合并cookie,提取json数据
发送的第3个请求需要前两个请求的cookie,需要对cookie进行合并
发送的请求数据来自于json数据中的某个键值。
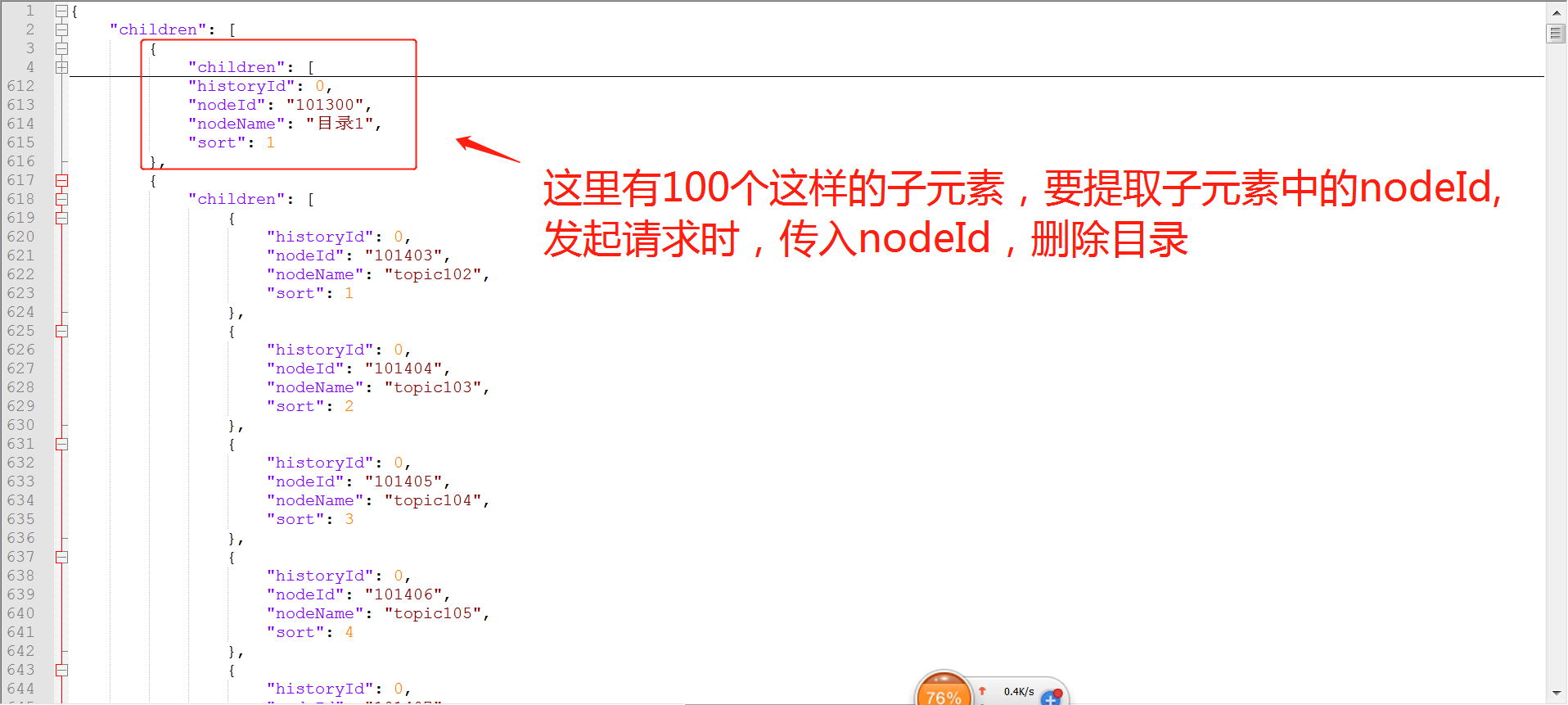
这里是删除所有的对话主题目录,每一个目录有一个id,发起删除对话主题目录的请求时,需要遍历这个目录id, 把目录id作为请求参数传入进去
import requests
import json
Cookie = None
class HttpRequest:
def http_request(self, url, method, data=None, cookie=None):
res = None
try:
if method.upper() == "GET":
res = requests.get(url, data, cookies=cookie)
elif method.upper() == "POST":
res = requests.post(url, data, cookies=cookie)
else:
print("请输入正确参数")
except Exception as e:
print("请求报错了:{}".format(e))
raise e
return res
def get_dir(file, key, sub_key):
# 提取json数据的所有nodeId
# 需要编码,不然可能会报错
with open(file, "r", encoding="utf-8") as f:
json_str = f.read()
data = json.loads(json_str)
dir_list = []
for sub_dic in data[key]:
dir_id = sub_dic[sub_key]
dir_list.append(dir_id)
return dir_list
if __name__ == '__main__':
# 登录
login_url = "http://chat.rainbowred.com/login"
login_data = {"username": "15546355872",
"password": "123456",
"rememberCheck": "1",
"loginStatus": "1",
"rememberStatus": "1",
"autoLogin": "0",
"language": "zh"}
login_res = HttpRequest().http_request(login_url, "post", login_data)
print(login_res.json())
Cookie = login_res.cookies
print("登录后的cookie", Cookie)
# 选择公司
c_url = "http://chat.rainbowred.com/chc"
c_data = {"companyId": "1364"}
c_res = HttpRequest().http_request(c_url, "post", c_data, cookie=Cookie)
print(c_res.json())
print("选择公司后的cookie", c_res.cookies)
# 合并两次接口请求的cookie
Cookie = dict(Cookie, **c_res.cookies)
print("选择公司后的cookie2", Cookie)
file = r"C:\Users\acer-pc\Desktop\8_.json"
key = "children"
sub_key = "nodeId"
d_url = "http://tprofile.rainbowred.com/ctm/delete"
d_data = get_dir(file, key, sub_key)
send_data = {}
# 提取json数据
for data in d_data:
print(data)
send_data["nodeId"] = data
d_res = HttpRequest().http_request(d_url, "post", send_data, Cookie)
print(d_res.json())
如何获取json列表:
首先更新对话主题
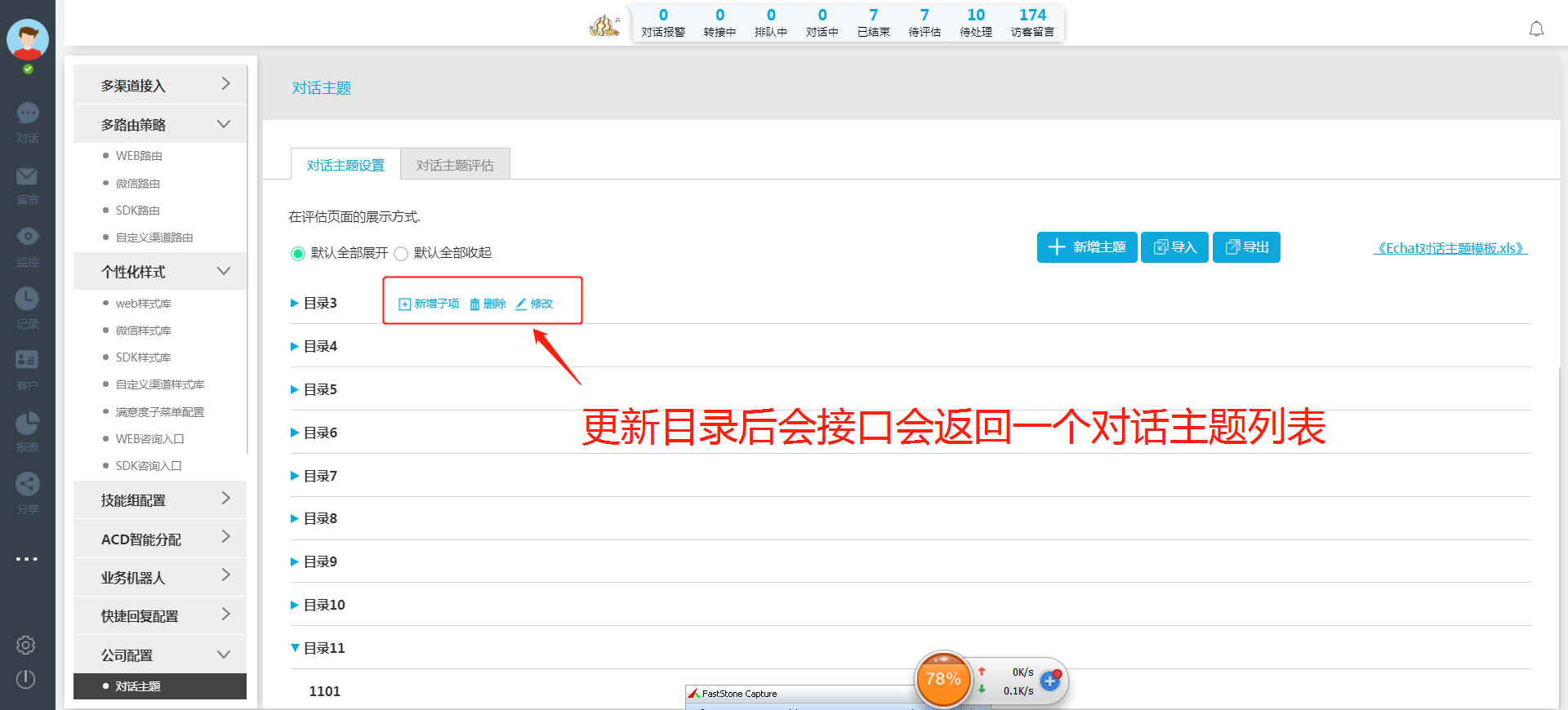
抓取删除接口的请求参数:可以看到需要nodeId
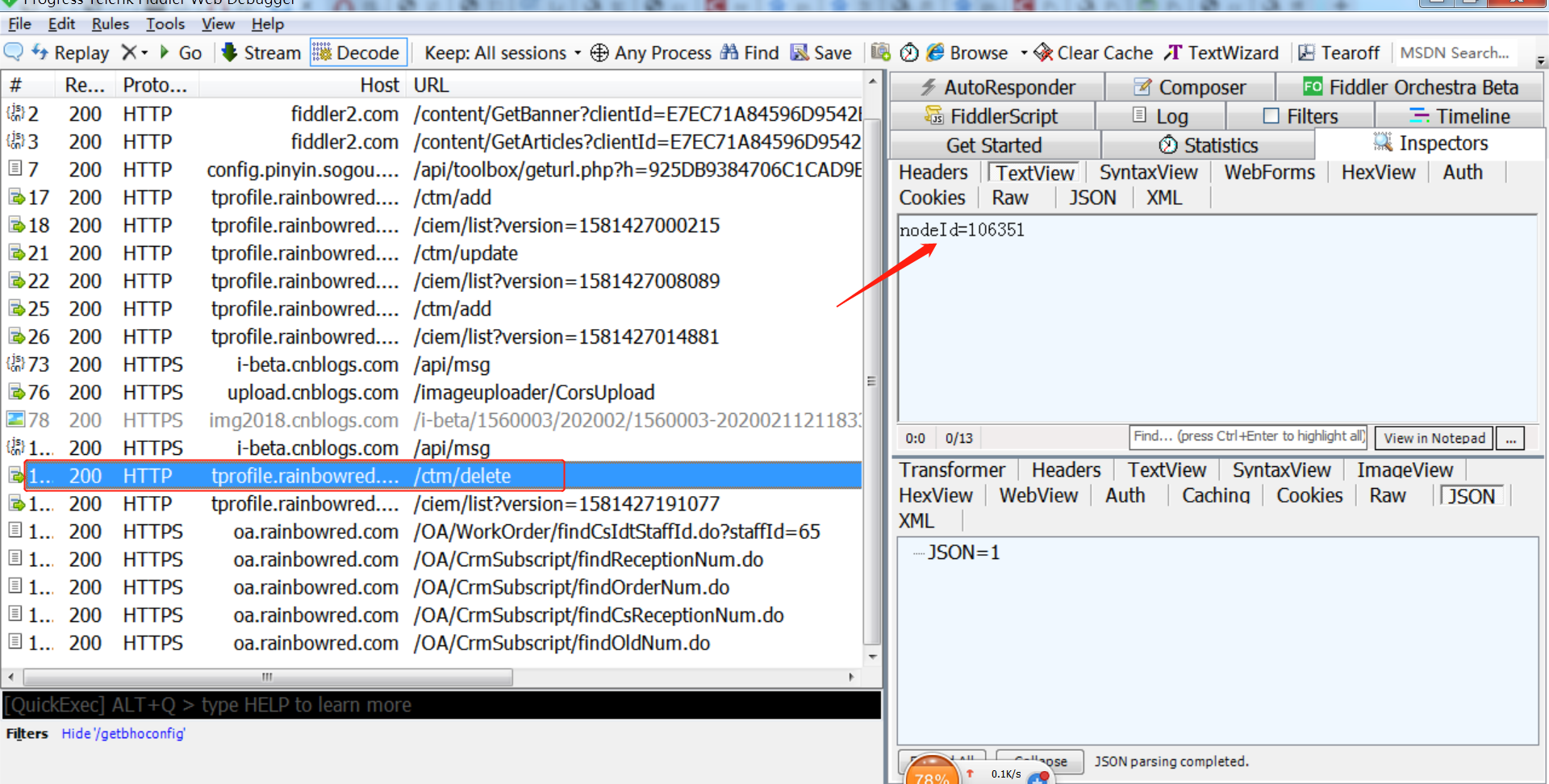
更新对话主题后会更新对话主题版本,请求所有的对话主题列表
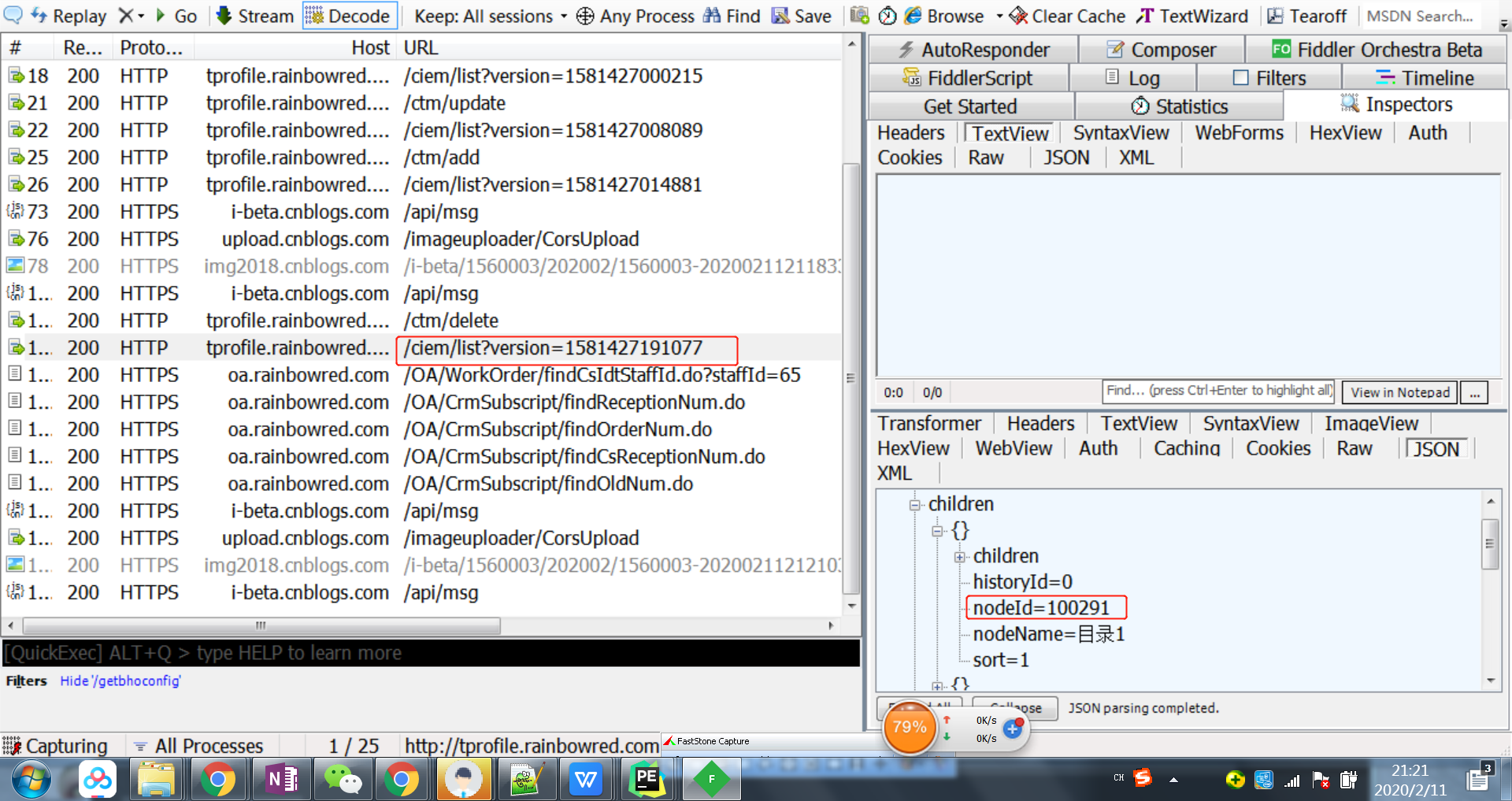
选中接口请求,右键可以保存响应body到本地,便于分析数据结构,看看应该如何获取所有的nodeId
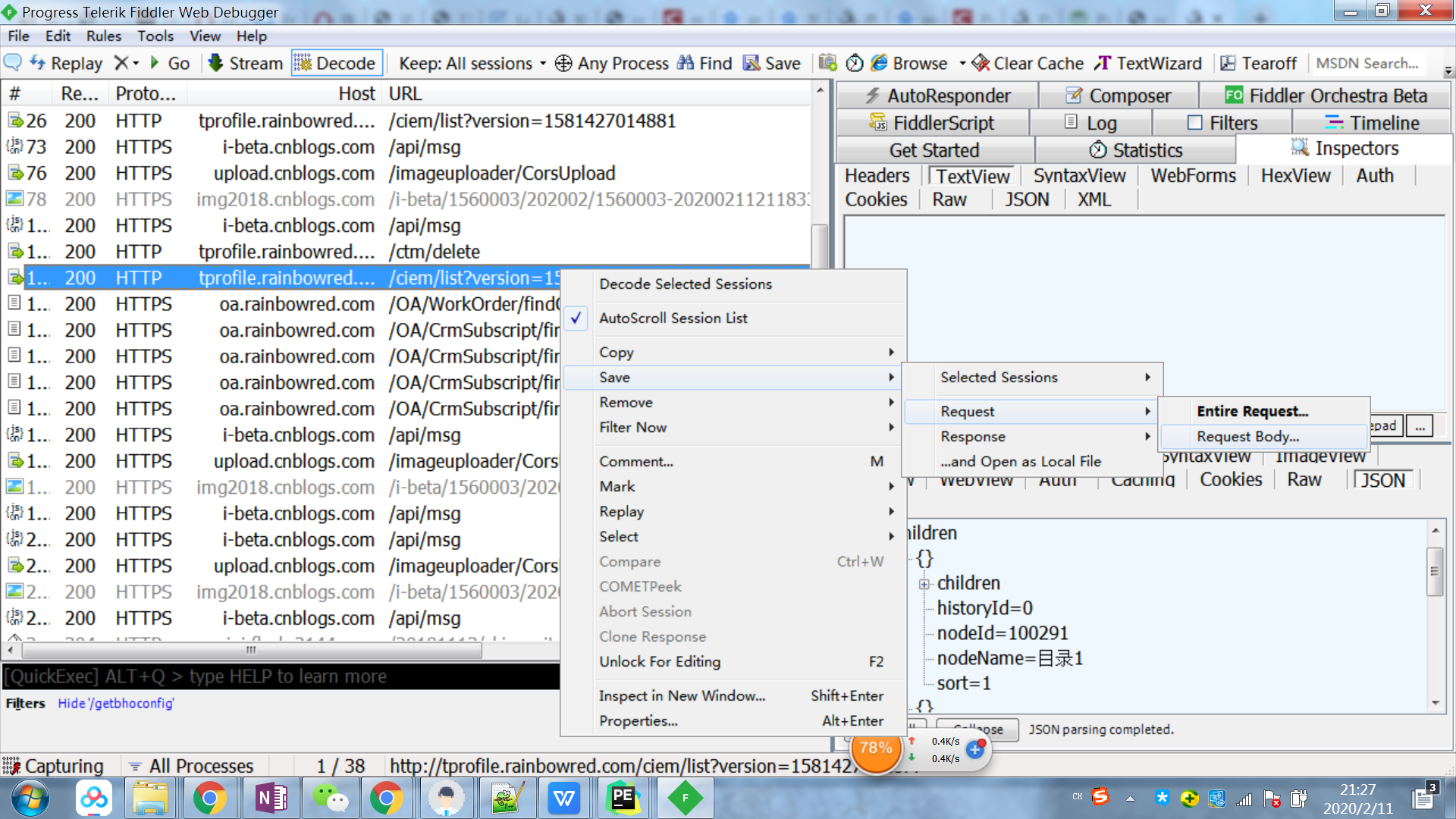
json数据如图
合并cookie,提取json数据的更多相关文章
- jmeter之beanshell提取json数据
Jmeter BeanShell PostProcessor提取json数据 假设现有需求: 提取sample返回json数据中所有name字段对应的值,返回的json格式如下: {“body”:{“ ...
- Jmeter BeanShell PostProcessor提取json数据
需求:提取sample返回json数据中所有name字段值,返回的json格式如下: {“body”:{“apps”:[{“name”:”111”},{“name”:”222”}]}} jmeter中 ...
- 自动化测试 如何快速提取Json数据
Json作为一种轻量级的交换数据形式,由于其自身的一些优良特性比如包含有效信息多,易于阅读和解析. 使用Json的场景也很多,比如读取解析系列化的Json格式的数据,我们需要将一个Json的字符串解析 ...
- js提取JSON数据中需要的那部分数据
var data =[ { name: "程咬金",sex:"1",age:26 }, { name: "程才",sex:"0&q ...
- 利用es6解构赋值快速提取JSON数据;
直接上代码 { let JSONData = { title:'abc', test:[ { nums:5, name:'jobs' }, { nums:11, name:'bill' } ] } l ...
- 爬虫json数据的处理
在爬网页的过程中,最喜欢遇到的就是json数据接口,省了不少麻烦,但是json数据也有多种格式. 类型一:标准的json result = json.loads(html.text),将str转成py ...
- (数据科学学习手札125)在Python中操纵json数据的最佳方式
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常使用Python的过程中,我们经常会 ...
- ASP.NET提取多层嵌套json数据的方法
本文实例讲述了ASP.NET利用第三方类库Newtonsoft.Json提取多层嵌套json数据的方法,具体例子如下. 假设需要提取的json字符串如下: {"name":&quo ...
- 服务器端json数据文件分割合并解决方案
问题引入 Json 是什么就不多说了,本文把Json理解成一种协议. 印象之中,Json貌似是前端的专属,其实不然,服务器端组织数据,依然可以用Json协议. 比如说,某公司有一套测评题目(基于Jso ...
随机推荐
- 谈谈 Act 的依赖注入 和 模板输出 - 回答 drinkjava 同学提问
1. 背景 依赖注入工具 jBeanBox 的作者 drinkjava 同学最近在 Actframework gitee 项目 的提出了如下评论: 你这个DI工具的出发点可能有问题,一个MVC工具为什 ...
- java生成6位数所有组合
for(int i=0;i<=9;i++){ String str=""; str=str+i; String strj=""; for(int j=0; ...
- 实体机安装Ubuntu系统
今天windows突然蓝屏了,索性安装个 Ubuntu 吧,这次就总结一下实体机安装 Ubuntu 的具体步骤 note: 本人实体机为笔记本 型号为:小米pro U盘为金士顿:8G 安装系统:Ubu ...
- GitHub 中 readme 如何添加图片
一.Readme 是什么 readme文件一般是放在github 每个repo的根目录下,用来解释.说明本repo的主要内容和相关信息.而且在repo主页进去的时候会被自动加载.一般采用md标记的文本 ...
- Excel文件比较工具的使用
本工具用于比较两个文件夹中对应Excel工作簿中单元格数据是否不同. 如果有内容不同的单元格,就在结果报告中表示出来. 点击如下链接,下载. Excel文件比较工具.rar 解压缩后,看到1个exe文 ...
- Windows、Linux(Ubuntu)修改 pip 镜像源
一.Windows 修改 pip 镜像源 1.win + R 打开运行,输入 %APPDATA% 2.按下回车,打开文件夹. 3.在该文件夹下,新建文件夹,命名 pip. 4.进入 pip 文件夹, ...
- dubbo使用Spring配置暴露服务和使用Spring配置引用远程服务
提供者: <!-- 1.指定当前服务/应用的名字(同样的服务名字相同,不要和别的服务同名) --> <dubbo:application name="user-servic ...
- 机器学习总结(参考源码ml.hpp)
依据机器学习算法如何学习数据可分为3类: 有监督学习:从有标签的数据学习,得到模型参数,对测试数据正确分类: 无监督学习:没有标签,计算机自己寻找输入数据可能的模型: 强化学习(reinforceme ...
- 2019-2020-1 20199324《Linux内核原理与分析》第六周作业
第五章 系统调用的三层机制(下) 1.给MenuOS增加命令 进入Linuxkernel目录下,强制删除当前menu目录,再重新克隆一个新版本的menu 进入menu,运行make roofts脚本就 ...
- mybatis分页插件PageHelper简单应用
--添加依赖 <!-- https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper --><depende ...