深入学习使用ocr算法识别图片中文字的方法
公司有个需求,简单点说需要从一张图片中识别出中文,通过python来实现,当然其他程序也行,只要能实现,而小编主要学习python,所以就提了python。一个小白在网上遨游了一天,终于找到一丝丝思绪,特意在此分享,希望大神提出宝贵的意见。
今天还是在学习OCR算法中,但是好像自己摸索确实比较难一点,而且python实现图片中文识别的方法还是不多,所以我打算记录一下自己学习的过程。今天看到一个菜鸟都可以用的开源项目,那就是OCR开源项目tesseract,可能对于还是菜鸟的我来说,最好不过了,可以试试此项目,还可以看看源码,何乐而不为呢!
OCR开源项目很多,给大家一个链接,这个链接列出了现有的比较出名的OCR开源项目,链接如下:
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
从上面的排名可以看到,Tesseract是排在第一名的!所以下面就认真学习一下Tesseract。首先介绍一下Tesseract,然后安装,测试,了解其不足等等。
Tesseract的OCR引擎目前已作为开源项目发布在Google Project,
其项目主页在这里查看https://github.com/tesseract-ocr, 它支持中文OCR,并提供了一个命令行工具。python中对应的包是
pytesseract. 通过这个工具我们可以识别图片上的文字。
一 Tesseract的安装测试使用
1.1 小编的开发环境如下:
- windows 7
- python 3.6
- pycharm
1.2 下载安装包
首先下载Tesseract在Windows下的安装版。(因为在国外访问不了谷歌,所以别人翻墙下载了下来,这里给大家百度网盘链接)
http://pan.baidu.com/s/1i56Uxlr
根据https://github.com/tesseract-ocr/tesseract/wiki,找到非官方的安装包,好像只看到64位的安装包 http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
安装python对应的包:pytesseract
pip install pytesseract
1.3 安装Tesseract
下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。(此处附上windows 4.0的安装过程)
既然是要训练中文,记得勾选 additional language data
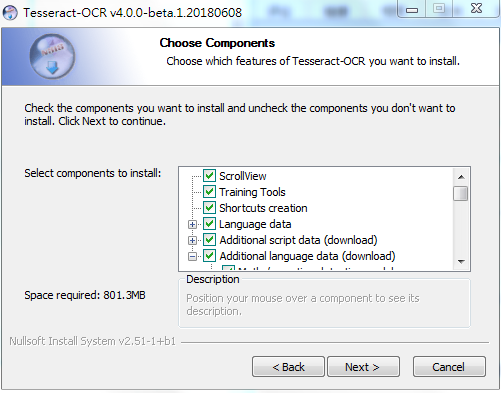
找到中文简体和中文繁体,按需勾选,然后点下一步
可以先不勾选,因为这样直接下载语言的包实在太慢。可以从网页上直接下载语言包,然后等程序安装好后,放入安装目录下tessdata目录下面
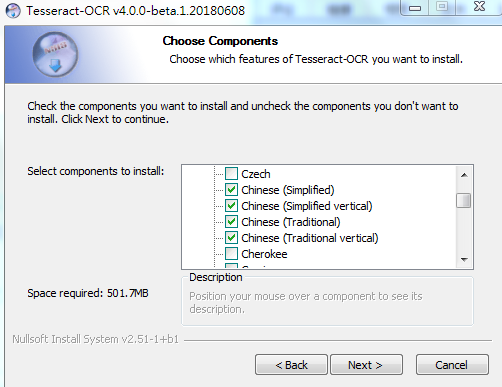
下载下来之后一路Next安装好,然后在开始菜单找到其控制台引导程序,如下图所示:
使用Tesseract ocr有两种方式:
动态库方式 libtesseract和执行程序方式 tesseract.exe 小编使用的是第二个方式,也方便Python调用(主要是小编比较菜)。
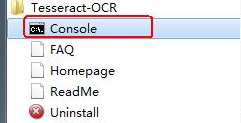
1.4 测试英文字符识别
上面的安装包里自带了已经训练好的英文-拉丁文识别数据~所以我们先来测试一下英文字符的识别吧~识别图像如下:
1.4.1 把上面的图片放到Tesseract的安装目录下,如下图所示:
1.4.2 打开上面提到的控制台窗口,如下图所示:

1.4.3 在窗口中输入命令:“tesseract.exe 0.jpg 1”,并回车,如下图所示:
01.jpg代表待识别的源文件,1代表输出文件名,默认输出格式是txt文件格式! 注意,上面的 lang之前是-l 而不是-1!

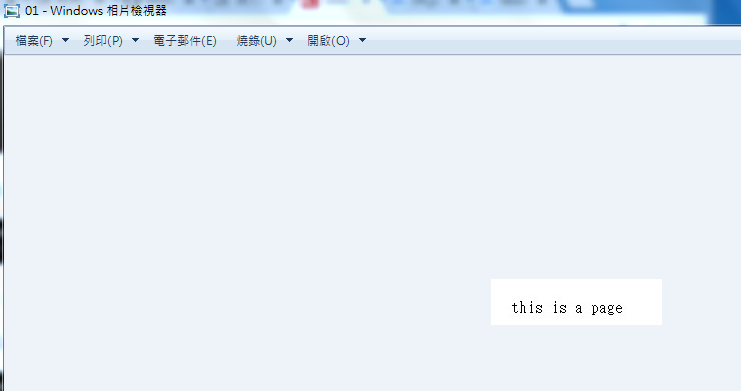
1.4.4 让我们先查看一下01.jpg照片,如下图:
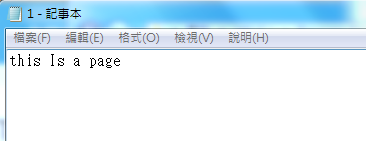
1.4.5 在安装目录下生成了1.txt文件,识别结果如下图所示:
既然安装好了,测试也可以了,我们就进行实战,做图像识别。
二 python用tesseract-ocr做图像识别
虽然说一行代码可以搞定识别图片,但是我们需要导入两个库,这是别人写好的封装好的库文件。只有导入人家库,我们才能识别一行代码实现图片文字。
- 这里我们需要用到两个库:pytesseract和PIL
- 同时我们还需要安装识别引擎tesseract-ocr
2.1 pytesseract和PIL的安装
安装这两个包可以借助pip
- 1,命令行安装
pip install PIL
pip install pytesseract - 2,如果你用的pycharm编辑器,就可以直接借助pycharm实现快速安装。
2.2 大概介绍下相关模块的概念:
Python-tesseract 是光学字符识别Tesseract OCR引擎的Python封装类。能够读取任何常规的图片文件(JPG, GIF ,PNG , TIFF等)并解码成可读的语言。在OCR处理期间不会创建任何临文件
PIL (Python Imaging Library)是 Python 中最常用的图像处理库,目前版本为 1.1.7,我们可以 在这里 下载学习和查找资料。
Image 类是 PIL 库中一个非常重要的类,通过这个类来创建实例可以有直接载入图像文件,读取处理过的图像和通过抓取的方法得到的图像这三种方法。
python对图像的处理比较常见的是用pytesseract识别验证码,要安装pytesseract库,必须先安装其依赖的PIL及tesseract-ocr,其中PIL为图像处理库,而后面的tesseract-ocr则为google的ocr识别引擎。
下载链接:http://www.waitalone.cn/python-php-ocr.html
该链接文档描述了如何配置相关环境,以及识别验证码的python代码,
总结起来就三步: 安装PIL.exe;
安装tesseract-ocr-setup.exe;
安装pip install pytesseract
2.3 解决python2.X中PIL在Python3.X中不能使用
目前PIL的官方最新版本为1.1.7,支持的版本为python 2.5, 2.6, 2.7,并不支持python3,经查询python3.X用pillow代替,进入DOS命令行窗口,敲入以下代码
pip install pillow
提示安装成功,再运行程序没有问题。
2.4 正式识别图片中的文字(包括简单的英文和复杂的英文)
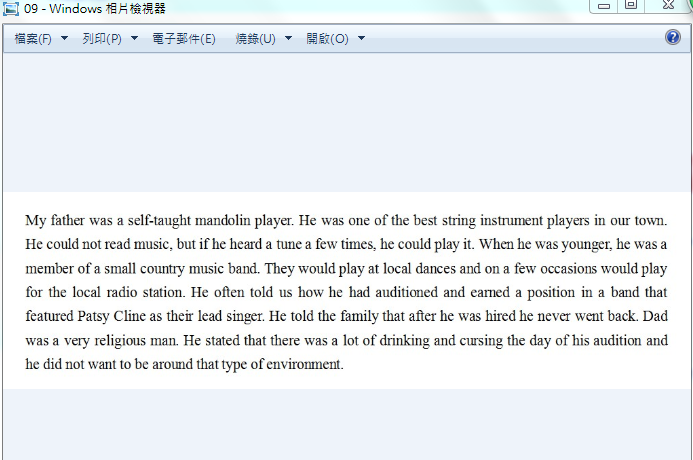
2.4.1 下面进入正题,我们识别下面的东西,看图(三种情况):
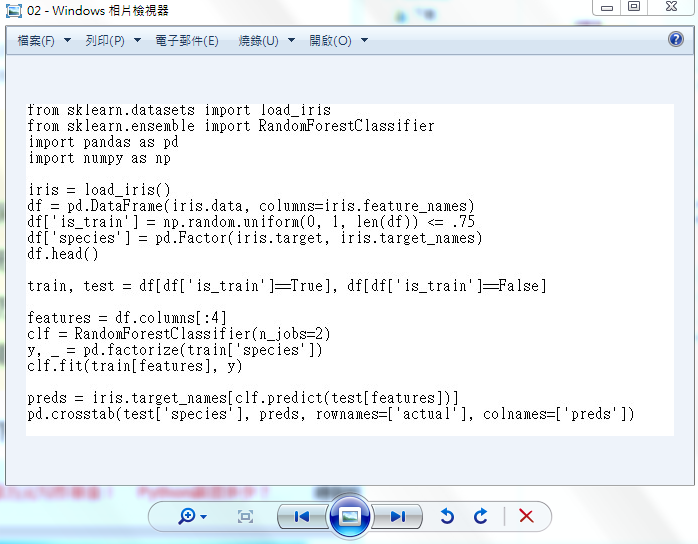
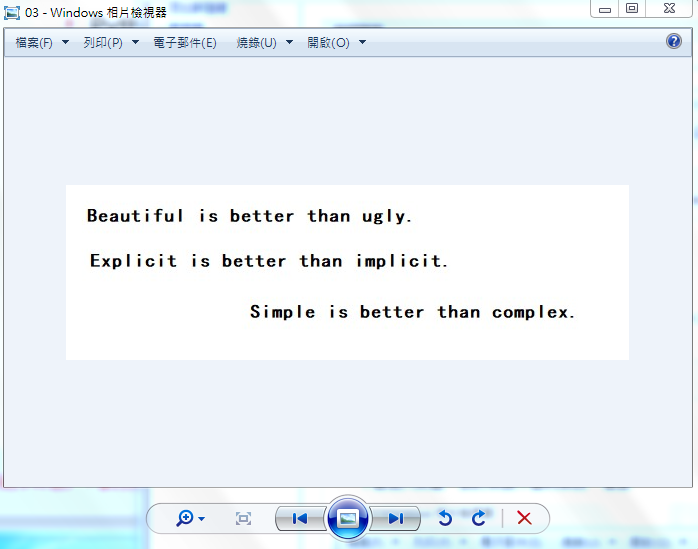
2.4.2 python代码如下:
import pytesseract
from PIL import Image #打开验证码图片
image = Image.open('02.jpg')
#加载一下图片防止报错,此处可以省略
image.load()
#调用show来展示图片,调试用此处可以省略
image.show()
text = pytesseract.image_to_string(Image.open('02.jpg'))
print(text)
2.4.3 查看运行结果,运行后,结果如下:

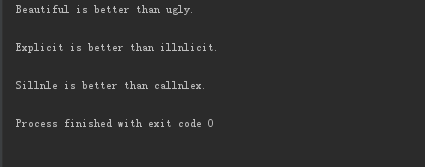
2.4.5 总结
从上面我们可以发现,运行代码后的结果, 清晰的印刷体字体比较清晰,基本没有问题。简单的图片识别率还是可以的,但是复杂的话 就...,所以希望自己继续学习,继续寻找有用的库。
三 Image模块的用法介绍(转)
3.1 简介
图像处理是一门应用非常广的技术,而拥有非常丰富第三方扩展库的 Python 当然不会错过这一门盛宴。PIL (Python Imaging Library)是 Python 中最常用的图像处理库,目前版本为 1.1.7,我们可以 在这里 下载学习和查找资料。
Image 类是 PIL 库中一个非常重要的类,通过这个类来创建实例可以有直接载入图像文件,读取处理过的图像和通过抓取的方法得到的图像这三种方法。
3.2 使用
导入 Image 模块。然后通过 Image 类中的 open 方法即可载入一个图像文件。如果载入文件失败,则会引起一个 IOError ;若无返回错误,则 open 函数返回一个 Image 对象。现在,我们可以通过一些对象属性来检查文件内容,即:
1 >>> import Image
2 >>> im = Image.open("j.jpg")
3 >>> print im.format, im.size, im.mode
4 JPEG (440, 330) RGB
这里有三个属性,我们逐一了解。
format : 识别图像的源格式,如果该文件不是从文件中读取的,则被置为 None 值。
size : 返回的一个元组,有两个元素,其值为象素意义上的宽和高。
mode : RGB(true color image),此外还有,L(luminance),CMTK(pre-press image)。
3.3 简单的几何变化
色彩空间变换。
convert() : 该函数可以用来将图像转换为不同色彩模式。
图像增强。
Filters : 在 ImageFilter 模块中可以使用 filter 函数来使用模块中
一系列预定义的增强滤镜。
>>>out = im.resize((128, 128)) >>>out = im.rotate(45) #逆时针旋转 45 度角。 >>>out = im.transpose(Image.FLIP_LEFT_RIGHT) #左右对换。 >>>out = im.transpose(Image.FLIP_TOP_BOTTOM) #上下对换。 >>>out = im.transpose(Image.ROTATE_90) #旋转 90 度角。 >>>out = im.transpose(Image.ROTATE_180) #旋转 180 度角。 >>>out = im.transpose(Image.ROTATE_270) #旋转 270 度角。
深入学习使用ocr算法识别图片中文字的方法的更多相关文章
- 在Mac上 python中使用tesseract OCR (Pytesser) 识别图片中的文字
仓库地址:https://github.com/RobinDavid/Pytesser brew install tesseract sudo pip install opencv-python 安装 ...
- 识别图片中文字(百度AI)
这个是百度官方的文档 https://ai.baidu.com/docs#/OCR-API/top 通用的文字识别,如果是其他的含生僻字/含位置信息的版本,请参考官方的文档,只 ...
- C#调用OCR组件识别图片文字
图片识别的技术到几天已经很成熟了,只是相关的资料很少,为了方便在此汇总一下(C#实现),方便需要的朋友查阅,也给自己做个记号. 图片识别的用途:很多人用它去破解网站的验证码,用于达到自动刷票或者是批量 ...
- Scrapy学习-15-降低被识别为爬虫的方法
3种常见的方法 1. 在settings中配置禁用cookies COOKIES_ENABLED = False 2. scrapy限速处理,scrapy为我们提供了扩展模块,它能动态的限制下载速度 ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 18—Photo OCR 应用实例:图片文字识别
Lecture 18—Photo OCR 应用实例:图片文字识别 18.1 问题描述和流程图 Problem Description and Pipeline 图像文字识别需要如下步骤: 1.文字侦测 ...
- PC端车牌识别朱凯茵从事图像识别算法、OCR算法
大家好,我是从事图像识别的pc端车牌识别朱凯茵,多多交流OCR算法,不限于车牌识别等,技术需要突破,你我成就梦想.
- Python通过百度Ai识别图片中的文字
版本:python3.7 工作中有需要识别图片中的汗字,查看了半天大神们的博客,但没找到完全可以用的源码,经过自己的实践,以下源码可以实现: 创建应用 首先你需要登录百度AI,选择文字识别,创建一个应 ...
随机推荐
- vs [失败]未能找到文件
用文本文件打开csproj 文件.将里面的不需要文件删除; 或者在工程里面先将其移出工程.然后再删除;
- Docker Hello World
Docker 允许你在容器内运行应用程序,使用docker run命令来在容器内运行一个个应用程序. 输出Hello World docker run ubuntu:15.10 ./bin/echo ...
- Spring 框架下 (增 删 改 )基本操作
//applicationContext.xml 配置文件 <?xml version="1.0" encoding="UTF-8"?><be ...
- Arrays工具类和Collections工具类
集合知识点总结 Arrays工具类 .binarySearch() .sort() .fill() //填充 int[] array = new int[10]; Arrays.fill(array, ...
- 【转】《深入理解C# 3.x的新特性》博文系列汇总
[转]<深入理解C# 3.x的新特性>博文系列汇总 较之C# 2.0, C# 3.x引入了一系列新的特性,为我们编程带来很大的便利,通过有效地利用这些新特性,我们可以编写出更加简洁.优雅的 ...
- Integer 与int的区别
1.在的model的时候很多喜欢用int 类型 但是最好用Integer类型因为在查询的时候如果返回不到数据 Model就会报这个类是空的 所以应该尽量选用interger
- 去掉手机端延迟300ms
手机端300ms延迟是由于在手机上可以双击可以放大缩小造成的,当初ios苹果的工程师们做了一些约定,应对 iPhone 这种小屏幕浏览桌面端站点的问题.这就是手机端300ms延迟的由来. 解决:我是用 ...
- Python Day 14 迭代器、for循环原理、枚举、生成器
阅读内容 内容回顾 带参装饰器和wraps用法 迭代器知识引入 可迭代对象 迭代器对象 for循环迭代器 枚举对象 生成器 ##内容回顾 函数的嵌套定义:在函数内部定义另一 ...
- sql server常用字符串函数
--返回字符表达式中最左侧字符的ASCII代码值 --将整数ASCII代码转换为字符 )--a )--A ')--A SELECT CHAR('A')--在将 varchar 值 'A' 转换成数据类 ...
- 利用UML语言建模--以图书馆管理系统为例
一.基本信息 标题:利用UML语言建模--以图书馆管理系统为例 时间:2016 出版源:内蒙古科技与经济 领域分类:UML:RFID:图书馆:模型: 二.研究背景 问题定义:建立图书馆管理系统 难点: ...