OpenStack的HA方案
一.HA服务分类
HA将服务分为两类:
- 有状态服务:后续对服务的请求依赖之前对服务的请求,OpenStack中有状态的服务包括MySQL数据库和AMQP消息队列。对于有状态类服务的HA,如neutron-l3-agent,neutron-metadata-agent、nova-compute,cinder-volume等服务,最简单的方法就是多节点部署。比如某一节点的nova-compute服务挂了,也并不会影响整个云平台不能创建虚拟机,或者所在节点的虚拟机无法使用。(比如ssh等)
- 无状态服务:对服务的请求之间没有依赖关系,是完全对立的。基于冗余实例和负载均衡实现HA,OpenStack中无状态的服务包括nova-api,nova-conductor,glance-api,keystone-api,neutron-api,nova-scheduler等。由于API服务,属于无状态类服务,天然支持Active/Active HA模式。因此,一般使用keepalived +HAProxy方案来做。
二.HA的类型
HA的类型:
HA需要使用冗余的服务器组成集群来运行负载,包括应用和服务,这种冗余性也可以将HA分为两类:
- Active/Passive HA:即主备HA,在这种配置下,系统采用主和备用机器来提供服务。系统只在主设备上提供服务,在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型的可以采用CRM软件比如Pacemaker来控制主备设备之间的切换,并提供一个虚拟机IP来提供服务。
- Avtive/Active HA:即主主HA,包括多节点时成为多主,在这种配置下,系统在集群内所有服务器上运行同样的负载,以数据库为例,对于一个实例的更新,会被同步到所有实例上,这种配置下往往采用负载均衡软件,比如HAProxy来提供服务的虚拟IP
三.OpenStack云环境的高可用(HA)
云环境时一个广泛的系统,包括了基础设施层,OpenStack云平台服务层,虚拟机和最终用户应用层。
云环境的HA包括:
- 用于应用的HA
- 虚拟机的HA
- OpenStack云平台服务的HA
- 基础设施层的HA:电力,空调和防火设施,网络设备(如交换机、路由器)、服务器设备和存储设备等。
OpenStack HA架构:
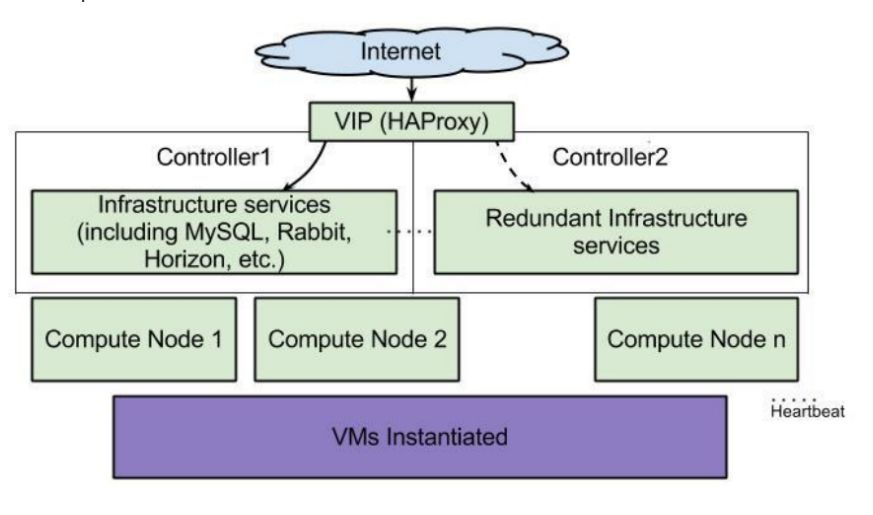
如果从部署层面来划分,OpenStack高可用的内容包括:
- 控制节点(RabbitMQ、Mariadb、Keystone、Nova-API等)
- 网络节点(neutron_dhcp_agent、neutron_l3_agent、neutron_openvswitch_agent等)
- 计算节点(nova-compute、neutron_openvswitch_agent、虚拟机等)
存储节点 (cinder-volume、swift等)
控制节点HA:
在生产环境中,建议至少部署三台控制节点,其余可做计算节点、网络节点、或存储节点。采用HAProxy + KeepAlived的方式,代理数据库服务和OpenStack服务,对外包括VIP提供API访问。
- RabbitMQ消息队列HA:
RabbitMQ采用原生Cluster集群方案,所有节点同步镜像队列。小规模环境中,三台物理机,其中2个Mem节点主要提供服务,1个Disk节点用于持久化消息,客户端根据需求分别配置主从策略。据说使用ZeroMQ代替默认的RabbitMQ有助于提升集群消息队列性能。
- OpenStack API服务HA:
OpenStack控制节点上运行的基本上是API 无状态类服务,如nova-api、neutron-server、glance-registry、nova-novncproxy、keystone等。因此,可以由 HAProxy 提供负载均衡,将请求按照一定的算法转到某个节点上的 API 服务,并由KeepAlived提供 VIP。
- 网络节点HA:
网络节点上运行的Neutron服务包括很多的组件,比如 L3 Agent,openvswitch Agent,LBaas,VPNaas,FWaas,Metadata Agent 等,其中部分组件提供了原生的HA 支持。
• Openvswitch Agent HA: openvswitch agent 只在所在的网络或者计算节点上提供服务,因此它是不需要HA的
• L3 Agent HA:成熟主流的有VRRP 和DVR两种方案
• DHCP Agent HA:在多个网络节点上部署DHCP Agent,实现HA
• LBaas Agent HA:Pacemaker + 共享存储(放置 /var/lib/neutron/lbaas/ 目录) 的方式来部署 A/P 方式的 LBaas Agent HA
- 存储节点HA
存储节点的HA,主要是针对cinder-volume、cinder-backup服务做HA,最简便的方法就是部署多个存储节点,某一节点上的服务挂了,不至于影响到全局。
- 计算节点和虚拟机 HA
计算节点和虚拟机的HA,社区从2016年9月开始一直致力于一个虚拟机HA的统一方案,但目前仍然没有一个成熟的方案。实现计算节点和虚拟机HA,要做的事情基本有三件,即。
① 监控
监控主要做两个事情,一个是监控计算节点的硬件和软件故障。第二个是触发故障的处理事件,也就是隔离和恢复。
OpenStack 计算节点高可用,可以用pacemaker和pacemaker_remote来做。使用pacemaker_remote后,我们可以把所有的计算节点都加入到这个集群中,计算节点只需要安装pacemaker_remote即可。pacemaker集群会监控计算节点上的pacemaker_remote是否 “活着”,你可以定义什么是“活着”。比如在计算节点上监控nova-compute、neutron-ovs-agent、libvirt等进程,从而确定计算节点是否活着,亦或者租户网络和其他网络断了等。如果监控到某个pacemaker_remote有问题,可以马上触发之后的隔离和恢复事件。
② 隔离
隔离最主要的任务是将不能正常工作的计算节点从OpenStack集群环境中移除,nova-scheduler就不会在把create_instance的message发给该计算节点。
Pacemaker 已经集成了fence这个功能,因此我们可以使用fence_ipmilan来关闭计算节点。Pacemaker集群中fence_compute 会一直监控这个计算节点是否down了,因为nova只能在计算节点down了之后才可以执行host-evacuate来迁移虚拟机,期间等待的时间稍长。这里有个更好的办法,就是调用nova service-force-down 命令,直接把计算节点标记为down,方便更快的迁移虚拟机。
③ 恢复
恢复就是将状态为down的计算节点上的虚拟机迁移到其他计算节点上。Pacemaker集群会调用host-evacuate API将所有虚拟机迁移。host-evacuate最后是使用rebuild来迁移虚拟机,每个虚拟机都会通过scheduler调度在不同的计算节点上启动。
当然,还可以使用分布式健康检查服务Consul等。
OpenStack的HA方案的更多相关文章
- OpenStack Mitaka HA部署方案(随笔)
[Toc] https://github.com/wanstack/AutoMitaka # 亲情奉献安装openstack HA脚本 使用python + shell,完成了基本的核心功能(纯二层的 ...
- openStack灾备方案说明
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1) OpenStack 高可用方案概述 (2) Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3 ...
- ActiveMQ笔记(3):基于Networks of Brokers的HA方案
上一篇介绍了基于ZK的ActiveMQ HA方案,虽然理解起来比较容易,但是有二个不足: 1) 占用的节点数过多,1个zk集群至少3个节点,1个activemq集群也至少得3个节点,但其实正常运行时 ...
- ActiveMQ笔记(2):基于ZooKeeper的HA方案
activemq官网给出了3种master/slave的HA方案,详见:http://activemq.apache.org/masterslave.html,基于共享文件目录,db,zookeepe ...
- MySQL HA方案之MySQL半复制+MHA+Keepalived+Atlas+LVS[转]
MySQL HA方案之MySQL半复制+MHA+Keepalived+Atlas+LVS 简介 目前Mysql高可用的方案有好多,比如MMM,heartbeat+drbd,Cluster等,还有per ...
- hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案
我们知道hadoop1.x之前的namenode存在两个主要的问题:1.namenode内存瓶颈的问题,2.namenode的单点故障的问题.针对这两个问题,hadoop2.x都对它进行改进和解决.其 ...
- 基于Networks of Brokers的HA方案
上一篇介绍了基于ZK的ActiveMQ HA方案,虽然理解起来比较容易,但是有二个不足: 1) 占用的节点数过多,1个zk集群至少3个节点,1个activemq集群也至少得3个节点,但其实正常运行时 ...
- openstack controller ha测试环境搭建记录(一)——操作系统准备
为了初步了解openstack controller ha的工作原理,搭建测试环境进行学习. 在学习该方面知识时,当前采用的操作系统版本是centos 7.1 x64.首先在ESXi中建立2台用于测试 ...
- Hadoop HA方案调研
原文成文于去年(2012.7.30),已然过去了一年,很多信息也许已经过时,不保证正确,与Hadoop学习笔记系列一样仅为留做提醒. ----- 针对现有的所有Hadoop HA方案进行调研,以时间为 ...
随机推荐
- IRC 打字交流
kali 里面用 apt-get install weechat 安装完成后,输入 weechat 命令就能启动客户端了 要想使用 IRC,就需要先连接一个 irc 服务器,选择了大名鼎鼎的 chat ...
- JS构造函数原理与原型
1.创建对象有以下几种方式: ①.var obj = {}; ②.var obj = new Object(); ③.自定义构造函数,然后使用构造函数创建对象 [构造函数和普通函数的区别:函数名遵循大 ...
- 浅谈react的初步试用
现在最热门的前端框架,毫无疑问是 React . 上周,基于 React 的 React Native 发布,结果一天之内,就获得了 5000 颗星,受瞩目程度可见一斑. React 起源于 Face ...
- mysql(5.7以上)查询报错:ORDER BY clause is not in GROUP BY..this is incompatible with sql_mode=only_full_group_by
执行mysql命令查询时: select * from table_name错误信息如: [Err] 1055 - Expression #1 of ORDER BY clause is not in ...
- 《CSS世界》读书笔记(六)
<!-- <CSS世界> 张鑫旭著 --> min-width/max-width和min-height/max-height min-width/max-width出现的场景 ...
- Python socket网络编程(通信介绍)
socket通信介绍 通信介绍(一) 1.所有网络协议的基础就是:socket 2.socket对TCP与UDP协议封装,让用户进行简单操作. 3.socket只做两件事:发 send,收 rec ...
- Mysql 集合链接查询
MySQL NULL 值处理 需求:我们已经知道MySQL使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作. ...
- PHP快速排序(递归)
日常的排序算法中,快速排序是其中一种.实现起来相对简单. 假设有一个数组,有若干(N)个元素(数字且无序),需要对其进行从小到大的排序. 快速排序的思路是怎么样的呢? 取一个中间值,然后,用其他数组元 ...
- GuidePage底部导航栏
import 'package:flutter/material.dart'; import 'News.dart'; import 'Video.dart'; import 'Chat.dart'; ...
- pip安装第三方库镜像源选择
在pip安装时,有些库速度及其缓慢从而导致失败,可以通过更改镜像源的方式来安装. 我在安装的时候使用了清华的镜像源,格式如下: 想要安装什么库就在后面替换即可.