python对目录下的文件进行 多条件排序
在进入正题之前,先介绍一下基础知识:
1、sort(),方法:就是对列表内容进行正向排序,直接在原列表进行修改,返回的是修改后的列表
lists =[1, 5, 10, 8, 6]
lists.sort()
print(lists)
>>> [1, 5, 6, 8, 10]
2、sorted() 方法: 对列表进行排序后,返回一个新的列表,而原列表不变。并且sorted()方法可以用在任何数据类型的序列中,而返回的总是一个列表的形式。
lists = [1, 5, 10, 8, 6]
a = sorted(lists)
print(lists)
>>>[1, 5, 10, 8, 6]
print(a)
>>>[1, 5, 6, 8, 10]
3、进行多条件排序,使用参数 key 即可,其返回的顺序就是按照元组的顺序 。如果想要第一个顺序,第二个逆序,只需要在 x[1] 前面加上 -x[1]
lists = [(2, 5), (2, 3), (1, 2), (4, 2), (3, 4)] lists.sort(key=lambda x: (x[0], x[1])) print(lists)
>>>[(1, 2), (2, 3), (2, 5), (3, 4), (4, 2)]
好,介绍完之后,下面进入正题,自定义顺序 读取文件 多条件排序。
如图,要让下面这些文件进行自己想要的顺序排序,首先根据月份排,然后依据日期排;即先五月,从 5_1 到 5_15,然后再到 6_1 ,如果只是单纯的采用 sort() 和sorted()肯定是不能实现的,需要自定义方式,进行排序。
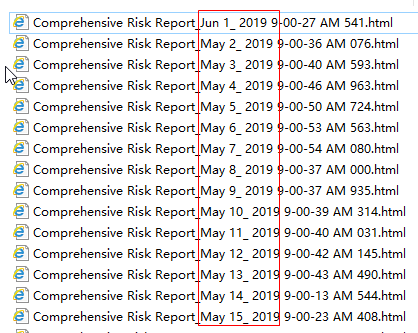
那么怎么来排序呢?
思路就是: 先对文件进行分割,得到 月份 和 天数,然后利用sort() 的key值,进行排序。
import os path = '..\\url\\'
file_selected = os.listdir(path)
month = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'] file_tem = []
file_comp = []
for file in file_selected:
file_tem.append(file) # [file]
value = file.split("_")[1].split(" ")[0]
ind = month.index(value) # 得到月份的下标
file_tem.append(ind) # [file,ind]
num = int(file.split("_")[1].split(" ")[1]) # 得到天数
file_tem.append(num) # [file,ind,num]
file_comp.append(file_tem) # 得到[[file,ind,num],[file2,ind2,num2]]的形式
file_tem = [] file_comp.sort(key=lambda x: (x[1], x[2])) # 根据ind排,再根据num2 排
sorted_file = [x[0] for x in file_comp] print(sorted_file)
最终得到结果:
['Comprehensive Risk Report_May 1_ 2019 9-00-36 AM 076.html',
'Comprehensive Risk Report_May 2_ 2019 9-00-36 AM 076.html',
'Comprehensive Risk Report_May 3_ 2019 9-00-40 AM 593.html',
'Comprehensive Risk Report_May 4_ 2019 9-00-46 AM 963.html',
'Comprehensive Risk Report_May 5_ 2019 9-00-50 AM 724.html',
'Comprehensive Risk Report_May 6_ 2019 9-00-53 AM 563.html',
'Comprehensive Risk Report_May 7_ 2019 9-00-54 AM 080.html',
'Comprehensive Risk Report_May 8_ 2019 9-00-37 AM 000.html',
'Comprehensive Risk Report_May 9_ 2019 9-00-37 AM 935.html',
'Comprehensive Risk Report_May 10_ 2019 9-00-39 AM 314.html',
'Comprehensive Risk Report_May 11_ 2019 9-00-40 AM 031.html',
'Comprehensive Risk Report_May 12_ 2019 9-00-42 AM 145.html',
'Comprehensive Risk Report_May 13_ 2019 9-00-43 AM 490.html',
'Comprehensive Risk Report_May 14_ 2019 9-00-13 AM 544.html',
'Comprehensive Risk Report_May 15_ 2019 9-00-23 AM 408.html',
'Comprehensive Risk Report_Jun 1_ 2019 9-00-27 AM 541.html']
这里为什么采用 file_tem = [ ] 而不是采用 file_tem.clear(),将在下一篇介绍。
python对目录下的文件进行 多条件排序的更多相关文章
- Python打开目录下所有文件
用Python打开指定目录下所有文件,统计文件里特定的字段信息. 这里是先进入2017-02-25到2017-03-03目录,然后进入特定IP段目录下,最后打开文件进行统计 import os, gl ...
- Python遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例
遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例: #-*- encoding: utf-8 -*- __author__ = 'liudong' import linecache,sys ...
- Python语言获取目录下所有文件
#coding=utf-8# -*- coding: utf-8 -*-import osimport sysreload(sys) sys.setdefaultencoding('utf-8') d ...
- Python遍历目录下xlsx文件
对指定目录下的指定类型文件进行遍历,可对文件名关键字进行条件筛选 返回值为文件地址的列表 import os # 定义一个函数,函数名字为get_all_excel,需要传入一个目录 def get_ ...
- python遍历目录下所有文件
# -*- coding:utf-8 -*- import os if __name__ == "__main__": rootdir = '.\data' list = os.l ...
- python获取目录下所有文件
#方法1:使用os.listdir import os for filename in os.listdir(r'c:\\windows'): print filename #方法2:使用glob模块 ...
- python拷贝目录下的文件
#!/usr/bin/env python # Version = 3.5.2 import shutil base_dir = '/data/media/' file = '/backup/temp ...
- python 读取目录下的文件
参考方法: import os path = r'C:\Users\Administrator\Desktop\file' for filename in os.listdir(path): prin ...
- Python递归遍历目录下所有文件
#自定义函数: import ospath="D:\\Temp_del\\a"def gci (path): """this is a stateme ...
随机推荐
- MySQL远程访问失败的解决办法
SQL连接预备知识:转载自https://jingyan.baidu.com/article/3ea51489e6cfbe52e61bba25.html问题:我想在另一个电脑通过navicat登陆本机 ...
- react render渲染的几种情况
1. 首次加载 2. setState改变组件内部state. 注意: 此处是说通过setState方法改变. 3. 接受到新的props
- android framework 之JNI
Java Native Interface ( JN I)是Java本地接口,所谓的本地(native) —般是指C/C++ ( 以下统称C)语言.当使用Java进行程序设计时,一般主要有三种情况需要 ...
- CentOS7搭建FTP Server
本文主要记录CentOS下FTP Server的安装和配置流程. 安装vsftpd yum install -y vsftpd 启动vsftpd service vsftpd start 运行下面的命 ...
- Spring Cloud 是什么
概念定义 Spring Cloud 是一个服务治理平台,提供了一些服务框架.包含了:服务注册与发现.配置中心.消息中心 .负载均衡.数据监控等等. Spring Cloud 是一个微服务框架,相比 D ...
- 7-29 jmu-python-不同进制数 (10 分)
输入一个十进制整数,输出其对应的八进制数和十六进制数.要求采用print函数的格式控制进行输出,八进制数要加前缀0o,十六进制数要加前缀0x. 输入格式: 输入一个十进制整数,例如:10 输出格式: ...
- JZOJ 3518. 【NOIP2013模拟11.6A组】进化序列(evolve)
3518. [NOIP2013模拟11.6A组]进化序列(evolve) (File IO): input:evolve.in output:evolve.out Time Limits: 1000 ...
- 【译文连载】 理解Istio服务网格(第六章 可观测性)
全书目录 第一章 概述 第二章 安装 第三章 流控 第四章 服务弹性 第五章 混沌测试 本文目录 第6章 可观测性 6.1 分布式调用链跟踪(tracing) 6.1.1 基本概念 6.1.2 Ja ...
- Yuchuan_Linux_C 编程之十 进程及进程控制
一.整体大纲 二.基础知识 1. 进程相关概念 1)程序和进程 程序,是指编译好的二进制文件,在磁盘上,不占用系统资源(cpu.内存.打开的文件.设备.锁....) 进程,是一个抽象的概念,与 ...
- HTTP GET请求302重定向问题
1.问题描述 ① 在华为云服务器中搭建了java环境,并在tomcat中部署了一个空的web项目 ② 在此web项目中上传了一个名为:plugin_DTDREAM_LIVING_DEHUMIDIFIE ...