基于bs4库的HTML标签遍历方法
基于bs4库的HTML标签遍历方法
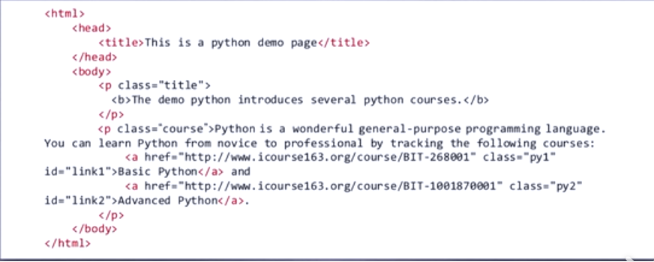
import requests
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
HTML基本格式
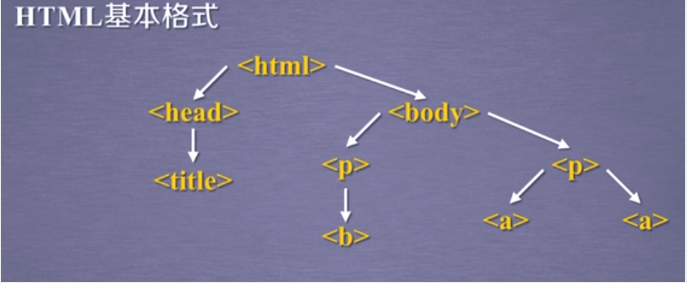
HTML可以看做一棵标签树
遍历方法
!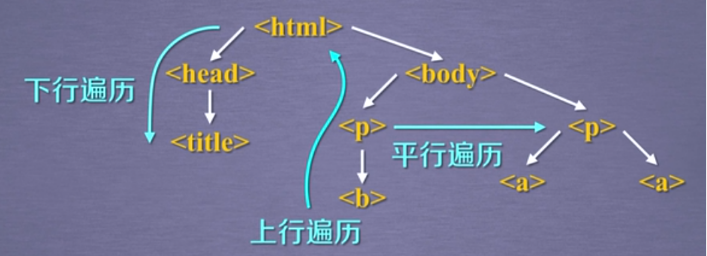
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 将该标签所有的儿子节点存入列表 |
| .children | 子节点的迭代类型,和contents类似,用于遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有的子孙跌点,用于循环遍历 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.contents)# 获取整个标签树的儿子节点
print(soup.body.content)#返回标签树的body标签下的节点
print(soup.head)#返回head标签
print(len(soup.body.content))#输出body标签儿子节点的个数
print(soup.body.content[1])#获取body下第一个子标签
遍历子孙节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for child in soup.body.children:#遍历儿子节点
print(child)
for child in soup.body.descendants:#遍历子孙节点
print(child)
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点的先辈标签的迭代类型,用于循环遍历先辈节点 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.title.parent)
print(soup.title.parent)
print(soup.parent)
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for parent in soup.a.parents:#遍历先辈的信息
if parent is None:
print(parent)
else:
print(parent.name)
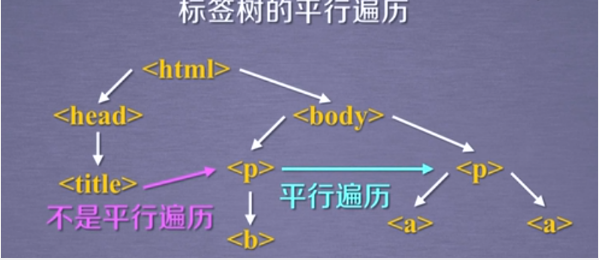
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回HTML文本顺序的下一个平行标签 |
| .previous_sibling | 返回HTML文本顺序的上一个平行标签 |
| .next_siblings | 迭代类型,返回HTML文本顺序后续所有的平行标签 |
| .pervious_siblings | 迭代类型,返回HTML文本顺序前面所有的平行标签 |
注意
- 标签树的平行遍历是有条件的
- 平行遍历发生在同一个父亲节点的各节点之间
- 标签中的内容也构成了节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.a.next_sibling)#a标签的下一个标签
print(soup.a.next_sibling.next_sibling)#a标签的下一个标签的下一个标签
print(soup.a.previous_sibling)#a标签的前一个标签
print(soup.a.previous_sibling.previous_sibling)#a标签的前一个标签的前一个标签
平行遍历
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for sibling in soup.a.next_siblings:#遍历后续节点
print(sibling)
for sibling in soup.a.previous_sibling:#遍历之前的节点
print(sibling)
有层次感的输出-prettify()
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
基于bs4库的HTML标签遍历方法的更多相关文章
- 基于bs4库的HTML内容查找方法
一.信息提取实例 提取HTML中所有的URL链接 思路:1)搜索到所有的<a>标签 2)解析<a>标签格式,提取href后的链接内容 >>> import r ...
- 基于bs4库的HTML查找方法
基于bs4库的HTML查找方法 find_all方法 <>.find_all(name,attrs,recursive,string,**kwargs) 返回一个列表类型,内部存储查找的结 ...
- python bs4库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. BeautifulSoup ...
- 《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)
1.XPath: XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 工具:扩展商店里搜索:XPath ...
- WebGIS中基于控制点库进行SHP数据坐标转换的一种查询优化策略
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.前言 目前项目中基于控制点库进行SHP数据的坐标转换,流程大致为:遍 ...
- JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
- javaweb学习总结(二十八)——JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
- 学会怎样使用Jsp 内置标签、jstl标签库及自定义标签
学习jsp不得不学习jsp标签,一般来说,对于一个jsp开发者,可以理解为jsp页面中出现的java代码越少,对jsp的掌握就越好,而替换掉java代码的重要方式就是使用jsp标签. jsp标签的分 ...
- javaWeb学习总结(9)- JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
随机推荐
- Python 字典(Dictionary)Ⅱ
删除字典元素 能删单一的元素也能清空字典,清空只需一项操作. 显示删除一个字典用del命令,如下实例: 但这会引发一个异常,因http://www.xuanhe.net/为用del后字典不再存在: 注 ...
- luogu 4927 [1007]梦美与线段树 概率与期望 + 线段树
考场上切了不考虑没有逆元的情况(出题人真良心). 把概率都乘到一起后发现求的就是线段树上每个节点保存的权值和的平方的和. 这个的修改和查询都可以通过打标记来实现. 考场代码: #include < ...
- 树状数组(Binary Indexed Tree)
树状数组(Binary Indexed Tree,BIT) 是能够完成下述操作的数据结构. 给一个初始值全为 0 的数列 a1, a2, ..., an (1)给定 i,计算 a1+a2+...+ai ...
- [BZOJ3456]城市规划:DP+NTT+多项式求逆
写在前面的话 昨天听吕老板讲课,数数题感觉十分的神仙. 于是,ErkkiErkko这个小蒟蒻也要去学数数题了. 分析 Miskcoo orz 带标号无向连通图计数. \(f(x)\)表示\(x\)个点 ...
- swiper实现滑动到某页锁住不让滑动
var swiper = new Swiper('.swiper-container', { pagination: '.swiper-pagination', onTouchStart: funct ...
- 配置kubernetes.client的参数遇到的坑
配置kubernetes.client遇到的一些坑: 一,job-name不能重名,如果job-name已经有了,再创建job,则会发生冲突cliflict 这样将会报以下错误:Reason : Co ...
- Python的 counter内置函数,统计文本中的单词数量
counter是 colletions内的一个类 可以理解为一个简单的计数 import collections str1=['a','a','b','d'] m=collections.Counte ...
- 关闭layer.open打开的页面
window.parent.location.reload(); //刷新父页面 var index = parent.layer.getFrameIndex(window.name); //获取窗口 ...
- architecture 20190628
https://abp.io/ --ABP v2 官网 https://grpc.io/ --gRPC官网 https://devblogs.microsoft.com/dotnet/introdu ...
- Go Int转string几种方式性能测试
Go Int转string几种方式性能测试 - 贤冰的博客 - CSDN博客 https://blog.csdn.net/flyfreelyit/article/details/79701577