 33682 Accepted: 12194 Descript ...
- LeetCode - 389. Find the Difference - 三种不同解法 - ( C++ ) - 解题报告
1.题目大意 Given two strings s and t which consist of only lowercase letters. String t is generated by r ...
- xml解析----java中4中xml解析方法(转载)
转载:https://www.cnblogs.com/longqingyang/p/5577937.html 描述 XML是一种通用的数据交换格式,它的平台无关性.语言无关性.系统无关性.给数据集成与 ...
- 软工网络15团队作业4——Alpha阶段敏捷冲刺-1
各个成员在 Alpha 阶段认领的任务 成员 Alpha 阶段认领的任务 肖世松 编写界面设计代码 杨泽斌 服务器连接与配置 叶文柠 数据库连接与配置 谢庆圆 编写功能板块代码 林伟航 编写功能板块代 ...
- Jenkins系列-Jenkins插件下载镜像加速
可供选择的jenkins2 插件镜像列表: Jenkins 所有镜像列表: http://mirrors.jenkins-ci.org/status.html比如日本的镜像: http://mirro ...
- react-event-pooling
react-event-pooling 事件池 https://codesandbox.io/s/3xp4y9zp7q https://reactjs.org/docs/events.html#eve ...
- [C/C++] C++模板定义格式
函数模板的格式: template <class 形参名,class 形参名,......> 返回类型 函数名(参数列表) { //函数体 } 类模板的格式为: template<c ...
- [计算机网络-应用层] DNS:因特网的目录服务
我们知道有两种方式可以识别主机:通过主机名或者IP地址.人们喜欢便于记忆的主机名标识,而路由器则喜欢定长的.有着层次结构的IP地址.为了折中这些不同的偏好,我们需要一种能进行主机名到IP地址转换的目录 ...