使用pandas筛选出指定列值所对应的行
在pandas中怎么样实现类似mysql查找语句的功能:
select * from table where column_name = some_value;
pandas中获取数据的有以下几种方法:
- 布尔索引
- 位置索引
- 标签索引
- 使用API
假设数据如下:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})

布尔索引
该方法其实就是找出每一行中符合条件的真值(true value),如找出列A中所有值等于foo
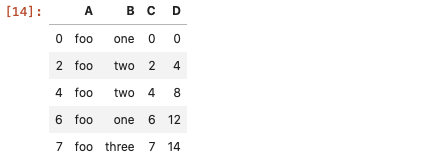
df[df['A'] == 'foo'] # 判断等式是否成立
位置索引
使用iloc方法,根据索引的位置来查找数据的。这个例子需要先找出符合条件的行所在位置
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask) # 返回的是array([0, 2, 4, 6, 7])
df.iloc[pos]
#常见的iloc用法
df.iloc[:3,1:3]

标签索引
如何DataFrame的行列都是有标签的,那么使用loc方法就非常合适了。
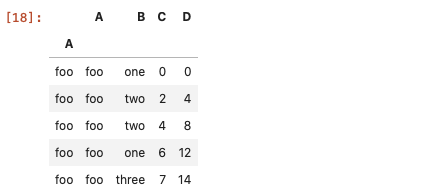
df.set_index('A', append=True, drop=False).xs('foo', level=1) # xs方法适用于多重索引DataFrame的数据筛选
# 更直观点的做法
df.index=df['A'] # 将A列作为DataFrame的行索引
df.loc['foo', :]
# 使用布尔
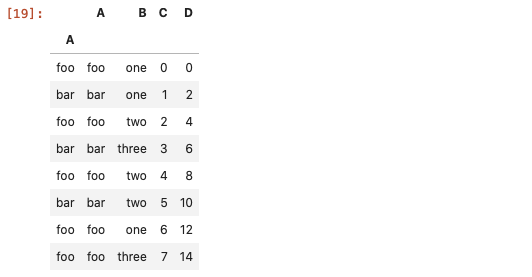
df.loc[df['A']=='foo']
使用API
pd.DataFrame.query方法在数据量大的时候,效率比常规的方法更高效。
df.query('A=="foo"')
# 多条件
df.query('A=="foo" | A=="bar"')
数据提取不止前面提到的情况,第一个答案就给出了以下几种常见情况:
1、筛选出列值等于标量的行,用==
df.loc[df['column_name'] == some_value]
2、筛选出列值属于某个范围内的行,用isin
df.loc[df['column_name'].isin(some_values)] # some_values是可迭代对象
3、多种条件限制时使用&,&的优先级高于>=或<=,所以要注意括号的使用
df.loc[(df['column_name'] >= A) & (df['column_name'] <= B)]
4、筛选出列值不等于某个/些值的行
df.loc[df['column_name'] != 'some_value']
df.loc[~df['column_name'].isin('some_values')] #~取反
如果你觉得我的文章还可以,可以关注我的微信公众号,查看更多实战文章:Python爬虫实战之路
也可以扫描下面二维码,添加我的微信公众号

使用pandas筛选出指定列值所对应的行的更多相关文章
- 【452】pandas筛选出表中满足另一个表所有条件的数据
参考:pandas筛选出表中满足另一个表所有条件的数据 参考:pandas:匹配两个dataframe 使用 pd.merge 来实现 on 表示查询的 columns,如果都有 id,那么这是很好的 ...
- jquery实现对象数组 筛选出每条记录中的特定属性字段 及根据某个属性值筛选出指定的元素
jquery实现对象数组 筛选出每条记录中的特定属性字段 直接上图: 源码: /** * 对后端返回的数据,筛选出符合报表的列项,多余的列项去除 */ function filterParams(da ...
- 如何从两个List中筛选出相同的值
问题 现有社保卡和身份证若干,想要匹配筛选出一一对应的社保卡和身份证. 转换为List socialList,和List idList,从二者中找出匹配的社保卡. 模型 创建社保卡类 /** * @a ...
- Pandas 删除指定列中为NaN的行
定位要删除的行 需求:删除指定列中NaN所在行. 如下图,’open‘ 列中有一行为NaN,定位到它,然后删除. 定位: df[np.isnan(df['open'])].index # 这样即可定位 ...
- pandas 如何判断指定列是否(全部)为NaN(空值)
判断某列是否有NaN df['$open'].isnull().any() # 判断open这一列列是否有 NaN 判断某列是否全部为NaN df['$open'].isnull().all() # ...
- pandas 筛选某一列最大值最小值 sort_values、groupby、max、min
高效方法: dfs[dfs['delta'].isnull()==False].sort_values(by='delta', ascending=True).groupby('Call_Number ...
- ext js 4.0 grid表格根据列值的不同给行设置不同的背景颜色
Code: Ext.create('Ext.grid.Panel', { ... viewConfig: { getRowClass: function(record) { return record ...
- pandas神坑:如果列有NAN,则默认给数据转换为float类型!给pandas列指定不同的数据类型。
今天碰到一个错误,一个字典取值报keyError, 一查看key, 字符串类型的数字后面多了小数点0, 变成了float的样子了. 发现了pandas一个坑:如果列有NAN,则默认给数据转换为floa ...
- Pandas 筛选操作
# 导入相关库 import numpy as np import pandas as pd 在数据处理过程中,经常会遇到要筛选不同要求的数据.通过 Pandas 可以轻松时间,这一篇我们来看下如何使 ...
随机推荐
- LeetCode——735.行星碰撞
给定一个整数数组 asteroids,表示在同一行的行星. 对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动).每一颗行星以相同的速度移动. 找出 ...
- 使用mha 构建mysql高可用碰到几个问题
根据网上配置,安装好mha ,建议到https://code.google.com/archive/p/mysql-master-ha/downloads 下载0.56版本 1.首先先确定各个主机之 ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- 吴裕雄--天生自然 PYTHON3开发学习:条件控制
if condition_1: statement_block_1 elif condition_2: statement_block_2 else: statement_block_3 var1 = ...
- LGOJ1861 星之器
前置扯淡 我对这个题目的评价和网上各位大佬的一样:人类智慧题 (显然我不具有人类智慧--) Description link 现在有一个 \(n \times m\) 的矩阵\(A\),里面的每个元素 ...
- APUE 书中 toll 函数
今天看unix环境高级编程时,随着书上的源码打了一遍,编译时提示 toll函数未定义, 找了半天(恕我对上下文不了解).看了英文版和源代码文件才知道, 中文版打印错了: toll => atol ...
- javascript 的七种基本数据类型
六种基本数据类型 undefined null string boolean number symbol(ES6) 一种引用类型 Object 为什么要引入 Symbol? ES5的对象中的属性名是字 ...
- MFC修改系统托盘的图标
最近开始学习MFC,发现程序在任务栏,窗口和exe都使用的默认图标,那么,我们想使用自己的图标该如何做? 第一种方法: 1.我们将自己要使用的icon的图标导入项目中. 资源视图-->xx.rc ...
- Super Mario HDU - 4417 (主席树询问区间比k小的个数)
Mario is world-famous plumber. His “burly” figure and amazing jumping ability reminded in our memory ...
- 对xgboost中dump_model生成的booster进行解析
xgboost原生包中有一个dump_model方法,这个方法能帮助我们看到基分类器的决策树如何选择特征进行分裂节点的,使用的基分类器有两个特点: 二叉树: 特征可以重复选择,来切分当前节点所含的数据 ...