KNN原理小结
K近邻法(K-nearest neighbors,KNN)既可以分类,也可以回归。
KNN做回归和分类的区别在于最后预测时的决策方式。KNN做分类时,一般用多数表决法;KNN做回归时,一般用平均法。
scikit-learn中只使用了蛮力实现(brute-force),KD树(KDTree),球树(BallTree),所以这里只讨论这几种算法。
1. KNN算法三要素
KNN算法主要考虑:k值的选取,距离度量方式,分类决策规则。
当K值较小,训练误差减小,泛化误差增大,模型复杂容易过拟合;当K值较大,泛化误差减小,训练误差增大,模型简单使预测发生错误(一个极端,K等于样本数m,则完全没有分类,此时无论测试集是什么,结果都属于训练集中最多的类)。
距离度量方式:欧式距离,曼哈顿距离,闵可夫斯基距离(欧式距离是闵可夫斯基距离在 p=2 的特例,曼哈顿距离是 p=1 的特例)。
2. KNN算法蛮力实现
计算预测样本和所有训练集中的样本距离,然后计算出最小的K个距离即可,接着多数表决,做出预测。这种方法简单,在样本量少,样本特征少的时候有效。
3. KNN算法之KD树实现原理
KD树就是K个特征维度的树。KNN中的K代表最近的K个样本,KD树中的K代表样本特征的维数。为了防止混淆,后面称特征维数为n。
KD树算法包括3步:第一建树,第二搜索最近邻,第三预测。
3.1 KD树的建立
KD树划分思想:
kd树实质是二叉树,其划分思想与CART树一致,即切分使样本复杂度降低最多的特征。kd树认为特征方差越大,则该特征的复杂度亦越大,优先对该特征进行切分 ,切分点是所有实例在该特征的中位数。重复该切分步骤,直到切分后无样本则终止切分,终止时的样本为叶节点。
具体步骤:
KD树的建立是从 m 个样本中的 n 维特征中,分别计算 n 个特征的取值的方差,用方差最大的第 K 维特征 nk 作为根节点。选择特征 nk 取值的中位数 nkv 对应的样本作为划分点,对于所有第 K 维特征的取值小于 nkv 的样本,划入左子树,对于第 K 维特征的取值大于等于 nkv 的样本,划入右子树,对于左右子树,采用和刚才同样的办法找方差最大的特征来做更节点,递归生成KD树。

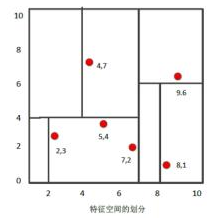
我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建KD树步骤:
- 找到划分的特征。6个数据点在 x,y维度上的数据方差分别为6.97,5.37,所以在 x 轴上方差更大,用第1维特征建树。
- 确定划分点(7,2)。根据根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
- 确定左子空间和右子空间。 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
- 用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
KD树(绿色为叶子节点,红色为节点和根节点):
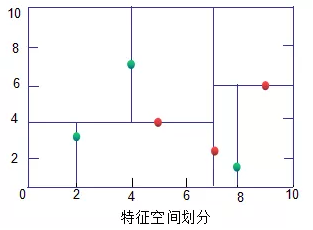
3.2 KD树搜索最近邻
生成KD树后,可以预测测试集里面的样本目标点了。对于每一个目标点,首先在KD树里面找到包含目标点的叶子节点。以目标点为圆心,目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话更新近邻。如果不想交,直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束。此时保存的最近邻节点就是最终的最近邻。
从上面可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交根本不需要计算距离。大大节省计算时间。
用3.1建立的KD树,来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
对应的图如下:

3.3 KD树预测
在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
KNN原理小结的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析.虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲 ...
- gc原理小结
一.相关概念 基本回收算法 1. 引用计数(Reference Counting) 比较古老的回收算法.原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回收时,只用收集计数为0 ...
- GBDT(梯度提升树) 原理小结
在之前博客中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 以下简 ...
随机推荐
- Hive入门指南
转自:http://blog.csdn.net/zhoudaxia/article/details/8842576 1.安装与配置 Hive是建立在Hadoop上的数据仓库软件,用于查询和管理存放在分 ...
- 模拟赛小结:The 2019 China Collegiate Programming Contest Harbin Site
比赛链接:传送门 上半场5题,下半场疯狂挂机,然后又是差一题金,万年银首也太难受了. (每次银首都会想起前队友的灵魂拷问:你们队练习的时候进金区的次数多不多啊?) Problem J. Justify ...
- 第10课:[实战] Redis 网络通信模块源码分析(3)
redis-server 接收到客户端的第一条命令 redis-cli 给 redis-server 发送的第一条数据是 *1\r\n\$7\r\nCOMMAND\r\n .我们来看下对于这条数据如何 ...
- STM32CubeIDE查看内存使用情况
按照下图操作 在右下角即可显示
- 使用pdo,使用pdo无法插入数据怎么办
如果你使用了最新版的XAMPP,那么你几乎不用改变php.ini的设置,就可以使用pdo but,插了一晚上,程序既不报错也不插入数据,真是气死人,后来发现是实例化pdo对象的时候没有指定字符集.所以 ...
- 初识容器和Docker
什么是Docker? Docker 是一个用于开发,交付和运行应用程序的开放平台.能够就应用程序和基础架构分开,从而可以快速的交付软件. 借助Docker可以和管理应用程序的方式来管理基础架构. 使用 ...
- spring data mongo API learn(转)
显示操作mongo的语句,log4j里面加入: log4j.logger.org.springframework.data.mongodb.core=DEBUG, mongodb log4j.appe ...
- 前端js之BOM和DOM操作
目录 引入 BOM操作 window对象 history对象 location对象(重点) 弹出框 定时器 计时器相关 DOM 查找标签 直接查找 间接查找 节点操作 创建节点及添加节点 删除节点 替 ...
- 【winform-窗体快捷键】定义功能窗体快捷键,非全局
这里的快捷键并非系统全局快捷键.仅是普通的当窗体在焦点内发生.有很多种方法,这里列举几种项目中使用到的方法. Alt+*(一般控件快捷键) 这个比较简单,只需为该控件的Text属性声明时加上”(&am ...
- linux运维、架构之路-MongoDB单机部署
一.MongoDB介绍 MongoDB 是一个基于分布式文件存储的数据库.由 C++ 语言编写.旨在为 WEB 应用提供可扩展的高性能数据存储解决方案. MongoDB 是一个介于关系型数据库和非关系 ...