14-jmeter分布式环境
1、分布式概念:
jmeter做性能时,会消耗本地机器资源
本机无法没有限制的创建运行线程(一般500线程就差不多会报错)
一般这时候会用到分布式的环境
2、环境:
前提条件:环境一致(有时候可以直接压缩jmeter的包放到其他机器上,但是环境还是重新配置检查一下)
主机,slave机器:jmeter版本一致,jdk版本一致,jmeter的数据文件csv一致,插件及版本一致,有时候遇到内外网时(网段也要一致),端口,防火墙等
具体搭建:
1、将主机jmeter压缩后的包上传至其他slave机器内
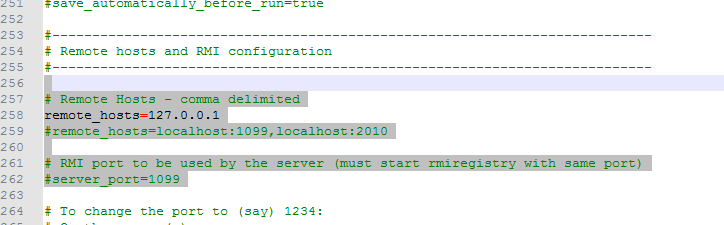
2、slave机器:在jmeter/bin/jmeter.properties文件内修改配置:
搜索:sever_port,修改端口 (可新增写一个,不覆盖原来的,原来的本来已经是注释了的)
搜索:sever.rmi.port,修改端口 (可新增写一个,不覆盖原来的,原来的本来已经是注释了的)
搜索:修改sever.rmi.ssl.disable=true (默认是false)
--------------------------------------------------------------------端口:主机,slave机器的端口号要保持一致


3、启动服务:启动slave机器jmeter的服务
启动时,先指定一下ip(这里的ip为当前slave机器的ip,cmd查看一下就好)
指定ip:jmeter-sever.bat -Djava.rmi.sever.hostname=当前slave机器的ip
4、检查防火墙等是否关闭
slave机器的防火墙,不然主机,slave机器无法互相连接(端口被阻止未开放)
5、在主机上cmd:telnet slave机器的ip 端口
会出现可连通状态。
6、主机:再在jmeter/bin/jmeter.properties文件内修改配置:
第一:remote_host=slave机器的ip:端口号,ip:端口号------------多个就以英文逗号隔开写进去就行了

第二:修改为true

第三:去掉注释,此时主机运行控制时,可以看得见运行日志。

7、配置完成后,运行jmeter主机,可见如下ip入口(即主机可控制slave机器运行)

可能存在的问题:
1、网络连接不同(主机和slave机器):telnet ip 端口
2、缺少rmi.keystore.jks :去掉rmi认证---------看上面的步骤
3、主机和slave机器无法互通:重新指定一下ip和端口
14-jmeter分布式环境的更多相关文章
- jmeter分布式环境
搭建jmeter分布式环境 (1)确定分布式结构,即1台机器部署master.几台机器部署slave? (2)将相同版本的jmeter分别拷贝到这几台机器 (3)修改maste ...
- JMeter分布式测试环境搭建(禁用SSL)
JMeter分布式环境,一台Master,一到多台Slave,Master和Slave可以是同一台机器. 前提条件: 所有机器,包括master和slave的机器: 1.运行相同版本的JMeter 2 ...
- Ubuntu 14.04 (32位)上搭建Hadoop 2.5.1单机和伪分布式环境
引言 一直用的Ubuntu 32位系统(准备下次用Fedora,Ubuntu越来越不适合学习了),今天准备学习一下Hadoop,结果下载Apache官网上发布的最新的封装好的2.5.1版,配置完了根本 ...
- JMeter分布式执行环境的搭建 ( 使用基于SSL的RMI的有效密钥库 )
JMeter分布式执行环境的搭建 ( 使用基于SSL的RMI的有效密钥库 ) 在上一篇的基础之上,提供一个简单的例子: Master和Slave不是同一台,采用默认端口 Master:10.86.16 ...
- Windows和Linux的Jmeter分布式集群压力测试
Windows的Jmeter分布式集群压力测试 原文:https://blog.csdn.net/cyjs1988/article/details/80267475 在使用Jmeter进行性能测试时, ...
- Jmeter分布式测试实战
一.Jmeter分布式测试基础 1.Jmeter分布式测试原因: 在使用Jmeter进行接口的性能测试时,由于Jmeter 是JAVA应用,对负载机的CPU和内存消耗比较大.所以当需要模拟数以万计的并 ...
- jmeter分布式操作-远程启动功能探索
一.背景: 之前在Jmeter插件监控服务器性能一篇中说到,在非GUI环境中监控时为了保存监控数据需要修改jmeter脚本,并且每次通过施压机(远程服务器,非GUI环境)来压测时都要将jmeter脚本 ...
- Flume+Kafka+Strom基于伪分布式环境的结合使用
目录: 一.Flume.Kafka.Storm是什么,如何安装? 二.Flume.Kafka.Storm如何结合使用? 1) 原理是什么? 2) Flume和Kafka的整合 3) Kafka和St ...
- linux环境下的伪分布式环境搭建
本文的配置环境是VMware10+centos2.5. 在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验. 如果感觉有问题,欢迎咨询评论. 一:伪 ...
- 分布式环境下限流方案的实现redis RateLimiter Guava,Token Bucket, Leaky Bucket
业务背景介绍 对于web应用的限流,光看标题,似乎过于抽象,难以理解,那我们还是以具体的某一个应用场景来引入这个话题吧. 在日常生活中,我们肯定收到过不少不少这样的短信,“双11约吗?,千款….”,“ ...
随机推荐
- JavaScript数组排序(冒泡排序、选择排序、桶排序、快速排序)
* 以下均是以实现数组的从小到大排序为例 1.冒泡排序 先遍历数组,让相邻的两个元素进行两两比较 .如果要求小到大排:最大的应该在最后面,如果前面的比后面的大,就要换位置: 数组遍历一遍以后,也就是第 ...
- SSM整合搭建(二)
本页来衔接上一页继续来搭建SSM,再提一下大家如果不详细可以再去看视频哦,B站就有 之后我们来配置SpringMVC的配置文件,主要是配置跳转的逻辑 先扫描所有的业务逻辑组件 我们要用SpringMV ...
- 039.集群网络-Pod和SVC网络实践
一 Pod和SVC网络 1.1 实践准备及原理 Docker实现了不同的网络模式,Kubernetes也以一种不同的方式来解决这些网络模式的挑战.本完整实验深入剖析Kubernetes在网络层是如何实 ...
- Natas16 Writeup(正则匹配,php命令执行)
Natas16: 源码如下 <? $key = ""; if(array_key_exists("needle", $_REQUEST)) { $key ...
- Python实现一个ORM模型类
ORM是三个单词首字母组合而成,包含了Object(对象-类),Relations(关系),Mapping(映射).解释过字面意思,但ORM的概念仍然模糊.私以为要理解一个事物,最好的法子是搞明白它出 ...
- 题解 P3205 【[HNOI2010]合唱队】
讲讲我的做法 看了题目发现要用区间\(dp\),为什么? 我们发现区间\(dp\)有一个性质--大区间包涵小区间,这道题就符合这样的一个性质 所以我们要用区间\(dp\)来解决这道题. 如何设计状态 ...
- OpenCV-Python 理解特征 | 三十六
目标 在本章中,我们将尝试理解什么是特征,为什么拐角重要等等 解释 你们大多数人都会玩拼图游戏.你会得到很多小图像,需要正确组装它们以形成大的真实图像.问题是,你怎么做?将相同的理论投影到计算机程序上 ...
- 9.Maven的生命周期
Clean Lifecycle: 在进行真正的构建之前进行一些清理工作. Default Lifecycle :构建的核心部分,编译,测试,打包,部署等等. Site Lifecycle : 生成项目 ...
- jQuery学习笔记01
1.jQuery介绍 1.1什么是jQuery ? jQuery,顾名思义,也就是JavaScript和查询(Query),它就是辅助JavaScript开发的js类库. 1.2 jQuery核心思想 ...
- 发现钉钉打卡定位算法的一个bug
最近公司取消了指纹打卡,改用钉钉打卡. 天天用这个打卡上班,经常忘记,困扰. 最烦的是好几次明明人在办公室,打卡地址显示在10分钟前的位置,定位失败,不得不重新打卡. 经历过几次定位失败后,我就琢磨起 ...