MapReduce编程:平均成绩
问题描述
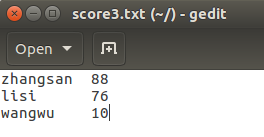
现在有三个文件分别代表学生的各科成绩,编程求各位同学的平均成绩。


编程思想
map函数将姓名作为key,成绩作为value输出,reduce根据key即可将三门成绩相加。
代码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class calcGPA {
public calcGPA() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String fileAddress = "hdfs://localhost:9000/user/hadoop/"; //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs = new String[]{fileAddress+"score1.txt", fileAddress+"score2.txt", fileAddress+"score3.txt", fileAddress+"output"};
if(otherArgs.length < 2) {
System.err.println("Usage: calcGPA <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "calc GPA");
job.setJarByClass(calcGPA.class);
job.setMapperClass(calcGPA.TokenizerMapper.class);
job.setCombinerClass(calcGPA.IntSumReducer.class);
job.setReducerClass(calcGPA.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public IntSumReducer() {
} public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0; IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get(),count++) {
val = (IntWritable)i$.next();
} int average = (int)sum/count;
context.write(key, new IntWritable(average));
}
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { public TokenizerMapper() {
} public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), "\n"); while(itr.hasMoreTokens()) {
StringTokenizer iitr = new StringTokenizer(itr.nextToken());
String name = iitr.nextToken();
String score = iitr.nextToken();
context.write(new Text(name), new IntWritable(Integer.parseInt(score)));
} }
}
}
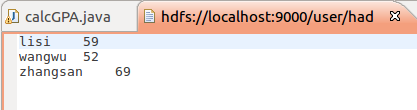
疑问
在写这个的时候,我遇到个问题,就是输入输出文件的默认地址,为什么是user/hadoop/,我看了一下配置文件的信息,好像也没有出现过这个地址啊,希望有人能解答一下,万分感谢。
MapReduce编程:平均成绩的更多相关文章
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- mapreduce实现学生平均成绩
思路: 首先从文本读入一行数据,按空格对字符串进行切割,切割后包含学生姓名和某一科的成绩,map输出key->学生姓名 value->某一个成绩 然后在reduce里面对成绩进行遍历 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
随机推荐
- Tanya and Candies
Tanya and Candies time limit per test 1 second memory limit per test 256 megabytes input standard in ...
- .NET Core开发日志——OData
简述 OData,即Open Data Protocol,是由微软在2007年推出的一款开放协议,旨在通过简单.标准的方式创建和使用查询式及交互式RESTful API. 类库 在.NET Core中 ...
- pytorch-MNIST数据模型测试
用pytorch搭建一个DNN网络,主要目的是熟悉pytorch的使用 """ test Function """ import torch ...
- Spring Boot 你所不知道的超级知识学习路线清单
因而 Spring Boot 应用本质上就是一个基于 Spring 框架的应用,它是 Spring 对“约定优先于配置”理念的最佳实践产物,它能够帮助开发者更快速高效地构建基于 Spring 生态圈的 ...
- C/S和B/S的应用的区别
C/S: C是指Client,S是指Server.C/S模式就是指客户端/服务器模式.通过它可以充分利用两端硬件环境的优势,将任务合理分配到Client端和Server端来实现,降低了系统的通讯开销. ...
- c++代码检测工具
cppcheck是一款静态代码检查工具,可以检查如内存泄漏等代码错误,使用起来比较简单,即提供GUI界面操作,也可以与VS开发工具结合使用. 1.安装 一般会提供免安装版,安装完成后将cppcheck ...
- vue 之 筛选功能实现
要实现的效果如下:根据输入框里面输入的内容筛选下面列表: 推荐实现代码如下:其中 allProductData 就是用来下拉列表的数据,allProductList 为从获取的所有列表的数据:
- 关于for循环
1.普通for循环 (遍历数组的索引值(下标),边界可以自己划定) var arr = [10, 20, 30];for(var i=0; i<arr.length; i++) console. ...
- Spring 学习教程(一):浅谈对Spring IOC以及DI的理解
一.个人对IoC(控制反转)和DI(依赖注入)的理解我们平时在开发java web程序的时候,每个对象在需要使用它的合作对象时,自己都要将它要合作对象创建出来(比如 new 对象),这个合作对象是由自 ...
- 十、无事勿扰,有事通知(1)——NSNotification
概述 很久很久以前,有一只菜鸟正在美滋滋的撸着他的嵌入式C代码.然而有一天,老板对菜鸟说:“别撸C了,从现在开始你就写swift开发ios了.”菜鸟一脸懵逼,但还是照做了. 又有一天,菜蛋谄媚的对菜鸟 ...