35 怎么优化join
35 怎么优化join
上一篇介绍了join的两种算法:nlj和bnl
create table t1(id int primary key, a int, b int, index(a));
create table t2 like t1;
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, 1001-i, i);
set i=i+1;
end while; set i=1;
while(i<=1000000)do
insert into t2 values(i, i, i);
set i=i+1;
end while; end;;
delimiter ;
call idata();
Multi-Range Read优化
Multi-range read(MRR),优化的主要目的是尽量使用顺序读盘。
在介绍innodb的索引结构时,提到了”回表”的概念,回表是指,在innodb普通索引a上查到主键id的值后,再根据一个个主键id的值到主键索引上去查询整行数据的过程。
但是回表的过程是一行行的查数据还是批量的查询数据呢?
select * from t1 where a>=1 and a<=100;
主键索引是一个B+tree,在这个树上,每次只能根据一个主键id查到一行数据,因此,回表肯定是一行行搜索主键索引的
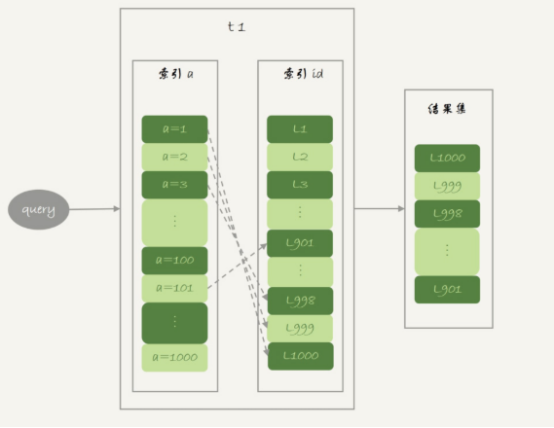
随着a的值递增顺序查询的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差,虽然”按行查”这个机制不能改,但是调整查询的顺序还是能够加速的。
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
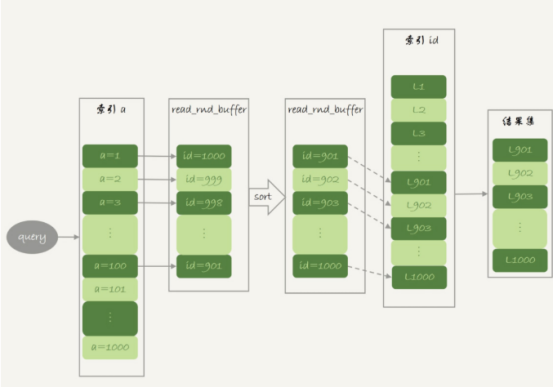
这就是mrr的优化设计的思路,语句的执行流程:
--1 根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中
--2 将read_rnd_buffer中的id进行递增排序
--3 排序后的id数组,依次到主键id索引中查询记录,并作为结果返回。
这里read_rnd_buffer的大小由read_rnd_buffer_size参数控制,如果read_rnd_buffer放满了,就会先执行步骤2和3,然后清空read_rnd_buffer,之后继续找索引a的下个记录,并继续循环。--如果主键是uuid类型,排序就没有必要了,也没有必要使用MRR。
如果要稳定的使用MRR优化,需要设置set optimizer_switch='mrr_cost_based=off';
使用mrr的流程
explain
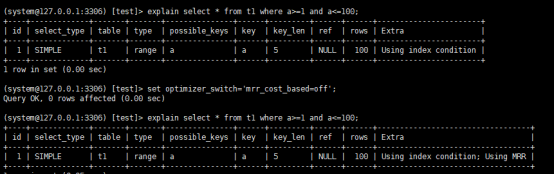
可以看到extra字段多了MRR,表示的是用上了mrr优化,而且,由于我们在read_rnd_buffer中按照id做了排序,所以最后得到的结果集也是按照主键id递增顺序的,
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询(也就是说是一个多值查询),可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出”顺序性”的优势。
Bathed Key Access
在mysql 5.6版本开始引入了BKA算法,其实是对NLJ算法的优化。
在看一下上一篇提到的NLJ算法的流程
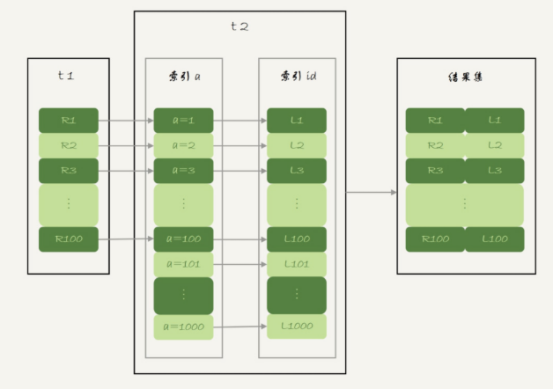
NLJ算法执行的逻辑是:从驱动表t1,一行行地取出a的值,再到被驱动表t2上去做join,也就是说,对于表t2,每次都是匹配一个值,这时,mrr的优势就用不上了。
现把表t1的数据取出来一部分,先放到一个临时内存,这个临时内存就是join_buffer
上面NLJ算法优化后
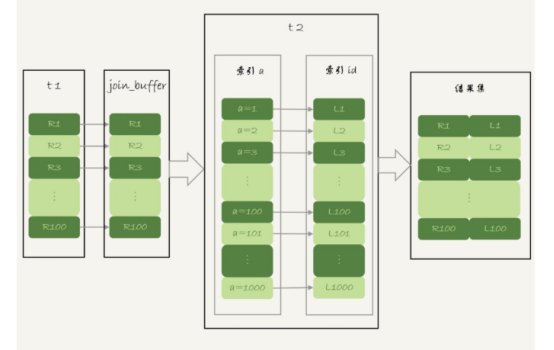
图中,在join_buffer中放入的数据是R1-R100,表示只会取查询需要的字段,当然join_buffer中放不下R1-R100的所有数据,就会把这100行数据分成多个段执行
开启BKA算法
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
BNL算法的性能问题
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。
如果这个冷表很大,就会出现另外一种情况,业务正常访问的数据页,没有机会进入young区域,由于优化机制的存在,一个正常访问的数据页,要进入young区域,需要隔1秒再次被访问到,但是,由于我们的join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1秒之内就被淘汰了,这样,就会导致这个mysql实例的buffer pool在这段时间内,young区域的数据页每页被合理淘汰掉。
大表join操作虽然对io有影响,但是在语句执行结束后,对io的影响也就结束了。但是,对buffer pool的影响就是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率。
为了减少这种影响,可以考虑增大join_buffer_size值,减少对被驱动表的扫描次数。
也就是说,BNL算法对系统的影响:
--1 可能会多次扫描被驱动表,占用磁盘io资源
--2 判断join条件需要执行M*N次对比(M,N分别是两张表的行数),如果是大表就会占用非常多的cpu资源
--3 可能会导致buffer pool的热数据被淘汰,影响内存命中率。
在执行语句之前,需要通过理论分析和查看explain结果的方式,确认是否使用BNL算法,如果确认优化器会使用BNL算法,就需要做优化,优化的常见做法是,给被驱动表的join字段上加索引,把BNL算法转换成BKA算法。
create index idx_t2_b on t2(b);

BNL转BKA
一些情况下,我们可以直接在被驱动表上建立索引,这时就可以直接转成BKA算法,但是,有时候确实会碰到一些不适合在被驱动表上建立索引的情况
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;

在t2表中插入了100w行数据,但是经过where条件过滤后,需要参与join的只有2000行数据,如果这条语句同时是一个低频的sql语句,那么再为这个语句在表t2的字段b上建立一个索引就很浪费了。
使用BNL算法来join的话,这个语句的执行流程
--1 把表t1的所有字段取出来,存入join_buffer,这个表只有1000行,join_buffer_size默认256k,可以完全存入
--2 扫描表t2,取出每一行数据跟join_buffer中的数据进行对比
---如果不满足t1.b=t2.b则跳过
---如果满足t1.b=t2.b,在判断其他条件,也就是是否满足t2.b处于[1,2000]的条件,如果是,就作为结果集的一部分返回,否则跳过。
对于表t2的每一行,判断join是否满足的时候,都需要遍历join_buffer中的所有行,因此判断等值的次数1000*100万次,
查询结果耗时
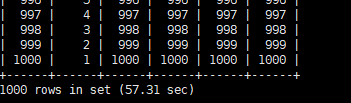
在explain 中看到使用了BNL算法
在表t2的字段b上创建索引会浪费资源,但是不创建索引的话这个语句的等值判断要消耗1000*100w次
这时候,可以考虑使用临时表,大致思路:
--1 把表t2中满足条件的数据放在临时表tmp_t中
--2 为了让join使用BKA算法,给临时表tmp_t的字段b上加上索引
--3 让表t1和tmp_t做join操作
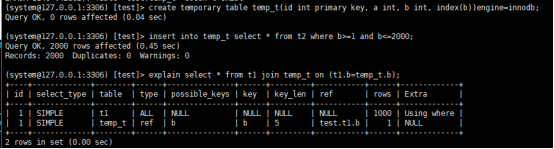
耗时
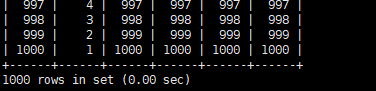
相比前面的BNL算法,性能提升很高。
总体来说,不论是在原表上加索引,还是用索引的临时表,我们的思路是让join语句能够使用被驱动表上的索引,来触发BKA算法,提升查询性能。
扩展-hash join
由于mysql的优化器和执行器不支持hash join,可以自己在业务端实现,大致流程
--1 select * from t1;取得表t1的全部1000行数据,在业务端存入一个hash结构,比如C++里面的set,php的数组这样的数据结构
--2 select * from t2 where b>=1 and b<=2000;获取t2中满足条件的2000行数据
--3 把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据,满足匹配的条件的这行数据,就作为结果集的一行。
小结:
介绍了NLJ和BNL的优化方法
在这些优化方法中:
--1 BKA优化是mysql已经内置支持的,建议默认使用
--2 BNL算法效率低,建议尽量转换成BKA算法,优化的方向就是给被驱动表的管理字段上加上索引
--3 基于临时表的改进方案,对于能够提前过滤小数据的join来说,效果还是很好的
--4 mysql目前的版本还不支持hash join,可以配合应用端模拟出来
35 怎么优化join的更多相关文章
- 022:SQL优化--JOIN算法
目录 一. SQL优化--JOIN算法 1.1. JOIN 写法对比 2. JOIN的成本 3. JOIN算法 3.1. simple nested loop join 3.2. index nest ...
- paip.sql索引优化----join 代替子查询法
paip.sql索引优化----join 代替子查询法 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn.n ...
- MYSQL join 优化 --JOIN优化实践之快速匹配
MySQL的JOIN(四):JOIN优化实践之快速匹配 优化原则:小表驱动大表,被驱动表建立索引有效,驱动表建立索引基本无效果.A left join B :A是驱动表,B是被驱动表:A right ...
- 你知道如何优化Join语句吗?
join语句的两种算法,分别是:NLJ和BNL 测试数据: create table t1(id int primary key, a int, b int, index(a)); create ta ...
- MySQL 5.6.35 索引优化导致的死锁案例解析
一.背景 随着公司业务的发展,商品库存从商品中心独立出来成为一个独立的系统,承接主站商品库存校验.订单库存扣减.售后库存释放等业务.在上线之前我们对于核心接口进行了压测,压测过程中出现了 MySQL ...
- 优化join语句
Mysql4.1开始支持SQL的子查询.这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中.使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的 ...
- Apache Phoenix的Join操作和优化
估计Phoenix中支持Joins,对很多使用Hbase的朋友来说,还是比较好的.下面我们就来演示一下. 首先看一下几张表的数据: Orders表: OrderID CustomerID ItemID ...
- MySQL的JOIN(四):JOIN优化实践之快速匹配
这篇博文讲述如何优化扫描速度.我们通过MySQL的JOIN(二):JOIN原理得知了两张表的JOIN操作就是不断从驱动表中取出记录,然后查找出被驱动表中与之匹配的记录并连接.这个过程的实质就是查询操作 ...
- MySQL的JOIN(五):JOIN优化实践之排序
这篇博文讲述如何优化JOIN查询带有排序的情况.大致分为对连接属性排序和对非连接属性排序两种情况.插入测试数据. CREATE TABLE t1 ( id INT PRIMARY KEY AUTO_I ...
随机推荐
- rabitMQ-centos7安装
1.安装rabitMq之前需要安装Erlang cd /usr/local/ wget http://erlang.org/download/otp_src_18.3.tar.gz tar -zxvf ...
- delete释放空间时出错的原因
int *a=new int[10]; ...... delete []a; 后面“delete []a;”出现错误的情况大致有: 1 数组的首地址a被你有意无意更改了,如:a++之类的: 2 变量的 ...
- 基于Kintex Ultrasacle的万兆网络光纤 PCIe加速卡416 光纤PCIe卡
基于Kintex Ultrasacle的万兆网络光纤 PCIe加速卡 一.产品概述 本卡为企业级别板卡,可用于数据中心,安全领域数据采集处理.标准PCI Express全高板,适用于普通服务器.工作站 ...
- STL的容器哈希表
C++ STL中,哈希表对应的容器是 unordered_map(since C++ 11).根据 C++ 11 标准的推荐,用 unordered_map 代替 hash_map. 与Map的区别 ...
- MySQL---时区问题
1.控制台输入select now(); 发现与北京时间相差8小时: 2.解决: 2.1.进入MySQL客户端 mysql -uroot -p 2.2.全局,当前会话时区设置set GLOBAL ...
- Kafka---系统学习
1.Topics 1.1.Topic 就是 数据主题: 1.2.作用:数据记录 发布的地方,用来 区分 业务系统: 1.3.每个Topic 可以有多个 消费者 订阅它的数据: 1.4.每个T ...
- php实现大文件上传带进度条
1.使用PHP的创始人 Rasmus Lerdorf 写的APC扩展模块来实现(http://pecl.php.net/package/apc) APC实现方法: 安装APC,参照官方文档安装,可以使 ...
- asp.net实现大视频上传
IE的自带下载功能中没有断点续传功能,要实现断点续传功能,需要用到HTTP协议中鲜为人知的几个响应头和请求头. 一. 两个必要响应头Accept-Ranges.ETag 客户端每次提交下载请求时,服务 ...
- python 存取字典dict
数据处理的时候主要通过两个函数(1):np.save(“test.npy”,数据结构) ----存数据(2):data =np.load('test.npy") ----取数据 1.存列表 ...
- formdata方式上传文件,支持大文件分割上传
1.upload.html <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/html"> <h ...