Redis 布隆过滤器
1、布隆过滤器
内容参考:https://www.jianshu.com/p/2104d11ee0a2
1、数据结构
布隆过滤器是一个BIT数组,本质上是一个数据,所以可以根据下标快速找数据
2、哈希映射
1、布隆需要记录见过的数据,这里的记录需要通过hash函数对数据进行hash操作,得到数组下标并存储在BIT 数组里记为1。这样的记录一个数据只占用1BIT空间
2、判断是否存在时:给布隆过滤器一个数据,进行hash得到下标,从BIT数组里取数据如果是1 则说明数据存在,如果是0 说明不存在
3、精确度
hash算法存在碰撞的可能,所以不同的数据可能hash为一个下标数据,故为了提高精确度就需要 使用多个hash 算法标记一个数据,和增大BIT数组的大小
也是因为如此,布隆过滤器判断为【数据存在】 可能数据并不存在,但是如果判断为【数据不存在】那么数据就一定是不存在的。
4、例子
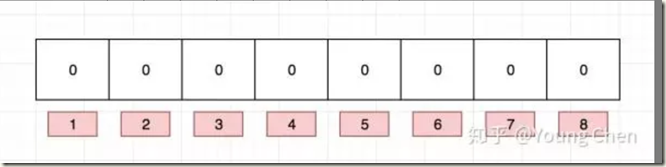
下图映射 baidu字样到布隆过滤器中,用了三个不同的hash函数 3BIT 判断一个数据,BIT数组大小为8
哈希函数返回 1、4、7
.
我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
以下 4 位置发生了hash碰撞
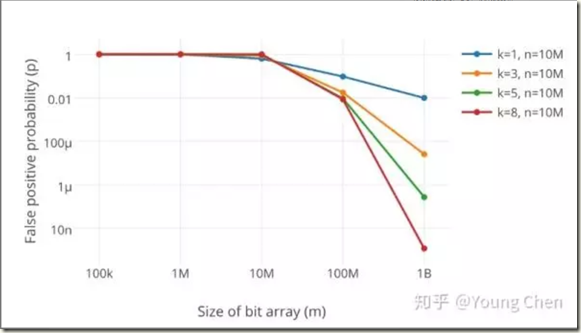
5、如何选择哈希函数个数和布隆过滤器长度
显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
6、不支持删除
布隆过滤器只能插入数据判断是否存在,不能删除,而且只能保证【不存在】判断绝对准确
以上不难看出如果给数组的每个BIT位上加一个计数器,插入的时候+1 删除的时候 –1 就可以实现删除。
但是加计数器的实现是有问题的:
由于hash碰撞问题,布隆过滤器不能准确判断数据是否存在,就不能随意删除。其次计数器的回绕问题也需要考虑。

2、给redis安装布隆过滤器模块
1、下载:
地址:https://github.com/RedisBloom/RedisBloom
下载ZIP 文件,上传到linux
RedisBloom-master.zip
2、解压编译
命令:
unzip RedisBloom-master.zip
cd RedisBloom-master
make
扫行完以上命令 后文件夹内生成一个文件名为:redisbloom.so
3、启动redis 时加载该模块
命令:
redis-server redis-6381.conf --loadmodule /zjl/software/RedisBloom-master/redisbloom.so
3、验证
1、链接redis
命令:
redis-cli –a zjl123
2、测试布隆过滤
命令:
bf.add zjl 123
bf.exists zjl 123 #返回 1 ,说明存在值
bf.exists zjl 321 #返回 0, 说明不存在该值
3、准确率
Redis中有一个命令可以来设置布隆过滤器的准确率:
bf.reserve zjl 0.01 100
bf.reserve 有三个参数,分别是 key, error_rate 和 initial_size 。
错误率越低,需要的空间越大。
initial_size 参数表示预计放 入的元素数量,当实际数量超出这个数值时,误判率会上升。
所以需要提前设置一个较大的数值避免超出导致误判率升高。
如果不使用 bf.reserve,默认的 error_rate 是 0.01,默认的 initial_size 是 100。
布隆过滤器的 initial_size 估计的过大,会浪费存储空间,估计的过小,就会 影响准确率,
用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上 一定的冗余空间以避免实际元素可能会意外高出估计值很多。
布隆过滤器的 error_rate 越小,需要的存储空间就越大,对于不需要过于精确 的场合, error_rate 设置稍大一点也无伤大雅。
比如在新闻去重上而言,误判 率高一点只会让小部分文章不能让合适的人看到,
文章的整体阅读量不会因为这 点误判率就带来巨大的改变。
4、项目中使用
1、redis布隆过滤器
没有找到jedis 支持bloom过滤器 命令的版本,只找到了另外一个JAR包的支持,但是也不太好用,没弄明白如何添加密码连接
引入包
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.0.2</version>
</dependency>JAR包里只有三个类,对连接方式 和 数据类型 的支持都不够
代码:
Client client = new Client(redisProperties.getHost(), redisProperties.getPort(), 10000, 100);
client.add("zjl", "");
boolean zjl = client.exists("zjl", "");
System.out.println(zjl);2、Guava中的BloomFilter
google的guava包中提供了BloomFilter类,直接用的是服务器内存
导入包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>代码:
private static int size = 1000000;
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size, 0.0001); public void test2() {
String aa = "zjl";
bloomFilter.put(aa);
System.out.println(bloomFilter.mightContain(aa));
}3、自已实现布隆过滤器
java 有bitSet数组,hash函数可以自己手动实现
自己手写是可以实现布隆过滤器的,在此不做研究。
Redis 布隆过滤器的更多相关文章
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- Redis详解(十三)------ Redis布隆过滤器
本篇博客我们主要介绍如何用Redis实现布隆过滤器,但是在介绍布隆过滤器之前,我们首先介绍一下,为啥要使用布隆过滤器. 1.布隆过滤器使用场景 比如有如下几个需求: ①.原本有10亿个号码,现在又来了 ...
- 关于布隆过滤器,手写你真的知其原理吗?让我来带你手写redis布隆过滤器。
说到布隆过滤器不得不提到,redis, redis作为现在主流的nosql数据库,备受瞩目:它的丰富的value类型,以及它的偏向计算向数据移动属性减少IO的成本问题.备受开发人员的青睐.通常我们使用 ...
- Redis布隆过滤器和布谷鸟过滤器
一.过滤器使用场景:比如有如下几个需求:1.原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存入数据库中,进行数据库查询,准 ...
- Redis布隆过滤器与布谷鸟过滤器
大家都知道,在计算机中,IO一直是一个瓶颈,很多框架以及技术甚至硬件都是为了降低IO操作而生,今天聊一聊过滤器,先说一个场景: 我们业务后端涉及数据库,当请求消息查询某些信息时,可能先检查缓存中是否有 ...
- 硬核 | Redis 布隆(Bloom Filter)过滤器原理与实战
在Redis 缓存击穿(失效).缓存穿透.缓存雪崩怎么解决?中我们说到可以使用布隆过滤器避免「缓存穿透」. 码哥,布隆过滤器还能在哪些场景使用呀? 比如我们使用「码哥跳动」开发的「明日头条」APP 看 ...
- 布隆过滤器(Bloom Filter)简要介绍
一种节省空间的概率数据结构 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判.但是布隆过滤器也不是特别不精确,只要参数设置的 ...
- 浅谈redis的HyperLogLog与布隆过滤器
首先,HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法. HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元 ...
- 基于Redis扩展模块的布隆过滤器使用
什么是布隆过滤器?它实际上是一个很长的二进制向量和一系列随机映射函数.把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到不同的二进制向量的位中,以此来间接标记一个元素是否存在于一个 ...
随机推荐
- html input标签 要求只能输入纯数字
在input标签添加以下代码即可 oninput = "value=value.replace(/[^\d]/g,'')" <input type="text&qu ...
- JS设置首字母大写算法
返回一个字符串,确保字符串的每个单词首字母都大写,其余部分小写. 像'the'和'of'这样的连接符同理. function titleCase(str) { //把字符串所有的字母变为小写,并根据空 ...
- 发布并开源自己的一款 基于.Net 4.0 及 netstandard2.0 的 ORM 框架
这款ORM框架的原版在经历过大概十几个项目的磨合,最近整理了一下,原名字为:ZhCun.Framework ,该框架辗转跟了我去过几家公司,大概从2012年出现第一个版本,当时就为简化数据库操作,从优 ...
- jQuery效果-隐藏与显示 小方块的移除
html <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <ti ...
- cpanle/Apache 强制http跳转到https
因为租的虚拟主机是使用Cpanel,按照网上找的文章,处理的步骤如下: 打开Cpanel面板-文件管理器-设置(在页面的右上角)-勾选显示隐藏文件(dotfiles)-save . 找到网站所在的目录 ...
- python print 连续输出变量加字符串
a=1 b=2 print(a,'+',b,'=',a+b) 输出:1+2=3
- Vim默认开启语法标识功能
把syntax on加到$HOME/.vimrc文件中.
- 信号量的使用 ManualResetEvent
线程的等待时可以用这个,不论是线程池还是线程都可以用这个做等待. ManualResetEvent md=new ManualResetEvent(false);//这个false 设置线程等待, t ...
- cocos2D-X not config ndk path
{ 双击击那个error,那个路径就加上了 File = >local.properties }
- shell快速入门
$? 表示上一个命令退出的状态,0表示执行正常,不等于0表示执行不正常. $$ 表示当前进程编号 $ 表示当前脚本名称 $# 表示参数的个数,常用于循环 $*和$@ 都表示参数列表 $n 表示n位置的 ...