Java实现DFS深度优先查找
1 问题描述
深度优先查找(depth-first search,DFS)可以从任意顶点开始访问图的顶点,然后把该顶点标记为已访问。在每次迭代的时候,该算法紧接着处理与当前顶点邻接的未访问顶点。这个过程一直持续,直到遇到一个终点——该顶点的所有邻接顶点都已被访问过。在该终点上,该算法沿着来路后退一条边,并试着继续从那里访问未访问的顶点。再后退到起始顶点上,并且起始顶点也是一个终点时,该算法最终停了下来。这样,起始顶点所在的连通分量的所有顶点都被访问过了。如果,未访问过的顶点仍然存在,该算法必须从其中任一点开始,重复上述过程。
总之,记住一句话,深度优先查找就是先尽可能达到当前遍历路径能够达到最长的路径,一旦达到该路径终点,再回溯,从原来已遍历过顶点(PS:该顶点包含多个分支路径)处开始新的分支路径遍历。
2 解决方案
2.1 蛮力法
此处借用算法设计与分析基础(第三版)上一段概念介绍,及说明图形介绍其具体遍历过程,下面的具体代码使用数据就是下图中相关数据。

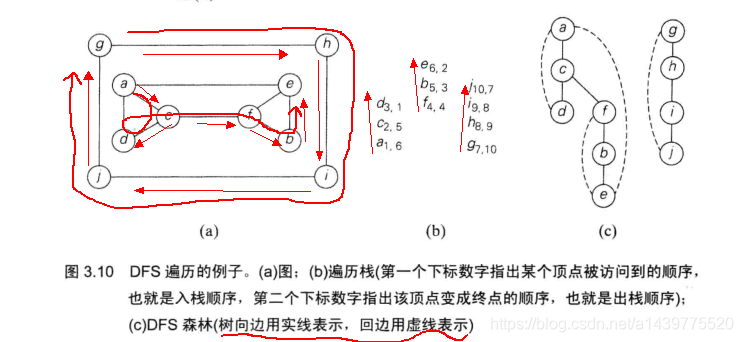
package com.liuzhen.chapterThree;
public class DepthFirstSearch {
public int count = 0; //用于计算遍历总次数
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历
* result用于存放深度优先遍历的顶点顺序
*/
public void dfs(int[][] adjMatrix,int[] value,char[] result){
for(int i = 0;i < value.length;i++){
if(value[i] == 0){
char temp = (char) ('a' + i);
System.out.println();
System.out.println("深度为:"+i+",当前出发点:"+temp);
result[i] = temp; //存放当前正在遍历顶点下标字母
dfsVisit(adjMatrix,value,result,i);
}
}
}
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历
* result用于存放深度优先遍历的顶点顺序
* number是当前正在遍历的顶点在邻接矩阵中的数组下标编号
*/
public void dfsVisit(int[][] adjMatrix,int[] value,char[] result,int number){
value[number] = ++count; //把++count赋值给当前正在遍历顶点判断值数组元素,变为非0,代表已被遍历
System.out.print("当前已行走顶点value["+number+"] = "+value[number]+" ");
for(int i = 0;i < value.length;i++){
if(adjMatrix[number][i] == 1 && value[i] == 0){ //当当前顶点的相邻有相邻顶点可行走且其为被遍历
char temp = (char) ('a' + i);
result[count] = temp; //存放即将行走的顶点下标字母
System.out.println(" 当前i值:"+i+" 到达"+temp+"地");
dfsVisit(adjMatrix,value,result,i); //执行递归,行走第i个顶点
}
}
}
public static void main(String[] args){
int[] value = new int[10]; //初始化后,各元素均为0
char[] result = new char[10];
int[][] adjMatrix = {{0,0,1,1,1,0,0,0,0,0},
{0,0,0,0,1,1,0,0,0,0},
{1,0,0,1,0,1,0,0,0,0},
{1,0,1,0,0,0,0,0,0,0},
{1,1,0,0,0,1,0,0,0,0},
{0,1,1,0,1,0,0,0,0,0},
{0,0,0,0,0,0,0,1,0,1},
{0,0,0,0,0,0,1,0,1,0},
{0,0,0,0,0,0,0,1,0,1},
{0,0,0,0,0,0,1,0,1,0}};
DepthFirstSearch test = new DepthFirstSearch();
test.dfs(adjMatrix,value,result);
System.out.println();
System.out.println("判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历):");
for(int i = 0;i < value.length;i++)
System.out.print(" "+value[i]);
System.out.println();
System.out.println("深度优先查找遍历顺序如下:");
for(int i = 0;i < result.length;i++)
System.out.print(" "+result[i]);
}
}
运行结果:
深度为:0,当前出发点:a
当前已行走顶点value[0] = 1 当前i值:2 到达c地
当前已行走顶点value[2] = 2 当前i值:3 到达d地
当前已行走顶点value[3] = 3 当前i值:5 到达f地
当前已行走顶点value[5] = 4 当前i值:1 到达b地
当前已行走顶点value[1] = 5 当前i值:4 到达e地
当前已行走顶点value[4] = 6
深度为:6,当前出发点:g
当前已行走顶点value[6] = 7 当前i值:7 到达h地
当前已行走顶点value[7] = 8 当前i值:8 到达i地
当前已行走顶点value[8] = 9 当前i值:9 到达j地
当前已行走顶点value[9] = 10
判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历):
5 2 3 6 4 7 8 9 10
深度优先查找遍历顺序如下:
a c d f b e g h i j
Java实现DFS深度优先查找的更多相关文章
- 算法笔记_020:深度优先查找(Java)
目录 1 问题描述 2 解决方案 2.1 蛮力法 1 问题描述 深度优先查找(depth-first search,DFS)可以从任意顶点开始访问图的顶点,然后把该顶点标记为已访问.在每次迭代的时候, ...
- HDU 1241 Oil Deposits DFS(深度优先搜索) 和 BFS(广度优先搜索)
Oil Deposits Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- HDU 4707 Pet(DFS(深度优先搜索)+BFS(广度优先搜索))
Pet Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submissio ...
- DFS应用——查找强分支
[0]README 0.1) 本文总结于 数据结构与算法分析, 源代码均为原创, 旨在 理解 "DFS应用--查找强分支" 的idea 并用源代码加以实现 : [1]查找强分支 1 ...
- Java中常用的查找算法——顺序查找和二分查找
Java中常用的查找算法——顺序查找和二分查找 神话丿小王子的博客 一.顺序查找: a) 原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数据最后一位 ...
- Java学习之二分查找算法
好久没写算法了.只记得递归方法..结果测试下爆栈了. 思路就是取范围的中间点,判断是不是要找的值,是就输出,不是就与范围的两个临界值比较大小,不断更新临界值直到找到为止,给定的集合一定是有序的. 自己 ...
- Java进阶(三十九)Java集合类的排序,查找,替换操作
Java进阶(三十九)Java集合类的排序,查找,替换操作 前言 在Java方向校招过程中,经常会遇到将输入转换为数组的情况,而我们通常使用ArrayList来表示动态数组.获取到ArrayList对 ...
- 回溯算法 DFS深度优先搜索 (递归与非递归实现)
回溯法是一种选优搜索法(试探法),被称为通用的解题方法,这种方法适用于解一些组合数相当大的问题.通过剪枝(约束+限界)可以大幅减少解决问题的计算量(搜索量). 基本思想 将n元问题P的状态空间E表示成 ...
- (原创)不过如此的 DFS 深度优先遍历
DFS 深度优先遍历 DFS算法用于遍历图结构,旨在遍历每一个结点,顾名思义,这种方法把遍历的重点放在深度上,什么意思呢?就是在访问过的结点做标记的前提下,一条路走到天黑,我们都知道当每一个结点都有很 ...
随机推荐
- 使用反射模拟struts2属性注入功能
1.在项目开发中,如果没有使用框架进行数据绑定与封装,则可能会写大量的类似下面的代码: String value=request.getParameter("v"); if(nul ...
- Wfuzz使用学习
工具用了不总结,使用命令很容易生疏,今天就把笔记梳理总结一下. 0x01 简介 WFuzz是用于Python的Web应用程序安全性模糊工具和库.它基于一个简单的概念:它将给定有效负载的值替换对FUZZ ...
- orcle增删改操作及alter修改表字段操作
orcle增删改操作:操作前确保当前用户有增删改的权限. --创建表 create table itcast( pid ), pname ) ); drop table itcast; --复制表 c ...
- 查找算法----二分查找与hash查找
二分查找 有序列表对于我们的实现搜索是很有用的.在顺序查找中,当我们与第一个元素进行比较时,如果第一个元素不是我们要查找的,则最多还有 n-1 个元素需要进行比较. 二分查找则是从中间元素开始,而不是 ...
- 14.4 Go Xorm
14.4 Go Xorm 获取xorm go get -u -v github.com/go-xorm/xorm xorm增删改查 /** * 应用程序 * 同目录下多文件引用的问题解决方法: * h ...
- SWPU邮件登录界面的仿写(第二次作业)
(一).检查并下载网页元素 在需仿写的页面按F12,点击element,寻找需要的图片元素. (二). 分析网页的布局 查看网页源代码. (三).开始仿写 由于我们的目标是仿写网页,所以可以直接复制网 ...
- java颜色对照表
- 【面经分享】互联网寒冬,7面阿里,终获Offer,定级P6+
点赞再看,养成习惯,微信搜索[敖丙]关注这个互联网苟且偷生的工具人. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系列文 ...
- WordPress安全 - 隐藏保护wp-login.php后台登陆入口
我们在基本的设置账户用户名和密码安全基础上,最好把这个登录入口限制访问或者隐藏,之前也有看到一些教程说安装插件,比如安装Stealth Login Page插件可以设置登录页面后的参数,与我要设置的非 ...
- Flexible 应用
Flexibl.js 为我们做了一项工作,媒体查询工作,节约了许多操作 举个例子,移动端的页面设计稿是750px,我们自己换算rem单位,比如我想把屏幕划分为15等份,我就750/15=50,然后用所 ...