SQL Server里Grouping Sets的威力【转】
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务)。我不是说在生产里使用开发版,也不是说安装盗版SQL Server。
不可能的任务?未必,因为通过SQL Server里所谓的Grouping Sets就可以。在这篇文章里我会给你概括介绍下Grouping Sets,使用它们可以实现哪类查询,什么是它们的性能优势。
使用Grouping Sets的聚合
假设你有个订单表,你想进行跨多个分组的T-SQL聚集查询。在AdventureWorks2012数据库的Sales.SalesOrderHeader表的环境里,这些分组可以类似如下:
- 在每列分组
- GROUP BY SalesPersonID, YEAR(OrderDate)
- GROUP BY CustomerID, YEAR(OrderDate)
- GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
当你想用传统T-SQL查询进行这些各自分组时,你需要多个语句,对各个记录集进行UNION ALL。我们来看这样的查询:

1 SELECT * FROM
2 (
3 -- 1st Grouping Set
4 SELECT
5 NULL AS 'CustomerID',
6 NULL AS 'SalesPersonID',
7 NULL AS 'OrderYear',
8 SUM(TotalDue) AS 'TotalDue'
9 FROM Sales.SalesOrderHeader
10 WHERE SalesPersonID IS NOT NULL
11
12 UNION ALL
13
14 -- 2nd Grouping Set
15 SELECT
16 NULL AS 'CustomerID',
17 SalesPersonID,
18 YEAR(OrderDate) AS 'OrderYear',
19 SUM(TotalDue) AS 'TotalDue'
20 FROM Sales.SalesOrderHeader
21 WHERE SalesPersonID IS NOT NULL
22 GROUP BY SalesPersonID, YEAR(OrderDate)
23
24 UNION ALL
25
26 -- 3rd Grouping Set
27 SELECT
28 CustomerID,
29 NULL AS 'SalesPersonID',
30 YEAR(OrderDate) AS 'OrderYear',
31 SUM(TotalDue) AS 'TotalDue'
32 FROM Sales.SalesOrderHeader
33 WHERE SalesPersonID IS NOT NULL
34 GROUP BY CustomerID, YEAR(OrderDate)
35
36 UNION ALL
37
38 -- 4th Grouping Set
39 SELECT
40 CustomerID,
41 SalesPersonID,
42 YEAR(OrderDate) AS 'OrderYear',
43 SUM(TotalDue) AS 'TotalDue'
44 FROM Sales.SalesOrderHeader
45 WHERE SalesPersonID IS NOT NULL
46 GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
47 ) AS t
48 ORDER BY CustomerID, SalesPersonID, OrderYear
49 GO
用这个T-SQL语句方法有多个缺点:
- T-SQL语句本身很庞大,因为每个单独分组都是一个不同查询。
- 每查询1次,Sales.SalesOrderHeader表需要访问4次。
- 每查询1次,你在执行计划里会看到SQL Server进行了4次的索引查找(非聚集)(Index Seek (NonClustered) )。

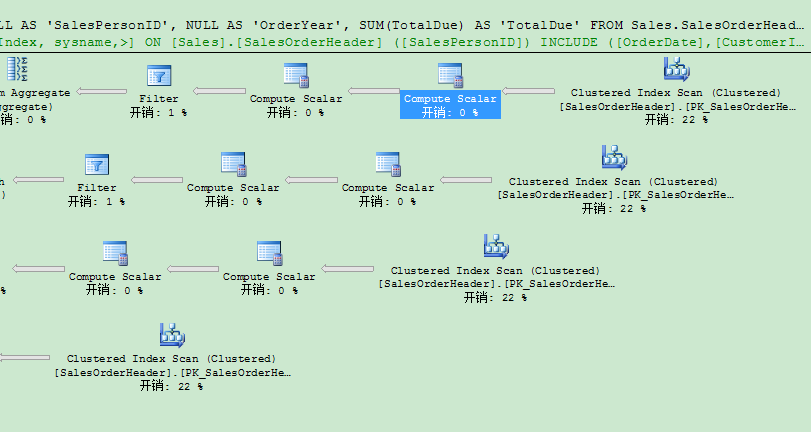
如果你使用自SQL Server 2008以后引入的grouping sets功能,就可以大大简化你需要的T-SQL代码。下面代码展示你同样的查询,但这次用grouping sets实现。
1 SELECT
2 CustomerID,
3 SalesPersonID,
4 YEAR(OrderDate) AS 'OrderYear',
5 SUM(TotalDue) AS 'TotalDue'
6 FROM Sales.SalesOrderHeader
7 WHERE SalesPersonID IS NOT NULL
8 GROUP BY GROUPING SETS
9 (
10 -- Our 4 different grouping sets
11 (CustomerID, SalesPersonID, YEAR(OrderDate)),
12 (CustomerID, YEAR(OrderDate)),
13 (SalesPersonID, YEAR(OrderDate)),
14 ()
15 )
16 GO
从代码本身可以看到,你只在GROUP BY GROUPING SETS子句里指定需要的分组集——其它的一切都由SQL Server搞定。指定的空括号是所谓的Empty Grouping Set,是跨整个表的聚集。当你看STATISTICS IO输出时,你会发现Sales.SalesOrderHeader只被访问了1次!这是和刚才手工实现的巨大区别。

在执行计划里,SQL Server使用了Table Spool运算符,它把获得的数据临时存储在TempDb里。来自临时表里创建的Worktable的数据在执行计划的第2个分支被使用。因此对来自表的每个分组数据没有重新扫描,这就给整个执行计划的带来了更好的性能。
我们再来看下执行计划,你会发现查询计划包含了3个Stream Aggregate运算符(红色,蓝色,绿色高亮显示)。这3个运算符计算各个分组集:
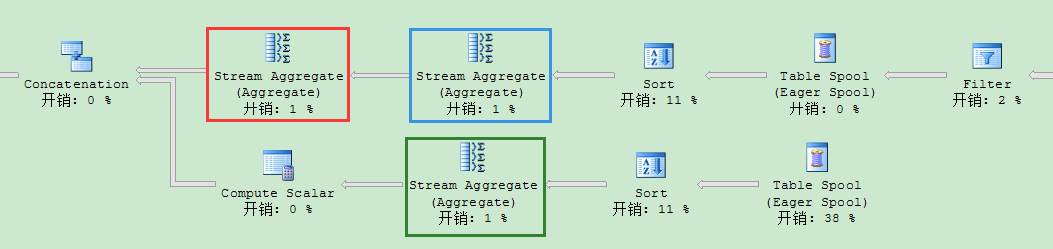
- 蓝色高亮的运算符计算CustomerID, SalesPersonID, YEAR(OrderDate的分组集。
- 红色高亮的运算符计算SalesPersonID, YEAR(OrderDate)的分组集。另外也计算每1列的分组集。
- 绿色高亮的运算符计算CustomerID, YEAR(OrderDate)的分组集。
2个连续的Stream Aggregate运算符的背后想法是计算所谓的Super Aggregates——聚集的聚集。
小结
在今天的文章里我给你介绍了grouping sets,在SQL Server 2008后引入的增强T-SQL。如你所见grouping sets有2个大优点:简化你的代码,只访问一次数据提高查询性能。
我希望现在你已经能够很好理解grouping sets,如果你能在你的数据库里使用这个功能可以在此留言,非常感谢!
感谢关注!
原文链接:https://www.cnblogs.com/woodytu/p/4685959.html
SQL Server里Grouping Sets的威力【转】的更多相关文章
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server里PIVOT运算符的”红颜祸水“
在今天的文章里我想讨论下SQL Server里一个特别的T-SQL语言结构——自SQL Server 2005引入的PIVOT运算符.我经常引用这个与语言结构是SQL Server里最危险的一个——很 ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server里的文件和文件组
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组.当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个 ...
- 在SQL Server里我们为什么需要意向锁(Intent Locks)?
在1年前,我写了篇在SQL Server里为什么我们需要更新锁.今天我想继续这个讨论,谈下SQL Server里的意向锁,还有为什么需要它们. SQL Server里的锁层级 当我讨论SQL Serv ...
- SQL Server里的闩锁介绍
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介 ...
- 在SQL Server里为什么我们需要更新锁
今天我想讲解一个特别的问题,在我每次讲解SQL Server里的锁和阻塞(Locking & Blocking)都会碰到的问题:在SQL Server里,为什么我们需要更新锁?在我们讲解具体需 ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
- SQL Server里强制参数化的痛苦
几天前,我写了篇SQL Server里简单参数化的痛苦.今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization). 强制参数化(Forced Par ...
随机推荐
- web端 微软 RDLC 报表插件 宽大于高 横向打印失效 解决方案
起因于系统报表工具使用的RDLC,本地测试一直使用的纵向打印,未测试过横向打印
- mac 上iterm终端连接Linux服务后 中文为乱码问题
https://www.jianshu.com/p/8b00f71b2177 编辑 ssh 配置vim /etc/ssh/ssh_config修改如下:Host *#SendEnv LANG LC_* ...
- 菜鸟系列k8s——k8s集群部署(2)
k8s集群部署 1. 角色分配 角色 IP 安装组件 k8s-master 10.0.0.170 kube-apiserver,kube-controller-manager,kube-schedul ...
- 使用 docsify 創建自己的 markdown 文檔系統
先來看一下我在碼雲上創建的demo: http://lin1270.gitee.io/nicedoc/#/ GIT自己clone一下: https://gitee.com/lin1270/nicedo ...
- [转帖]国产CPU性能最全盘点 宜良性竞争优胜劣汰
国产CPU性能最全盘点 宜良性竞争优胜劣汰 电子工程专辑的网站内容 其实里面说的不尽全面 比如龙芯和申威就放到一块了 一个是 MIPS 一个是Alpha 明显不一样的东西 x86的应该都不行 而且. ...
- [转帖] Linux下面计算文件数量的方法
Linux命令-查看目录下文件个数 2018年07月04日 10:37:07 sand_clock 阅读数 2002 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- 小菜鸟之java异常
一.异常简介 什么是异常? 异常就是有异于常态,和正常情况不一样,有错误出错.在java中,阻止当前方法或作用域的情况,称之为异常. java中异常的体系是怎么样的呢? 1.Java中的所有不正常类都 ...
- Kick Start 2019 Round A Contention
$\DeclareMathOperator*{\argmax}{arg\,max}$ 题目链接 题目大意 一排 $N$ 个座位,从左到右编号 $1$ 到 $N$ . 有 $Q$ 个预定座位的请求,第 ...
- Entity Framework常用方法及案例
⒈Skip(int count) 说明:跳过集合的前n个元素:延迟.即我们跳过给定的数目返回后面的结果集. ⒉Take(int count) 说明:获取集合的前n个元素:延迟.即只返回限定数量的结果集 ...
- C++多线程基础学习笔记(四)
一.创建多个子线程 前面三章讲的例子都是只有一个子线程和主线程,然而实际中有多个子线程.那么下面介绍如何创建多个子线程. #include <iostream> #include < ...