MapReduce编程:平均成绩
问题描述
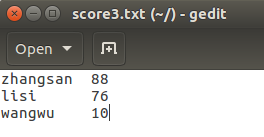
现在有三个文件分别代表学生的各科成绩,编程求各位同学的平均成绩。


编程思想
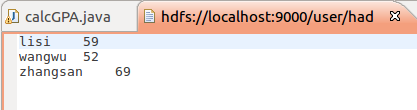
map函数将姓名作为key,成绩作为value输出,reduce根据key即可将三门成绩相加。
代码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class calcGPA {
public calcGPA() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String fileAddress = "hdfs://localhost:9000/user/hadoop/"; //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs = new String[]{fileAddress+"score1.txt", fileAddress+"score2.txt", fileAddress+"score3.txt", fileAddress+"output"};
if(otherArgs.length < 2) {
System.err.println("Usage: calcGPA <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "calc GPA");
job.setJarByClass(calcGPA.class);
job.setMapperClass(calcGPA.TokenizerMapper.class);
job.setCombinerClass(calcGPA.IntSumReducer.class);
job.setReducerClass(calcGPA.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public IntSumReducer() {
} public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0; IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get(),count++) {
val = (IntWritable)i$.next();
} int average = (int)sum/count;
context.write(key, new IntWritable(average));
}
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { public TokenizerMapper() {
} public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), "\n"); while(itr.hasMoreTokens()) {
StringTokenizer iitr = new StringTokenizer(itr.nextToken());
String name = iitr.nextToken();
String score = iitr.nextToken();
context.write(new Text(name), new IntWritable(Integer.parseInt(score)));
} }
}
}
疑问
在写这个的时候,我遇到个问题,就是输入输出文件的默认地址,为什么是user/hadoop/,我看了一下配置文件的信息,好像也没有出现过这个地址啊,希望有人能解答一下,万分感谢。
MapReduce编程:平均成绩的更多相关文章
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- mapreduce实现学生平均成绩
思路: 首先从文本读入一行数据,按空格对字符串进行切割,切割后包含学生姓名和某一科的成绩,map输出key->学生姓名 value->某一个成绩 然后在reduce里面对成绩进行遍历 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
随机推荐
- SQL 资源整理
https://linux.linuxidc.com/index.php 资源链接:linux.linuxidc.com SQL必知必会(第4版)是SQL经典畅销书,内容丰富,简洁实用.本书是麻省理工 ...
- [Database.System.Concepts(6th.Edition.2010)].Abraham.Silberschatz. Ch8学习笔记
Database Ch8.relational design 8.1 features of good design 8.1.1 larger alternatives why design is g ...
- CoreData 执行executefetchrequest卡死解决办法
在大量使用GCD和block以后发现程序会卡死在executefetchrequest执行. 反复测试无果.添加锁也无效.想来想去没发现问题. 容忍了就当人品问题.2天以后实在忍无可忍. 替换perf ...
- Redis入门到高可用(十五)—— GEO
一.简介 二.应用场景 三.API 1.geoadd 2.geopos 3.geodist 4.georadius 四.相关说明
- spring 事务注解
在spring中使用事务需要遵守一些规范和了解一些坑点,别想当然.列举一下一些注意点. 在需要事务管理的地方加@Transactional 注解.@Transactional 注解可以被应用于接口定义 ...
- 【JVM】-NO.113.JVM.1 -【JDK11 HashMap详解-0-全局-put】
Style:Mac Series:Java Since:2018-09-10 End:2018-09-10 Total Hours:1 Degree Of Diffculty:5 Degree Of ...
- cocos2d-x JS 各类点、圆、矩形之间的简单碰撞检测
这里总结了一下点.圆.矩形之间的简单碰撞检测算法 (ps:矩形不包括旋转状态) 点和圆的碰撞检测: 1.计算点和圆心的距离 2.判断点与圆心的距离是否小于圆的半 isCollision: functi ...
- 详解C# 网络编程系列:实现类似QQ的即时通信程序
https://www.jb51.net/article/101289.htm 引言: 前面专题中介绍了UDP.TCP和P2P编程,并且通过一些小的示例来让大家更好的理解它们的工作原理以及怎样.Net ...
- 构建高性能的MYSQL数据库系统-主从复制
实验环境: DB1:172.16.1.100 DB2:172.16.1.101 VRRIP:172.16.1.99 步骤: yum -y install mysql 1.修改DB1的mysql配置文件 ...
- 第二篇——Struts2的Action搜索顺序
Struts2的Action的搜索顺序: 地址:http://localhost:8080/path1/path2/student.action 1.判断package是否存在,例如:/pat ...