KNN原理小结
K近邻法(K-nearest neighbors,KNN)既可以分类,也可以回归。
KNN做回归和分类的区别在于最后预测时的决策方式。KNN做分类时,一般用多数表决法;KNN做回归时,一般用平均法。
scikit-learn中只使用了蛮力实现(brute-force),KD树(KDTree),球树(BallTree),所以这里只讨论这几种算法。
1. KNN算法三要素
KNN算法主要考虑:k值的选取,距离度量方式,分类决策规则。
当K值较小,训练误差减小,泛化误差增大,模型复杂容易过拟合;当K值较大,泛化误差减小,训练误差增大,模型简单使预测发生错误(一个极端,K等于样本数m,则完全没有分类,此时无论测试集是什么,结果都属于训练集中最多的类)。
距离度量方式:欧式距离,曼哈顿距离,闵可夫斯基距离(欧式距离是闵可夫斯基距离在 p=2 的特例,曼哈顿距离是 p=1 的特例)。
2. KNN算法蛮力实现
计算预测样本和所有训练集中的样本距离,然后计算出最小的K个距离即可,接着多数表决,做出预测。这种方法简单,在样本量少,样本特征少的时候有效。
3. KNN算法之KD树实现原理
KD树就是K个特征维度的树。KNN中的K代表最近的K个样本,KD树中的K代表样本特征的维数。为了防止混淆,后面称特征维数为n。
KD树算法包括3步:第一建树,第二搜索最近邻,第三预测。
3.1 KD树的建立
KD树划分思想:
kd树实质是二叉树,其划分思想与CART树一致,即切分使样本复杂度降低最多的特征。kd树认为特征方差越大,则该特征的复杂度亦越大,优先对该特征进行切分 ,切分点是所有实例在该特征的中位数。重复该切分步骤,直到切分后无样本则终止切分,终止时的样本为叶节点。
具体步骤:
KD树的建立是从 m 个样本中的 n 维特征中,分别计算 n 个特征的取值的方差,用方差最大的第 K 维特征 nk 作为根节点。选择特征 nk 取值的中位数 nkv 对应的样本作为划分点,对于所有第 K 维特征的取值小于 nkv 的样本,划入左子树,对于第 K 维特征的取值大于等于 nkv 的样本,划入右子树,对于左右子树,采用和刚才同样的办法找方差最大的特征来做更节点,递归生成KD树。

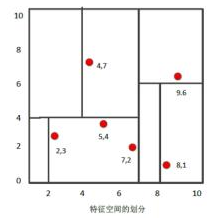
我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建KD树步骤:
- 找到划分的特征。6个数据点在 x,y维度上的数据方差分别为6.97,5.37,所以在 x 轴上方差更大,用第1维特征建树。
- 确定划分点(7,2)。根据根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
- 确定左子空间和右子空间。 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
- 用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
KD树(绿色为叶子节点,红色为节点和根节点):
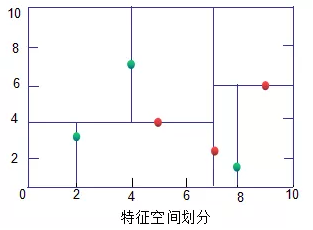
3.2 KD树搜索最近邻
生成KD树后,可以预测测试集里面的样本目标点了。对于每一个目标点,首先在KD树里面找到包含目标点的叶子节点。以目标点为圆心,目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话更新近邻。如果不想交,直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束。此时保存的最近邻节点就是最终的最近邻。
从上面可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交根本不需要计算距离。大大节省计算时间。
用3.1建立的KD树,来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
对应的图如下:

3.3 KD树预测
在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
KNN原理小结的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析.虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲 ...
- gc原理小结
一.相关概念 基本回收算法 1. 引用计数(Reference Counting) 比较古老的回收算法.原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回收时,只用收集计数为0 ...
- GBDT(梯度提升树) 原理小结
在之前博客中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 以下简 ...
随机推荐
- jq自动触发事件
$('.btn_fath ').trigger("click");$('.btn_fath ').click();
- 11、Nginx反向代理服务
1Nginx代理服务基本概述 1.代理一词并不陌生, 该服务我们常常用到如(代理理财.代理租房.代理收货等等),如下图所示 2.在没有代理模式的情况下,客户端和Nginx服务端,都是客户端直接请求服务 ...
- 网络初级篇之DHCP原理与配置(原理与实验)
一.什么是DHCP DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)通常被应用在大型的局域网络环境中,主要作用是集中的管理.分配IP地址,使网络环境 ...
- 浅析Java泛型
什么是泛型? 泛型是JDK 1.5的一项新特性,它的本质是参数化类型(Parameterized Type)的应用,也就是说所操作的数据类型被指定为一个参数,在用到的时候在指定具体的类型.这种参数类型 ...
- SpringBoot核心特性之组件自动装配
写在前面 spring boot能够根据依赖的jar包自动配置spring boot的应用,例如: 如果类路径中存在DispatcherServlet类,就会自动配置springMvc相关的Bean. ...
- MyEclipse 2016 反编译插件安装
下载插件,分享一下下载插件的地址,百度网盘:链接:http://pan.baidu.com/s/1nturiAH 密码:yk73 1.把net.sf.jadclipse_3.3.0.jar拷到D:\P ...
- win10操作系统下oracle11g客户端/服务端的下载安装配置卸载总结
win10操作系统下oracle11g客户端/服务端的下载安装配置卸载总结 一:前提 注意:现在有两种安装的方式 1. oracle11g服务端(64位)+oracle客户端(32位)+plsql(3 ...
- mongdb的优势和不足
l 面向文档的数据库. l 一个介于关系型数据库和非关系型数据库之间的产品,是非关系系数据库中功能最丰富,最像关系型数据库的. l 特征是模式自由,schema-free.无需定义表结构. l ...
- ab测试nginx Nginx性能优化
转自:https://www.cnblogs.com/nulige/p/9369700.html 1.性能优化概述 在做性能优化前, 我们需要对如下进行考虑 1.当前系统结构瓶颈 观察指标 压力测试 ...
- 前端面试题-CSS优先级
一.选择器优先级 浏览器通过优先级来判断哪一些属性值与一个元素最为相关,从而在该元素上应用这些属性值.优先级是基于不同种类选择器组成的匹配规则. 二.优先级计算 优先级就是分配给指定的CSS声明的一个 ...