MySQL--InnoDB 关键特性
插入缓冲
Insert Buffer
对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个 Insert Buffer 对象中。
Insert Buffer 的使用需要同时满足以下两个条件:
索引是辅助索引
索引不是唯一的
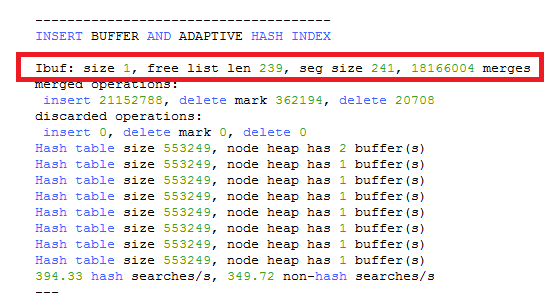
size: The number of pages used within the change buffer. Change buffer size is equal to seg size - (1 + free list len). The 1 + value represents the change buffer header page.
Change Buffer
InnoDB 从 1.0.x 版本开始导入了 Change Buffer,可将其视为 Insert Buffer 的升级。从这个版本开始,InnoDB 存储引擎可以对 DML 操作都进行缓冲,他们分别是 Insert Buffer、Delete Buffer、Purge Buffer。
Change Buffer 使用的对象时非唯一的辅助索引。
对一条记录进行 UPDATE 操作可能分为两个过程:
将记录标记为已删除
真正的将记录删除
Delete Buffer 对应 UPDATE 操作的第一个过程,即将记录标记为删除。
Purge Buffer 对应 UPDATE 操作的第二个过程,即将记录真正的删除。
innodb_change_buffering // 开启 buffer 的选项 [inserts|deletes|purges|changes|all|none] 默认为 all。
innodb_change_buffer_max_size // 控制 Change Buffer 最大使用内存的数量,默认值是 25,最大有效值为 50(使用缓冲池内存空间百分比)

两次写
在应用重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是 Double Write。
double write 由两部分组成,一部分是内存中的 double write buffer,大小为 2MB,另一部分是物理磁盘上共享表空间中连续的 128 个页,即 2 个区,大小同样为 2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过 memcpy 函数将脏页复制到内存中的 double write buffer,之后通过 double write buffer 再分两次,每次 1MB 顺序地写入表空间的物理磁盘上,然后马上调用 fsync 函数,同步磁盘,避免缓冲写带来的问题。
可以通过以下命令观察到 double write 运行的情况:
show global status like 'innodb_dblwr%';
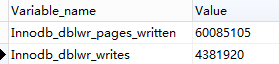
如果发现系统在高峰时的 Innodb_dblwr_pages_written : Innodb_dblwr_writes 远小于 64 : 1,那么可以说明系统写入的压力并不是很高。
如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB 存储引擎可以从共享表空间中的 double write 中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。
show global status like 'innodb_buffer_pool_pages_flushed'; 当前从缓冲池中刷新到磁盘页的数量。该变量应该和 Innodb_dblwr_pages_written 一致。
自适应哈希索引
InnoDB 存储引擎会监控对表上各索引页的查询。如果观察到建立哈希索引可以带来速度提升,则建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。AHI 是通过缓冲池的 B+ 树页构造而来,因此建立的速度很快,而且不需要对整张表构件哈希索引。InnoDB 存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
哈希索引是数据库自优化的,无需人为调整。
哈希索引只能用来进行搜索等值的查询。
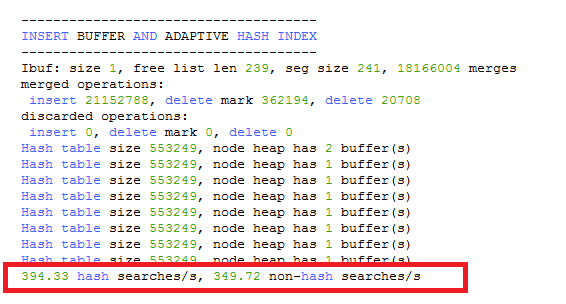
hash searches : non-hash searches 可以大概了解使用哈希索引后的效率。
AHI 默认为开启状态,用户可以通过 innodb_adaptive_hash_index 来禁用启用此特性。
异步 IO
为了提高磁盘操作性能,当前的数据库系统都采用异步 IO(Asynchronous IO,AIO)的方式来处理磁盘操作。InnoDB 存储引擎亦是如此。
AIO 可以进行 IO Merge 操作。
innodb_use_native_aio 控制是否启用 Native AIO。在 Linux 操作系统下默认为 ON。
在 InnoDB 存储引擎中,read ahead 方式的读取都是通过 AIO 完成,脏页的刷新,即磁盘的写入操作则全部由 AIO 完成。
刷新邻近页
当刷新一个脏页时,InnoDB 存储引擎会检测该页所在区的所有页,如果是脏页,那么一起刷新。这样做的好处显而易见,通过 AIO 可以将多个 IO 写入造作合并为一个 IO 操作,故该工作机制在传统磁盘下有着显著的优势。但是需要考虑到下面两个问题:
是不是可能将不怎么脏的页进行写入,而该页之后又很快变成脏页
固态硬盘有着较高的 IOPS,是否还需要这个特性
innodb_flush_neighbors 控制是否启用刷新邻近页特性。
对于传统机械硬盘建议启用该特性,而对于固态硬盘有着超高的 IOPS 性能的磁盘,则建议将该参数设置为 0,即关闭此特性。
MySQL--InnoDB 关键特性的更多相关文章
- Mysql InnoDB三大特性-- change buffer
Mysql InnoDB三大特性-- change buffer
- Mysql InnoDB三大特性-- 自适应hash index
Mysql InnoDB三大特性-- 自适应hash index
- InnoDB关键特性学习笔记
插入缓存 Insert Buffer Insert Buffer是InnoDB存储引擎关键特性中最令人激动与兴奋的一个功能.不过这个名字可能会让人认为插入缓冲是缓冲池中的一个组成部分.其实不然,Inn ...
- innodb关键特性之double write
# 脏页刷盘的风险 两次写的原理机制 1.解决问题 2.使用场景 3.doublewrite的工作流程 4.崩溃恢复 # doublewrite的副作用 1.监控doublewrite负载 2.关闭d ...
- Mysql InnoDB三大特性-- double write
转自:http://www.ywnds.com/?p=8334 一.经典Partial page write问题? 介绍double write之前我们有必要了解partial page write( ...
- InnoDB关键特性之刷新邻接页-异步IO
Flush neighbor page 1.工作原理 2.参数控制 AIO 1.开启异步IO 一.刷新邻接页功能 1.工作原理 当刷新一个脏页时,innodb存储引擎会检测该页所在区(extent)的 ...
- InnoDB关键特性之insert buffer
insert buffer 是InnoDB存储引擎所独有的功能.通过insert buffer,InnoDB存储引擎可以大幅度提高数据库中非唯一辅助索引的插入性能. 数据库对于自增主键值的插入是顺序的 ...
- InnoDB关键特性之change buffer
一.关于IOT:索引组织表 表在存储的时候按照主键排序进行存储,同时在主键上建立一棵树,这样就形成了一个索引组织表,一个表的存储方式以索引的方式来组织存储的. 所以,MySQL表一定要加上主键,通过主 ...
- InnoDB关键特性之自适应hash索引
一.索引的资源消耗分析 1.索引三大特点 1.小:只在一个到多个列建立索引 2.有序:可以快速定位终点 3.有棵树:可以定位起点,树高一般小于等于3 2.索引的资源消耗点 1.树的高度,顺序访问索引的 ...
- innodb 关键特性(insert buffer)
一.insert buffer 性能改善 insert buffer和数据页一样,也是物理页的一个组成部分. 在innodb存储引擎中,主键是行唯一的标识符.通常应用程序中行记录的插入顺序是按照主键递 ...
随机推荐
- UVA - 10635 Prince and Princess(LCS,可转化为LIS)
题意:有两个长度分别为p+1和q+1的序列,每个序列中的各个元素互不相同,且都是1~n2的整数.两个序列的第一个元素均为1.求出A和B的最长公共子序列长度. 分析: A = {1,7,5,4,8,3, ...
- POJ 3061:Subsequence 查找连续的几个数,使得这几个数的和大于给定的S
Subsequence Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10172 Accepted: 4160 Desc ...
- 官网英文版学习——RabbitMQ学习笔记(九)总结
RabbitMQ与spingboot相整合,主要步骤也很简单: 一.首先需要的是添加依赖 二.需要设置属性,属性主要是设置rabbitmq的地址端口,用户名密码回调等需要用到的一些常量,在整合过程中, ...
- PlayJava SpringMVC与Struts2杂谈
一 先做一个简单对比: 1. SpringMVC的入口是Servlet,核心是DispatcherServlet,Struts2是Filter,核心是FilterDispatcher 2. Sprin ...
- C# 借助CommandLine 写命令行工具 在数据库中创建job
首先需要用到 CommandLine.dll 提供两个下载链接,云盘是我自己上传的,也就是我在用的 http://commandline.codeplex.com/ https://pan.baid ...
- 对 TD tree 的使用体验
经过这几天对学长们的作品的应用,感触颇多,忍不住写写随笔. 先谈一下,最初的感受吧,那天下午观看,体验学长学姐们的作品时,感觉他们太厉害了,只比我们多学一年,就已经可以做出手机 app ,和 网页了. ...
- tensorflow--建立一个简单的小网络
In [19]: import tensorflow as tf import numpy as np # #简单的数据形网络 # #定义输入参数 # X=tf.constant( ...
- Struts1 的配置文件总结
一.在web.xml中安装Struts 要想使用Struts,我们接触到的第一个配置文件就是web.xml.实际上,Struts的入口点是一个名为ActionServlet的Servlet.在第一次访 ...
- Canvas基本定义
Android中使用图形处理引擎,2D部分是android SDK内部自己提供,3D部分是用Open GL ES 1.0.今天我们主要要了解的是2D相关的 大部分2D使用的api都在android.g ...
- C# 添加Log文件、记录Log
其实在平时的开发过程中都是不怎么写log的,觉得在debug中能看得一清二楚.同事小姐姐前辈,一直就我不写log进行批判,但是我从来不改,哈哈.也算是遇到报应了,在最近一个工程里,本地调试一切正常,到 ...