变分推断到变分自编码器(VAE)
EM算法
EM算法是含隐变量图模型的常用参数估计方法,通过迭代的方法来最大化边际似然。

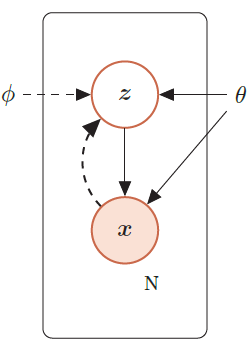
带隐变量的贝叶斯网络
给定N 个训练样本D={x(n)},其对数似然函数为:
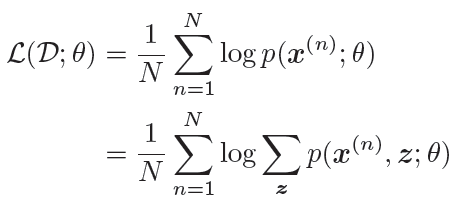
通过最大化整个训练集的对数边际似然L(D; θ),可以估计出最优的参数θ∗。然而计算边际似然函数时涉及p(x) 的推断问题,需要在对数函数的内部进行求和(或积分)
注意到,对数边际似然log p(x; θ) 可以分解为
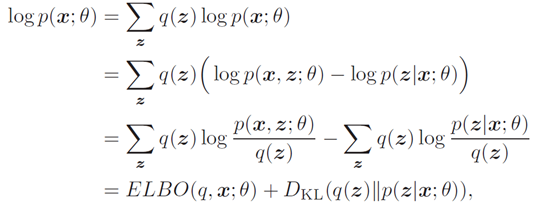
其中DKL(q(z)∥p(z|x; θ))为分布q(z)和后验分布p(z|x; θ)的KL散度.
由于DKL(q(z)∥p(z|x; θ)) ≥ 0,并当且仅当q(z) = p(z|x; θ) 为0,因此 ELBO(q, x; θ) 为log p(x; θ) 的一个下界
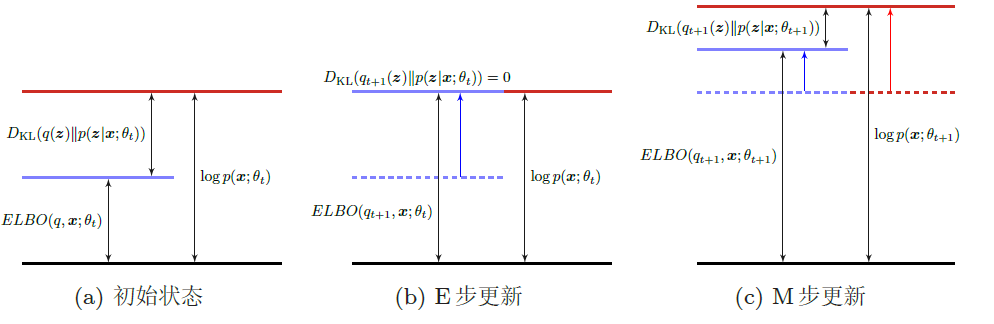
EM算法具体分为两个步骤:E步和M步。这两步不断重复,直到收敛到某个局部最优解。在第t 步更新时,E步和M步分别为
- E步(Expectation Step):固定参数θt,找到一个分布使得ELBO(q, x; θt)最大,即等于log p(x; θt)
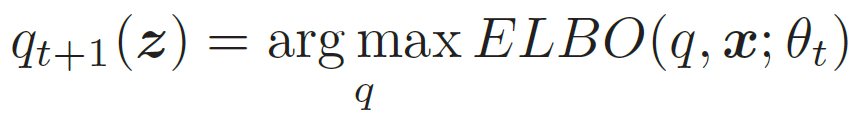
- 所以我们希望q(z) = p(z|x, θt) ,这样ELBO(q, x; θt)最大。而计算后验分布p(z|x; θ)是一个推断(Inference)问题。如果z是有限的一维离散变量 。(比如混合高斯模型),计算起来还比较容易。否则,p(z|x; θ) 一般情况下很难计算,需要通过变分推断的方法来进行近似估计
- M步(Maximization Step):固定qt+1(z),找到一组参数使得证据下界最大,即
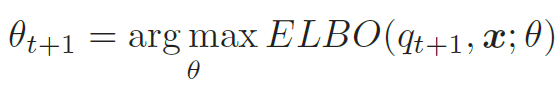
EM算法在第t 步迭代时的示例
变分自编码
变分自编码器
生成模型的联合概率密度函数
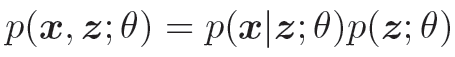
给定一个样本x,其对数边际似然log p(x; θ) 可以分解为

其中q(z; ϕ)是额外引入的变分密度函数, 其参数为ϕ,ELBO(q, x; θ, ϕ)为证据下界,
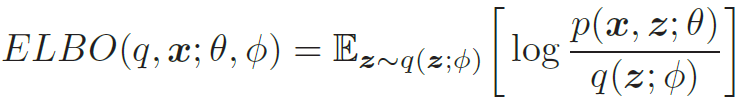
最大化对数边际似然log p(x; θ) 可以用EM算法来求解,具体可以分为两步:
E步:寻找一个密度函数q(z; ϕ) 使其等于或接近于后验密度函数p(z|x; θ);
M步:保持q(z; ϕ) 固定,寻找θ 来最大化ELBO(q, x; θ, ϕ)。
PS: 当p(z|x; θ)比较复杂时,很难用简单的变分分布q(z; ϕ)去近似,此时,q(z; ϕ)也相对比较复杂,除此之外,概率密度函数p(x|z; θ)一般也比较复杂。那怎么办呢?很简单,我们可以用神经网络来近似这两个复杂的概率必读函数。这就是变分自编码器(Variational AutoEncoder,VAE)的精髓。
- 推断网络:用神经网络来估计变分分布q(z; ϕ),理论上q(z; ϕ) 可以不依赖x。但由于q(z; ϕ) 的目标是近似后验分布p(z|x; θ),其和x相关,因此变分密度函数一般写为q(z|x; ϕ)。推断网络的输入为x,输出为变分分布q(z|x; ϕ)。
- 生成网络:用神经来估计概率分布p(x|z; θ),生成网络的输入为z,输出为概率分布p(x|z; θ)。
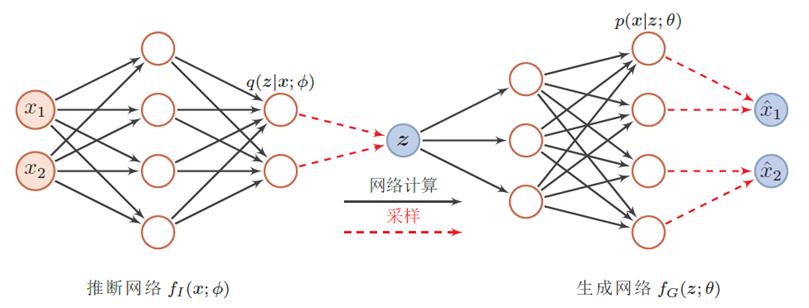
变分自编码器的网络结构
推断网络
为了简单起见,假设q(z|x; ϕ) 是服从对角化协方差的高斯分布
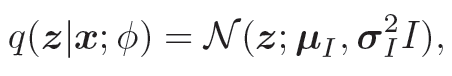
均值和方程我们可以用推断网络fI(x; ϕ)来预测
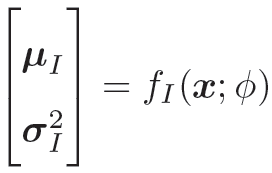
目标:q(z|x; ϕ) 尽可能接近真实的后验p(z|x; θ),
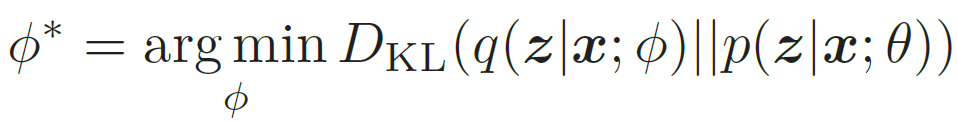
然而,直接计算上面的KL散度是不可能的,因为p(z|x; θ) 一般无法计算。注意到,
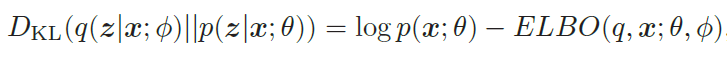
所以,推断网络的目标函数为
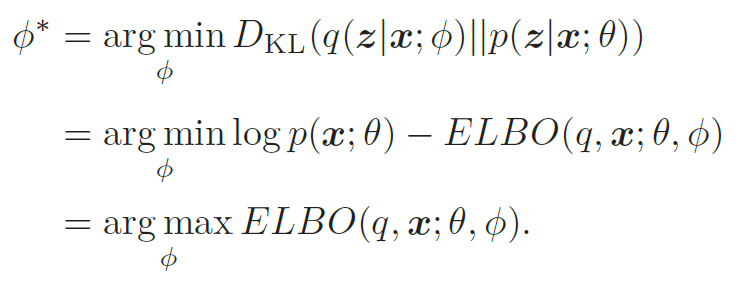
生成网络
生成模型的联合分布p(x, z; θ) 可以分解为两部分:隐变量z 的先验分布p(z; θ) 和条件概率分布p(x|z; θ),
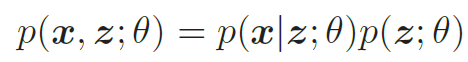
为了简单起见,我们假设先验分布
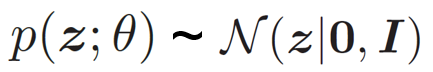
而条件概率分布p(x|z; θ)我们可以用生成网络来建模,里面的参数可以用生成网络计算得到。
根据变量x 的类型不同,可以假设p(x|z; θ) 服从不同的分布族
- x in {0, 1}d, 可以假设log p(x|z; θ) 服从多变量的伯努利分布,即

- x in Rd, 可以假设p(x|z; θ) 服从对角化协方差的高斯分布,即
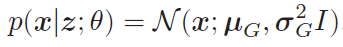
目标:找到一组θ∗ 来最大化证据下界ELBO(q, x; θ, ϕ),
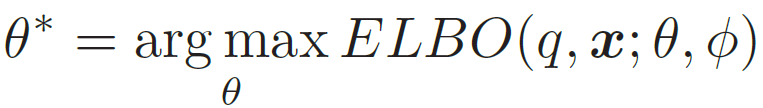
模型
总目标函数

其中先验分布p(z; θ) = N(z|0, I),θ 和ϕ 分别表示生成网络和推断网络的参数。
训练
可以采用随机梯度方法,每次从数据集中采集一个样本x,然后根据q(z|x; ϕ)采集一个隐变量z,则目标函数为
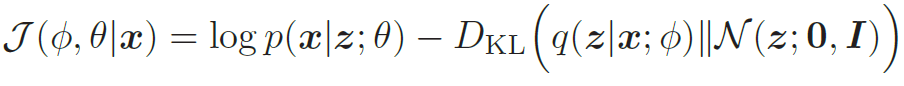
此时,KL 散度可以直接计算出闭式解。对于d 维空间中的两个正态分布N(μ1,Σ1) 和N(μ2,Σ2),其KL散度为
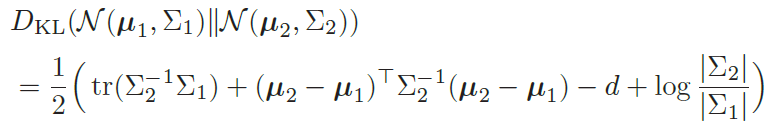
其中tr(·)表示矩阵的迹,| · |表示矩阵的行列式。具体可以看这个链接。
所以,我们有
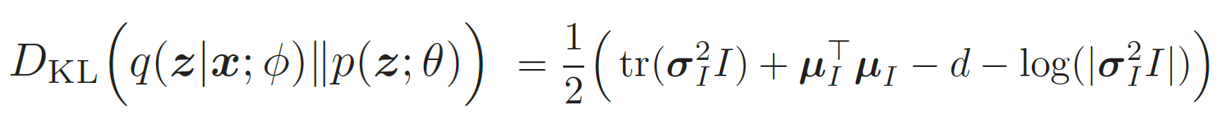
最后,VAE里面有一个非常重要的trick -- Reparameterization
再参数化
问题: 如何求随机变量z 关于参数ϕ 的导数,。因为随机变量z 采样自后验分布q(z|x; ϕ),和参数ϕ相关。但由于是采样的方式,无法直接刻画z 和ϕ 之间的函数关系,因此也无法计算z 关于ϕ 的导数
假设q(z|x; ϕ) 为正态分布N(μI ,σI2I),其中μI 和σI 是推断网络fI (x; ϕ) 的输出。我们可以采用下面方式来采样z。
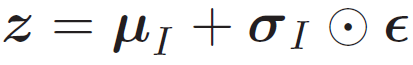
其中ϵ ∼ N(0, I)。这样z 和μI ,σI 的关系从采样关系变为函数关系,就可以求z关于ϕ 的导数。
通过再参数化,变分自编码器可以通过梯度下降法来学习参数了。如果进一步假设p(x|z; θ) 服从高斯分布N(x|μG, I),其中μG = fG(z; θ) 是生成网络的输出,则目标函数可以简化为
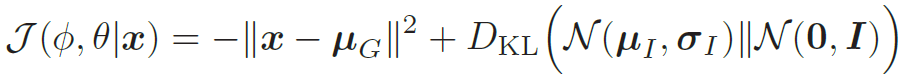
下面是整个变分自编码器的训练过程

变分推断到变分自编码器(VAE)的更多相关文章
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- PRML读书会第十章 Approximate Inference(近似推断,变分推断,KL散度,平均场, Mean Field )
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:02:04 我们在前面看到,概率推断的核心任务就是计算某分布下的某个函数的期望.或者计算边缘概率分布.条件 ...
- 文本主题模型之LDA(三) LDA求解之变分推断EM算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法 本文是LDA主题模型的第三篇,读这一篇之前 ...
- 变分推断(Variational Inference)
(学习这部分内容大约需要花费1.1小时) 摘要 在我们感兴趣的大多数概率模型中, 计算后验边际或准确计算归一化常数都是很困难的. 变分推断(variational inference)是一个近似计算这 ...
- 变分推断(Variational Inference)
变分 对于普通的函数f(x),我们可以认为f是一个关于x的一个实数算子,其作用是将实数x映射到实数f(x).那么类比这种模式,假设存在函数算子F,它是关于f(x)的函数算子,可以将f(x)映射成实数F ...
- 变分(图)自编码器不能直接应用于下游任务(GAE, VGAE, AE, VAE and SAE)
自编码器是无监督学习领域中一个非常重要的工具.最近由于图神经网络的兴起,图自编码器得到了广泛的关注.笔者最近在做相关的工作,对科研工作中经常遇到的:自编码器(AE),变分自编码器(VAE),图 ...
- 再谈变分自编码器VAE:从贝叶斯观点出发
链接:https://kexue.fm/archives/5343
- VAE变分自编码器
我在学习VAE的时候遇到了很多问题,很多博客写的不太好理解,因此将很多内容重新进行了整合. 我自己的学习路线是先学EM算法再看的变分推断,最后学VAE,自我感觉这个线路比较好理解. 一.首先我们来宏观 ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
随机推荐
- 【JVM学习笔记】类加载过程
在Java代码中,类型的加载.连接与初始化过程都是在程序运行期间完成的:提供了更大的灵活性,增加了更多的可能性 JVM启动过程包括:加载.连接.初始化 加载:就是将class文件加载到内存.详细的说是 ...
- 走进Selenium新世界
浏览器 Firefox Setup 35.0.1 安装完成后设置菜单栏 关闭浏览器自动更新 插件配置(必备武器) FireBug Firebug是firefox下的一个扩展,能够调试所有网站语言,如H ...
- 守护进程,互斥锁, IPC ,Queue队列,生产消费着模型
1.守护进程 什么是守护进程? 进程是一个正在运行的程序 守护进程也是一个普通进程,意思是一个进程可以守护另一个进程,比如如果b是a的守护进程,a是被守护的进程,如果a进程结束,b进程也会随之结束. ...
- Linux常用目录名称
目录 用途 / 虚拟目录的根文件,通常不会在这里存储文件 /bin 二进制目录,存放许多用户的GNU工具 /boot 启动目录,存放启动文件 /dev 设备目录,Linux在这里创建设备节点 /etc ...
- 【POJ - 3984】迷宫问题(dfs)
-->迷宫问题 Descriptions: 定义一个二维数组: int maze[5][5] = { 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0 ...
- 通俗易懂的lambda表达式,不懂来找我!
lambda是Python编程语言中使用频率较高的一个关键字.那么,什么是lambda?它有哪些用法?网上的文章汗牛充栋,可是把这个讲透的文章却不多.这里,我们通过阅读各方资料,总结了关于Python ...
- C++学习笔记-模板
模板把函数或类要处理的数据类型参数化,表现为参数的多态性,称为类属.模板用于表达逻辑结构相同,但具体数据元素类型不同的数据对象的通用行为. 什么是模板 类属--类型参数化,又称参数模板 使得程序(算法 ...
- DQN算法原理详解
一. 概述 强化学习算法可以分为三大类:value based, policy based 和 actor critic. 常见的是以DQN为代表的value based算法,这种算法中只有一个值函数 ...
- python 爬虫 基于requests模块的get请求
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返回请求成功的响应对 ...
- IIS写权限漏洞和XFF刷票原理
IIS写权限漏洞 PUT写入漏洞 此漏洞主要是因为服务器开启了webdav的组件导致的 1.扫描漏洞,yes,可以PUT: 2.用老兵的工具上传一句话文件test.txt,然后move改名为shell ...