Lucene.Net无障碍学习和使用:索引篇
一、简单认识索引
Lucene.Net的应用相对比较简单。一段时间以来,我最多只是在项目中写点代码,利用一下它的类库而已,对很多名词术语不是很清晰,甚至理解 可能还有偏差。从我过去的博客你也可以看出,语言表达一直不是个人所长,就算”表达“了也有大面积抄书的嫌疑,所以很多概念性的介绍能省则省(除非特别有 别要说明),希望有心的初学者注意,理清概念和辨别技术名词非常重要,请参考相关文档。
Lucene的索引由1或多个segment(片段)构成,一个segment由多个document构成,一个document又由1个或多个field构成,一个field又由一个或多个term构成。下面这张图可以说明一切:
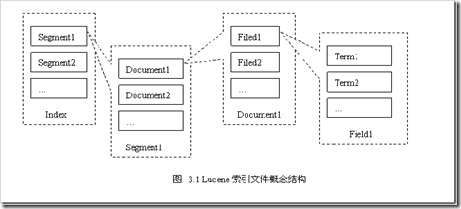
从图中不难看出,Lucene的索引是一个由点到线,由线到面的组成结构,这一点我们可以通过查看Lucene生成的索引文件看出来。
参考图片来源: http://alone2004.spaces.live.com/blog/cns!C2525069080D7BB!675.entry
二、创建、优化、删除和更新索引实践
备注:在解决方案所在文件夹中,有一个测试用的Resource文件夹,内有4个.txt文件。我在本地测试的时候,就使用了Resource下的四个文本文件。
1、索引保存至文件
(1)、创建索引
先初始化一个IndexModifier对象,然后执行创建索引的核心方法:
地
/// <summary>
/// 给txt文件创建索引
/// </summary>
/// <param name="file"></param>
/// <param name="modifier"></param>
private void IndexFile(FileInfo file, IndexModifier modifier)
{
try
{
Document doc = new Document();//创建文档,给文档添加字段,并把文档添加到索引书写器里
SetOutput("正在建立索引,文件名:" + file.FullName); doc.Add(new Field("id", id.ToString(), Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
id++; /* filename begin */
doc.Add(new Field("filename", file.FullName, Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
//doc.Add(new Field("filename", file.FullName, Field.Store.YES, Field.Index.UN_TOKENIZED));
//doc.Add(new Field("filename", file.FullName, Field.Store.NO, Field.Index.TOKENIZED));
//doc.Add(new Field("filename", file.FullName, Field.Store.NO, Field.Index.UN_TOKENIZED));
/* filename end */ /* contents begin */
//doc.Add(new Field("contents", new StreamReader(file.FullName, System.Text.Encoding.Default))); string contents = string.Empty;
using (TextReader rdr = new StreamReader(file.FullName, System.Text.Encoding.Default))
{
contents = rdr.ReadToEnd();//将文件内容提取出来
doc.Add(new Field("contents", contents, Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
//doc.Add(new Field("contents", contents, Field.Store.NO, Field.Index.TOKENIZED));//不存储索引
}
/* contents end */
modifier.AddDocument(doc);
} catch (FileNotFoundException fnfe)
{
}
}
最后,IndexModifier对象执行Close方法。
几个注意点:
a、IndexModifier类封装了平时经常使用的IndexWriter和IndexReader,而且不用我们额外考虑多线程;
b、StandardAnalyzer是经常使用的一个Analyzer,目前对中文分词支持的也还不错(大名鼎鼎的盘古分词请参考牛人eaglet的这几篇);
c、IndexModifier的Optimize方法的执行可以优化索引文件,但是比较耗时间,根据我的测试,索引文件越大,优化时间线性增加,所以实际的开发中这个方法我们都会按照一定的策略执行;
d、IndexModifier的Close方法必须执行,否则你所做的一切都是无用功。
(2)、按照id删除一条索引
代码相对而言非常简单,直接利用IndexModifier 的DeleteDocuents方法:
Directory directory = FSDirectory.GetDirectory(INDEX_STORE_PATH, false);
IndexModifier modifier = new IndexModifier(directory, new StandardAnalyzer(), false); Term term = new Term("id", id);
modifier.DeleteDocuments(term);//删除
modifier.Close();
directory.Close();
其中,IndexModifier还有一个方法DeleteDocument,它的参数是整数docNum,通常我们也不知道索引文件的内部docNum是多少,所以非常少用它。
(3)、按照id更新一条索引
贴一下主要方法:
bool enableCreate = IsEnableCreated();//是否已经创建索引文件
Term term = new Term("id", id);
Document doc = new Document();
doc = new Document();//创建文档,给文档添加字段,并把文档添加到索引书写器里
doc.Add(new Field("id", id, Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
doc.Add(new Field("filename", filename, Field.Store.YES, Field.Index.TOKENIZED));
doc.Add(new Field("contents", filename, Field.Store.YES, Field.Index.TOKENIZED));
LuceneIO.Directory directory = LuceneIO.FSDirectory.GetDirectory(INDEX_STORE_PATH, enableCreate);
IndexWriter writer = new IndexWriter(directory, new StandardAnalyzer(),IndexWriter.MaxFieldLength.LIMITED);
writer.UpdateDocument(term, doc);
writer.Optimize();
//writer.Commit();
writer.Close();
directory.Close();
需要注意,这一次,我们使用了IndexWriter对象的UpdateDocument方法,而IndexModifier没有找到现成的UpdateDocument方法。Optimize通常需要执行一下,否则索引文件中会有两个相同id的索引。
2、索引保存至内存
如果1你已经理解了,2其实可以不用细究。在IndexModifier的构造函数里有一个重载:
public IndexModifier(Directory directory, Analyzer analyzer, bool create);
下面的示例代码中第一个参数RAMDirectory就是一个Directory,我们可以把它定义成静态,创建索引的时候就完成了保存至内存的效果:
经测试,增删改查原理同1。
3、利用Lucene.Net配合数据库查询
平时开发中,对于数据库中的海量数据,频繁读库可能不能满足效率和速度的需求。我们也可以利用Lucene.Net配合数据库快速查询结果。至于如何对数据库利用Lucene.Net创建索引,增删改查和同1中的介绍是一模一样的。比如本文demo中创建索引的实现,取前1000个人对他们的Id和姓名进行索引。在编码之前,我先往Person表中插入了一些数据:
INSERT Person(FirstName,LastName,Weight,Height) VALUES('明','姚',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('建联','易',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('德科','诺维斯基',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('德怀特','霍华德',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('约什','霍华德',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('蒂姆','邓肯',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('凯文','加内特',,)
INSERT Person(FirstName,LastName,Weight,Height) VALUES('德隆','威廉姆斯',,)
接着先取出1000个人:
string sql = "SELECT TOP 1000 Id,FirstName,LastName FROM Person(NOLOCK)";
IList<Person> listPersons = EntityConvertor.QueryForList<Person>(sql, strSqlConn, null);
然后建立索引即可:
private void IndexDB(IndexModifier modifier,IList<Person> listModels)
{
SetOutput(string.Format("正在建立数据库索引,共{0}人",listModels.Count));
foreach (Person item in listModels)
{
Document doc = new Document();//创建文档,给文档添加字段,并把文档添加到索引书写器里
doc.Add(new Field("id", item.Id.ToString(), Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
doc.Add(new Field("fullname", string.Format("{0} {1}",item.FirstName,item.LastName), Field.Store.YES, Field.Index.TOKENIZED));//存储且索引
modifier.AddDocument(doc);
}
}
同样的道理,最后我们也执行这两个方法(Optimize方法不是一定要做的):
modifier.Optimize();//优化索引
modifier.Close();//关闭索引读写器
三、搜索
本文示例代码中的搜索都是利用Lucene.Net的IndexSearcher默认的比较直接简单的一个搜索方法 Search(Query query, Filter filter, int n),很多重载方法我也没有使用过:
/// <summary>
/// 根据索引搜索
/// </summary>
/// <param name="keyword"></param>
/// <returns></returns>
private TopDocs Search(string keyword,string field)
{
TopDocs docs = null;
int n = ;//最多返回多少个结果
SetOutput(string.Format("正在检索关键字:{0}", keyword));
try
{
QueryParser parser = new QueryParser(field, new StandardAnalyzer());//针对内容查询
Query query = parser.Parse(keyword);//搜索内容 contents (用QueryParser.Parse方法实例化一个查询)
Stopwatch watch = new Stopwatch();
watch.Start();
docs = searcher.Search(query, (Filter)null, n); //获取搜索结果
watch.Stop();
StringBuffer sb = "索引完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒";
SetOutput(sb);
}
catch (Exception ex)
{
SetOutput(ex.Message);
docs = null;
}
return docs;
} /// <summary>
/// 显示搜索结果
/// </summary>
/// <param name="queryResult"></param>
private void ShowFileSearchResult(TopDocs queryResult)
{
if (queryResult == null || queryResult.totalHits == )
{
SetOutput("Sorry,没有搜索到你要的结果。");
return;
} int counter = ;
foreach (ScoreDoc sd in queryResult.scoreDocs)
{
try
{
Document doc = searcher.Doc(sd.doc);
string id = doc.Get("id");//获取id
string fileName = doc.Get("filename");//获取文件名
string contents = doc.Get("contents");//获取文件内容
string result = string.Format("这是第{0}个搜索结果,Id为{1},文件名为:{2},文件内容为:{3}{4}", counter, id, fileName, Environment.NewLine, contents);
SetOutput(result);
}
catch (Exception ex)
{
SetOutput(ex.Message);
}
counter++;
}
}
下一篇我会补充介绍一下Lucene.Net常用的搜索、排序和分页,今天偷懒一下。
最后,本文demo中的代码算不上优美,可读性还凑合,希望大家下载之后看看吧,我还在幻想万一对新手能有所帮助,或者引来某个误入的高手指点一二,于人于己那就真是善莫大焉了。
demo下载:LuceneNetApp
参考:
http://www.cnblogs.com/birdshover/category/152283.html
http://lucene.apache.org/lucene.net/
http://lucene.apache.org/lucene.net/docs/
Lucene.Net无障碍学习和使用:索引篇的更多相关文章
- 【转载】Lucene.Net无障碍学习和使用:搜索篇
在上一篇中,我们初步理解了索引的增删改查基本操作.本文着重介绍一下常用的搜索,以及搜索结果的排序和分页.本文的搜索主要是基于前一篇介绍的文本文件的索引,建议下载最后改进的demo对照着看阅读本文,同时 ...
- Lucene.Net无障碍学习和使用:搜索篇
一.初步认识搜索 先从上一篇示例代码中我们摘录一段代码看看搜索的简单实现: private TopDocs Search(string keyword,string field) { TopDocs ...
- mysql学习【第5篇】:事务索引备份视图
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! mysql学习[第5篇]:事务索引备份视图 MySQL事务 事务就是将一组SQL语句放在同一批次 ...
- Lucene.net入门学习
Lucene.net入门学习(结合盘古分词) Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全 ...
- Lucene.net入门学习系列(2)
Lucene.net入门学习系列(2) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 在使用Luce ...
- Lucene.net入门学习系列(1)
Lucene.net入门学习系列(1) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 这几天在公 ...
- PHP学习笔记之数组篇
摘要:其实PHP中的数组和JavaScript中的数组很相似,就是一系列键值对的集合.... 转载请注明来源:PHP学习笔记之数组篇 一.如何定义数组:在PHP中创建数组主要有两种方式,下面就让我 ...
- Azure IoT Hub和Event Hub相关的技术系列-索引篇
Azure IoT Hub和Event Hub相关的技术系列,最近已经整理了不少了,统一做一个索引链接,置顶. Azure IoT 技术研究系列1-入门篇 Azure IoT 技术研究系列2-设备注册 ...
- mysql学习【第2篇】:MySQL数据管理
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! mysql学习[第2篇]:MySQL数据管理 外键管理 外键概念 如果公共关键字在一个关系中是主 ...
随机推荐
- [ubuntu]对指定区域截图
ctrl+shift 鼠标变成正十字. 按住右键就可以随意截图了. 设置方法: 打开系统设置面板 system settings --> keyboard --> shortcuts - ...
- DOM动态操纵控件案例
点击登陆显示登陆框 <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head ...
- rename 批量重命名
使用背景,对规则文件名批量重命名 例如: Send_Message_20160802_01_log.log Send_Message_20160802_02_log.log Send_Message_ ...
- JavaScript的性能优化:加载和执行
随着 Web2.0 技术的不断推广,越来越多的应用使用 javascript 技术在客户端进行处理,从而使 JavaScript 在浏览器中的性能成为开发者所面临的最重要的可用性问题.而这个问题又因 ...
- jquery多组图片层次切换的焦点图
效果:
- 洛谷2944 [USACO09MAR]地震损失2Earthquake Damage 2
https://www.luogu.org/problem/show?pid=2944 题目描述 Wisconsin has had an earthquake that has struck Far ...
- MyBatis框架的使用及源码分析(十三) ResultSetHandler
在PreparedStatementHandler中的query()方法中,用ResultSetHandler来完成结果集的映射. public <E> List<E> que ...
- Golang向Templates 插入对象的值
Go对象可以插入到template中,然后把对象的值表现在template中,你可以一层层的分解这个对象,去找他的子字段,当前对象用'.'来表示,所以当当前对象是一个string的时候,你可以用{{. ...
- CAS单点登录原理
转自 https://www.cnblogs.com/lihuidu/p/6495247.html 1.基于Cookie的单点登录的回顾 基于Cookie的单点登录核心原理: 将用户名密 ...
- java修饰符——transient
一.背景 上星期去CRM上开发一个功能,该系统里面有自动分页,需要在实体类里加入一个分页变量 // 分页 private PageInfo pageInfo = new PageInfo(); 这个本 ...