Javac词法分析
参考:《深入分析Java Web》技术内幕 许令波
词法分析过程涉及到的主要类及相关的继承关系如下:
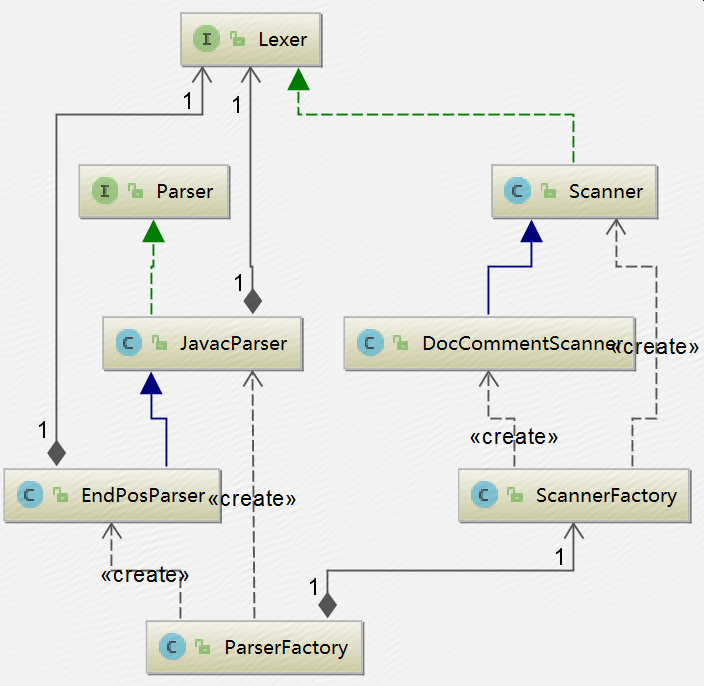
词法分析的接口为Lexer,默认实现类为Scanner,Scanner会逐个读取Java源文件中的单个字符,然后解析出符合Java语言规范的Token序列。
举个例子,如下:
package compile;
/**
* Created by mazhi on 2018/6/5.
*/
public class Cifa {
int a;
int c = a + 1;
}
其最终的语法树如下:

首先的一个语法节点为JCCompilationUnit,关于这个节点的介绍如下:
Compilation Units参考:https://docs.oracle.com/javase/specs/jls/se7/html/jls-7.html#jls-7.3
定义如下:
CompilationUnit:
PackageDeclarationopt ImportDeclarationsopt TypeDeclarationsopt
ImportDeclarations:
ImportDeclaration
ImportDeclarations ImportDeclaration
TypeDeclarations:
TypeDeclaration
TypeDeclarations TypeDeclaration
可以看到一个CompilationUnit可以有多个TypeDeclaration声明。当前只有一个JCClassDecl节点,代码这个Cifa类。
其中涉及到了PackageDeclaration、ImportDeclaration与TypeDeclaration声明,其各个定义如下:
(1)PackageDeclaration节点定义如下:
PackageDeclaration:
Annotationsopt package PackageName ;
参考:https://docs.oracle.com/javase/specs/jls/se7/html/jls-7.html#jls-7.4
(2)ImportDeclaration节点定义如下:
ImportDeclaration:
SingleTypeImportDeclaration
TypeImportOnDemandDeclaration
SingleStaticImportDeclaration
StaticImportOnDemandDeclaration
参考:https://docs.oracle.com/javase/specs/jls/se7/html/jls-7.html#jls-7.5
(3)TypeDeclaration节点定义如下:
ClassDeclaration:
NormalClassDeclaration
EnumDeclaration
NormalClassDeclaration:
ClassModifiersopt class Identifier TypeParametersopt
Superopt Interfacesopt ClassBody
参考:https://docs.oracle.com/javase/specs/jls/se7/html/jls-8.html#jls-8.1
查看JavaCompiler.java类中的方法parse(),代码如下:
/**
* Parse contents of input stream.
*
* @param filename The name of the file from which input stream comes.
* @param input The input stream to be parsed.
*/
protected JCCompilationUnit parse(JavaFileObject filename, CharSequence content) {
long msec = now();
JCCompilationUnit tree = treeMaker.TopLevel(List.<JCAnnotation>nil(), null, List.<JCTree>nil());
if (content != null) {
if (verbose) {
log.printVerbose("parsing.started", filename);
}
Parser parser = parserFactory.newParser(content, keepComments(), genEndPos, lineDebugInfo);
tree = parser.parseCompilationUnit();
if (verbose) {
log.printVerbose("parsing.done", Long.toString(elapsed(msec)));
}
}
tree.sourcefile = filename;
return tree;
}
这个方法有三点需要解析:
(1)参数content为源文件的字符输入流。是一个HeapCharBuffer对象,其中用char数组来保存输入的字符流内容,具体内容如下:
nextToken(0,7)=|package|
Token.PACKAGE
0 = 'p' 112
1 = 'a' 97
2 = 'c' 99
3 = 'k' 107
4 = 'a' 97
5 = 'g' 103
6 = 'e' 101
processWhitespace(7,8)=| |
7 = ' ' 32
nextToken(8,15)=|compile|
Token.IDENTIFIER
8 = 'c' 99
9 = 'o' 111
10 = 'm' 109
11 = 'p' 112
12 = 'i' 105
13 = 'l' 108
14 = 'e' 101
nextToken(15,16)=|;|
Token.SEMI
15 = ';' 59
processTerminator(16,18)=||
16 = '\r' 13
17 = '\n' 10
processTerminator(18,20)=||
18 = '\r' 13
19 = '\n' 10
processComment(20,62,JAVADOC)=|/**
* Created by mazhi on 2018/6/5.
*/|
20 = '/' 47
21 = '*' 42
22 = '*' 42
23 = '\r' 13
24 = '\n' 10
25 = ' ' 32
26 = '*' 42
27 = ' ' 32
28 = 'C' 67
29 = 'r' 114
30 = 'e' 101
31 = 'a' 97
32 = 't' 116
33 = 'e' 101
34 = 'd' 100
35 = ' ' 32
36 = 'b' 98
37 = 'y' 121
38 = ' ' 32
39 = 'm' 109
40 = 'a' 97
41 = 'z' 122
42 = 'h' 104
43 = 'i' 105
44 = ' ' 32
45 = 'o' 111
46 = 'n' 110
47 = ' ' 32
48 = '2' 50
49 = '0' 48
50 = '1' 49
51 = '8' 56
52 = '/' 47
53 = '6' 54
54 = '/' 47
55 = '5' 53
56 = '.' 46
57 = '\r' 13
58 = '\n' 10
59 = ' ' 32
60 = '*' 42
61 = '/' 47
processTerminator(62,64)=||
62 = '\r' 13
63 = '\n' 10
nextToken(64,70)=|public|
Token.PUBLIC
64 = 'p' 112
65 = 'u' 117
66 = 'b' 98
67 = 'l' 108
68 = 'i' 105
69 = 'c' 99
processWhitespace(70,71)=| |
70 = ' ' 32
nextToken(71,76)=|class|
Token.CLASS
71 = 'c' 99
72 = 'l' 108
73 = 'a' 97
74 = 's' 115
75 = 's' 115
processWhitespace(76,77)=| |
76 = ' ' 32
nextToken(77,81)=|Cifa|
Token.IDENTIFIER
77 = 'C' 67
78 = 'i' 105
79 = 'f' 102
80 = 'a' 97
processWhitespace(81,82)=| |
81 = ' ' 32
nextToken(82,83)=|{|
Token.LBRACE
82 = '{' 123
processTerminator(83,85)=||
83 = '\r' 13
84 = '\n' 10
processWhitespace(85,89)=| |
85 = ' ' 32
86 = ' ' 32
87 = ' ' 32
88 = ' ' 32
nextToken(89,92)=|int|
Token.INT
89 = 'i' 105
90 = 'n' 110
91 = 't' 116
processWhitespace(92,93)=| |
92 = ' ' 32
nextToken(93,94)=|a|
Token.IDENTIFIER
93 = 'a' 97
nextToken(94,95)=|;|
Token.SEMI
94 = ';' 59
processTerminator(95,97)=||
95 = '\r' 13
96 = '\n' 10
processWhitespace(97,101)=| |
97 = ' ' 32
98 = ' ' 32
99 = ' ' 32
100 = ' ' 32
nextToken(101,104)=|int|
Token.INT
101 = 'i' 105
102 = 'n' 110
103 = 't' 116
processWhitespace(104,105)=| |
104 = ' ' 32
nextToken(105,106)=|c|
Token.IDENTIFIER
105 = 'c' 99
processWhitespace(106,107)=| |
106 = ' ' 32
nextToken(107,108)=|=|
Token.EQ
107 = '=' 61
processWhitespace(108,109)=| |
108 = ' ' 32
nextToken(109,110)=|a|
Token.IDENTIFIER
109 = 'a' 97
processWhitespace(110,111)=| |
110 = ' ' 32
nextToken(111,112)=|+|
Token.PLUS
111 = '+' 43
processWhitespace(112,113)=| |
112 = ' ' 32
nextToken(113,114)=|1|
Token.INTLITERAL
113 = '1' 49
nextToken(114,115)=|;|
Token.SEMI
114 = ';' 59
processTerminator(115,117)=||
115 = '\r' 13
116 = '\n' 10
nextToken(117,118)=|}|
Token.RBRACE
117 = '}' 125
processTerminator(118,120)=||
118 = '\r' 13
119 = '\n' 10
nextToken(120,120)=||
120 = '\u001A' 26
121 = '\u0000' 0
122 = '\u0000' 0
123 = '\u0000' 0
124 = '\u0000' 0
125 = '\u0000' 0
126 = '\u0000' 0
127 = '\u0000' 0
128 = '\u0000' 0
129 = '\u0000' 0
(2)通过调用treeMaker的TopLevel()方法来创建JCCompilationUnit节点,其TopLevel()方法的具体实现如下:
/**
* Create given tree node at current position.
* @param defs a list of ClassDef, Import, and Skip
*/
public JCCompilationUnit TopLevel(List<JCAnnotation> packageAnnotations,
JCExpression pid,
List<JCTree> defs) {
Assert.checkNonNull(packageAnnotations);
for (JCTree node : defs) {
// cond/msg
Assert.check(node instanceof JCClassDecl
|| node instanceof JCImport
|| node instanceof JCSkip
|| node instanceof JCErroneous
|| (node instanceof JCExpressionStatement && ((JCExpressionStatement) node).expr instanceof JCErroneous),
node.getClass().getSimpleName());
}
JCCompilationUnit tree = new JCCompilationUnit(packageAnnotations, pid, defs,
null, null, null, null);
tree.pos = pos;
return tree;
}
(3)调用parserFactory类的newParser()工厂方法生成一个Parser类单实例对象,然后调用parseCompilationUnit()方法,其源代码如下:
/** CompilationUnit =
* [ { "@" Annotation } PACKAGE Qualident ";"]
* {ImportDeclaration}
* {TypeDeclaration}
*/
public JCCompilationUnit parseCompilationUnit() {
int pos = S.pos();
JCExpression pid = null;
String dc = S.docComment();
JCModifiers mods = null;
List<JCAnnotation> packageAnnotations = List.nil();
if (S.token() == MONKEYS_AT) // @ 符号
mods = modifiersOpt(); // 解析修饰符
if (S.token() == PACKAGE) { // 解析package声明
if (mods != null) {
checkNoMods(mods.flags);
packageAnnotations = mods.annotations;
mods = null;
}
S.nextToken();
pid = qualident();
accept(SEMI); // 分号
}
ListBuffer<JCTree> defs = new ListBuffer<JCTree>();
boolean checkForImports = true;
while (S.token() != EOF) {
if (S.pos() <= errorEndPos) {
// error recovery
// 跳过错误字符
skip(checkForImports, false, false, false);
if (S.token() == EOF)
break;
}
if (checkForImports && mods == null && S.token() == IMPORT) {
defs.append(importDeclaration()); // 解析import声明
} else { // 解析class类主体
JCTree def = typeDeclaration(mods);
if (keepDocComments && dc != null && docComments.get(def) == dc) {
// If the first type declaration has consumed the first doc
// comment, then don't use it for the top level comment as well.
// 如果在前面的类型声明中已经解析过了,那么在top level中将不再重复解析
dc = null;
}
if (def instanceof JCExpressionStatement)
def = ((JCExpressionStatement)def).expr;
defs.append(def);
if (def instanceof JCClassDecl)
checkForImports = false;
mods = null;
}
}
JCCompilationUnit toplevel = F.at(pos).TopLevel(packageAnnotations, pid, defs.toList());
attach(toplevel, dc);
if (defs.elems.isEmpty())
storeEnd(toplevel, S.prevEndPos());
if (keepDocComments)
toplevel.docComments = docComments;
if (keepLineMap)
toplevel.lineMap = S.getLineMap();
return toplevel;
}
Javac词法分析的更多相关文章
- javac的词法分析
1.词法分析将Java源文件的字符流转变为对应的Token流. JavacParser类规定了哪些词是符合Java语言规范规定的词,而具体读取和归类不同词法的操作由Scanner类来完成. ...
- javac 编译与 JIT 编译
编译过程 不论是物理机还是虚拟机,大部分的程序代码从开始编译到最终转化成物理机的目标代码或虚拟机能执行的指令集之前,都会按照如下图所示的各个步骤进行: 其中绿色的模块可以选择性实现.很容易看出,上图中 ...
- Javac早期(编译期)
从Sun Javac的代码来看,编译过程大致可以分为3个过程: 解析与填充符号表过程. 插入式注解处理器的注解处理过程. 分析与字节码生成过程. Javac编译动作的入口是com.sun.tools. ...
- javac编译过程
编译器把一种语言规范转化为另一种语言规范的这个过程需要哪些步骤:
- Javac编译和JIT编译
编译过程 不论是物理机还是虚拟机,大部分的程序代码从开始编译到最终转化成物理机的目标代码或虚拟机能执行的指令集之前,都会按照如下图所示的各个步骤进行: 其中绿色的模块可以选择性实现.很容易看出,上图中 ...
- javac编译原理(一)
我们都知道,计算机只能识别二进制语言,是不能直接识别java c c++等高级语言的.将高级语言转化成计算机可以是别的二进制语言,这个过程就叫编译. 有次面试,面试官问了一道“java的编译原理是什么 ...
- Javac编译与JIT编译
本文转载自:http://blog.csdn.net/ns_code/article/details/18009455 编译过程 不论是物理机还是虚拟机,大部分的程序代码从开始编译到最终转化成物理机的 ...
- 【深入Java虚拟机】之七:Javac编译与JIT编译
转载请注明出处:http://blog.csdn.net/ns_code/article/details/18009455 编译过程 不论是物理机还是虚拟机,大部分的程序代码从开始编译到最终转化成物理 ...
- Javac 编译原理
写在前面 JDK & JRE JRE(Java Runtime Enviroment)是Java的运行环境.面向Java程序的使用者,而不是开发者.如果你仅下载并安装了JRE,那么你的系统只 ...
随机推荐
- Could not load file or assembly 'System.Data.SQLite ... 试图加载格式不正确的程序
坑爹的System.Data.SQLite. 先给出下载地址:http://system.data.sqlite.org/index.html/doc/trunk/www/downloads.wiki ...
- 别做HR最讨厌的求职者
有些求职者认为自己各方面都与所应聘的职位要求相匹配,因此在被淘汰之后总是特别不解,努力回忆起每个面试环节,却始终找不到原因.是的,也许你真的很优秀,但是你被淘汰了,原因也许并不大,只是你得罪了HR.其 ...
- dxbarmanager生成传统下拉式样的菜单
传统菜单 //创建一个dxSubItem,相当于创建一个主菜单项 dxBarSubItem := TdxBarSubItem.Create(Self); dxBarSubItem.Caption := ...
- Easy mistakes in c#
ACCESS MODIFIERS c# has some access modifiers as below: public:class or member can be accessed by no ...
- Java ActiveMQ 讲解(一)理解JMS 和 ActiveMQ基本使用
最近的项目中用到了mq,之前自己一直在码农一样的照葫芦画瓢.最近几天研究了下,把自己所有看下来的文档和了解总结一下. 一. 认识JMS 1.概述 对于JMS,百度百科,是这样介绍的:JMS即Java消 ...
- 用.msi安装node时安装失败,出现rolling back action(转载)
转载地址:https://blog.csdn.net/qq_33295622/article/details/52956369在重装node时出现了上图所示情况,解决方法如下: 1.在官网下载稳定版本 ...
- sqlcmd 执行SQL语句或没有足够的内存来执行脚本
win+r命令提示框里面输入cmd sqlcmd -S . -U username -P password -d database -i url -S 数据库地址 -U 登录名称 -P 密码 -d 数 ...
- docker-compose 部署 Redis
信息: Docker版本($ docker --version):Docker版本18.06.1-ce,版本e68fc7a 系统信息($ cat /etc/centos-release):CentOS ...
- 【C#】在datatable中添加一序号列,编号从1依次递增,并且在第一列
详细链接:https://shop499704308.taobao.com/?spm=a1z38n.10677092.card.11.594c1debsAGeak/// <summary> ...
- pageadmin CMS Sql Server2008 R2数据库安装教程
sql sever数据库建议安装sql2008或以上版本,如果电脑上没有安装数据库,参考下面步骤安装. sql2008 r2下载地址:点击下载 提取码: wfb4 下载后点击安装文件,安装步骤如下 ...